Decouple virtual networking from the physical world
Isn’t it amazing that we can build the Internet, run the same web-based application on thousands of servers, give millions of people access to cloud services … and stumble badly every time we’re designing virtual networks. No surprise, by trying to keep vSwitches simple (and their R&D and support costs low), the virtualization vendors violate one of the basic scalability principles: complexity belongs to the network edge.
VLAN-based solutions
The simplest possible virtual networking technology (802.1Q-based VLANs) is also the least scalable, because of its tight coupling between the virtual networking (and VMs) and the physical world.
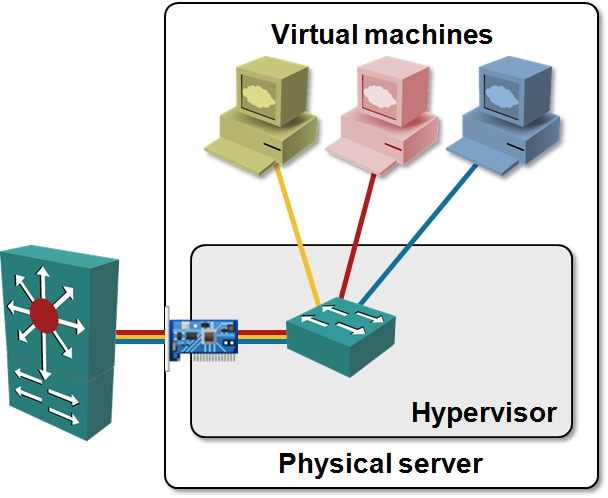
VLAN-based virtual networking uses bridging (which doesn’t scale), 12-bit VLAN tags (limiting you to approximately 4000 virtual segments), and expect all switches to know the MAC addresses of all VMs. You’ll get localized unknown unicast flooding if a ToR switch experiences MAC address table overflow and a massive core flooding if the same thing happens to a core switch.
In its simplest incarnation (every VLAN enabled on every server port on ToR switches), the VLAN-based virtual networking also causes massive flooding proportional to the total number of VMs in the network.
VM-aware networking scales better (depending on the number of VLANs you have and the number of VMs in each VLAN). The core switches still need to know all VM MAC addresses, but at least the dynamic VLAN changes on the server-facing ports limit the amount of flooding on the switch-to-server links; flooding becomes proportional to the number of VLANs active in a particular hypervisor host, and the number of VMs in those VLANs.
Other bridging-based solutions
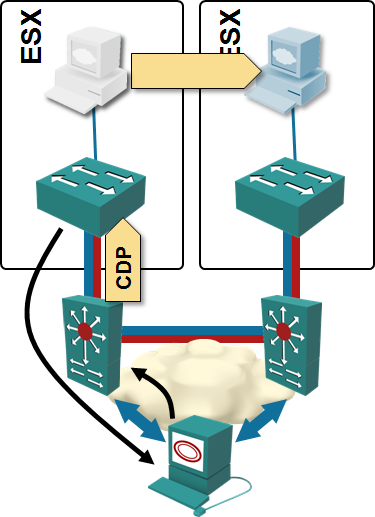
vCDNI is the first solution that decouples at least one of the aspects of the virtual networks from the physical world. It uses MAC-in-MAC encapsulation and thus hides the VM MAC addresses from the network core. vCDNI also removes VLAN limitations, but causes massive flooding due to its suboptimal implementation – the amount of flooding is yet again proportional to the total number of VMs in the vCDNI domain.
Provider Backbone Bridging (PBB) or VPLS implemented in ToR switches fare better. The core network needs to know the MAC addresses (or IP loopbacks) of the ToR switches; all the other virtual networking details are hidden.
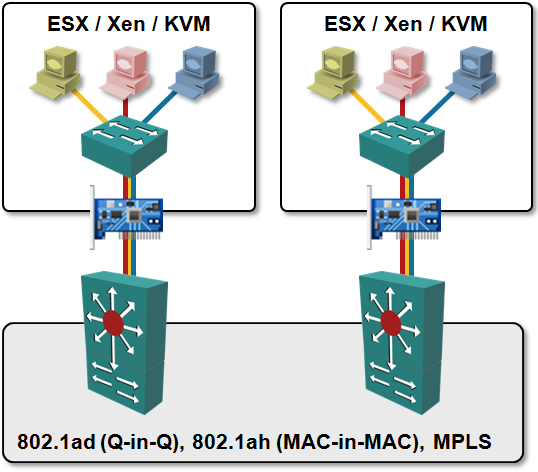
Major showstopper: dynamic provisioning of such a network is a major pain; I’m not aware of any commercial solution that would dynamically create VPLS instances (or PBB SIDs) in ToR switches based on VLAN changes in the hypervisor hosts ... and the dynamic adaptation to VLAN changes is a must if you want the network to scale.
While PBB or VPLS solves the core network address table issues, the MAC address table size in ToR switches cannot be reduced without dynamic VPLS/PBB instance creation. If you configure all VLANs on all ToR switches, the ToR switches have to store the MAC addresses of all VMs in the network (or risk unicast flooding after MAC address table experiences trashing).
MAC-over-IP solutions
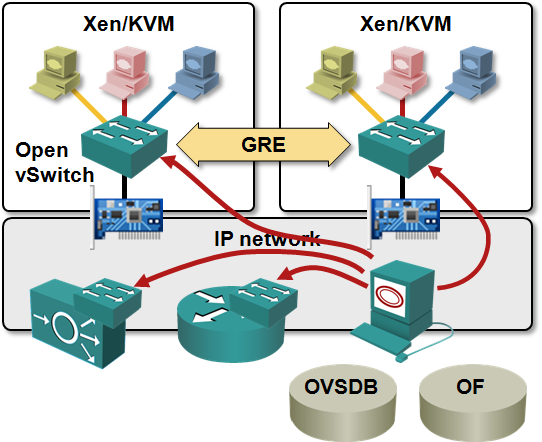
The only proper way to decouple virtual and physical networks is to treat virtual networking like yet another application (like VoIP, iSCSI or any other “infrastructure” application). Virtual switches that can encapsulate L2 or L3 payloads in UDP (VXLAN) or GRE (NVGRE/Open vSwitch) envelopes appear as IP hosts to the network; you can use the time-tested large-scale network design techniques to build truly scalable data center networks.
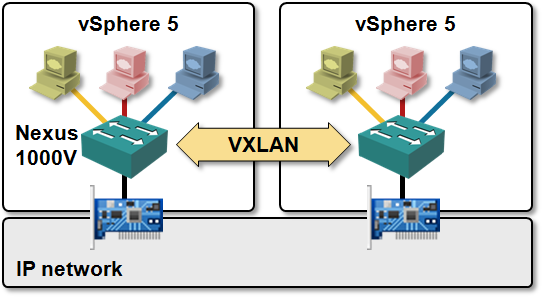
However, MAC-over-IP encapsulation might not bring you to seventh heaven. VXLAN does not have a control plane and thus has to rely on IP multicast to perform flooding of virtual MAC frames. All hypervisor hosts using VXLAN have to join VXLAN-specific IP multicast groups, creating lots of (S,G) and (*,G) entries in the core network. The virtual network data plane is thus fully decoupled from the physical network, the control plane isn’t.
A truly scalable virtual networking solution would require no involvement from the transport IP network. Hypervisor hosts would appear as simple IP hosts to the transport network, and use only unicast IP traffic to exchange virtual network payloads; such a virtual network would use the same transport mechanisms as today’s Internet-based applications and could thus run across huge transport networks. I’m positive Amazon has such a solution, and it seems Nicira’s Network Virtualization Platform is another one (but I’ll believe that when I see it).
More information
All the diagrams in this post were taken from the Cloud Computing Networking – Under the Hood webinar that focuses on virtual networking scalability.
You might also want to check Introduction to Virtual Networking and VMware Networking Deep Dive recordings.
It's true that Virtual Private Cloud lets you bring your own addresses and has more flexibility in assigning them, but even there I don't believe they give you an L2 domain with the usual broadcast/multicast semantics -- it's just a bunch of machines with IPs from the same subnet. They probably use IP-in-IP or IP-in-MPLS to handle it; I strongly doubt ethernet headers get beyond the virtualization host.
Why invent something new and kludgy (like full mesh of hypervisor tunnels), when the most efficient IP-based solution has already been invented and proven in real networks?
Not to mention, Unicast-based flooding will be inherintly less efficient than Multicast-based. Think about it - a hypervisor that needs to flood a frame to 10 other hypervisors needs to send that frame to the IP Core (to Multicast group for that L2 domain) just once.. as opposed to forwarding that frame 10 times via Unicast across 10 tunnels. Multicast was invented for this.
Nexus 7000: 32000 MC entries, 15000 in vPC environment
Nexus 5548: 2000 (verified), 4000 (maximum)
QFabric: No info. OOPS?
Not that much if you want to have an IP MC group per VNI. A blog post coming in early January (it's already on the to-write list).
Though I'm neither an SDN or a virtualisation guy, so this is likely nothing new.