QFabric Part 1 – Hardware Architecture
Juniper has finally released the technical documentation for the QFabric virtual switch and its components (QF/Node, QF/Interconnect and QF/Director). As expected, my speculations weren’t too far off – if anything, Juniper didn’t go far enough along those lines, but we’ll get there later.
The generic hardware architecture of the QFabric switching complex has been well known for quite a while (listening to the Juniper QFabric Packet Pushers Podcast is highly recommended) – here’s a brief summary:
Juniper has finally released the technical documentation for the QFabric virtual switch and its components (QF/Node, QF/Interconnect and QF/Director). As expected, my speculations weren’t too far off – if anything, Juniper didn’t go far enough along those lines, but we’ll get there later.
The generic hardware architecture of the QFabric switching complex has been well known for quite a while (listening to the Juniper QFabric Packet Pushers Podcast is highly recommended) – here’s a brief summary:
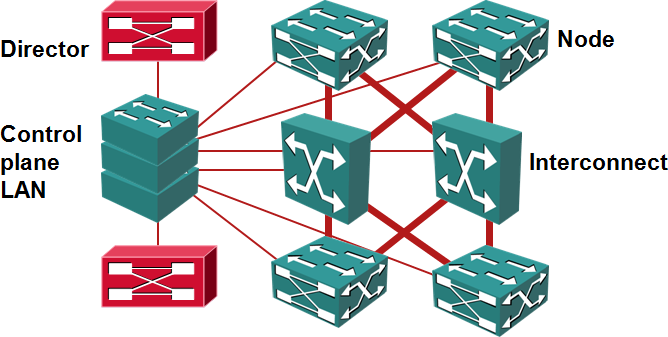
Redundant connections between QFabric elements and control plane stackable switches are not shown in the network diagram. Each QF/Node has two connections to the virtual chassis switches, QF/Interconnect has four (two per control board), QF/Director has six (three per network module).
QF/Directors are x86-based devices that act like the brains for the QFabric, providing fabric services (management, configuration, control, device discovery, DNS, DHCP, NFS) and routing engines for more complex node clusters (network node groups).
Each QFabric should have at least two QF/Directors with disks; you can add diskless QF/Directors (no SKU yet) if you need more processing power (not likely in the current software release).
QF/Interconnects (QFX3008) are very-high-speed totally proprietary switches that forward frames exchanged between QF/Nodes. Each QFX3008 provides up to 10Tbps of non-blocking bandwidth (where non-blocking is defined as “any input port can send a packet to any non-busy output port”) and uses three-stage Clos network to get the non-blocking behavior. With up to four QF/Interconnects per QFabric, the total QFabric switching bandwidth is 40Tbps. Impressive. Try to calculate how many 64 kbps voice calls can fit into that ;)
QF/Nodes are the well-known QFX3500 L2/L3 switches. They support 10GE, 2/4/8Gb FC and up to 4 40GE uplinks to the QF/Interconnect. With 48 10GE ports, you get 1:3 oversubscription if you use all four uplinks or 1:6 oversubscription if you decide to use only two uplinks (using only one uplink probably doesn’t make much sense).
QFabric uses out-of-band Control plane LAN implemented with two stacks of EX4200 switches. Each QFabric component has redundant connections to the control-plane LAN (QF/Node has one connection to each Virtual Chassis, QF/Interconnect has two, QF/Director three). All control-plane traffic is exchanged on the control-plane LAN (already getting ATM/SDH/MPLS-TP flashbacks?), nicely isolating it from the user traffic. The QF/Director has separate management and control plane ports, making the control plane LAN totally isolated.
1-tier? Really? Looking at the QFabric architecture, one has to wonder why Juniper claims it’s a 1-tier architecture. Honestly, it’s as much 1-tier as every MPLS/VPN network I’ve ever seen. However, like with MPLS/VPN, there’s a trick – QFabric uses single-lookup forwarding.
The ingress QF/Node performs full L2/L3 lookup (including ACL checks) and decides how to forward the packet to the egress QF/Node. The QF/Interconnect uses the proprietary frame forwarding information to get the user data to the egress QF/Node. The frame forwarding information likely includes enough details to allow the egress QF/Node to forward the frame to the output port.
The expensive part of the user frame/packet lookup is thus performed only once (whereas you’d get three full lookups in a traditional data center design using similar hardware architecture). Net result: 5 microsecond forwarding latency across the fabric. Not bad, considering that the QF/Interconnect itself has three hops.
Summary
Once you get over the totally proprietary nature of QFabric, the initial commitment you have to make (according to this post, the minimum you’d pay for a single QF/Interconnect with two linecards and two QF/Directors would be around $450.000 ... without optics or a single QF/Node) and the amount of lock-in you’d be exposed to (with all other vendors, you can slowly phase in or out of their fabrics; with QFabric it’s all-or-nothing), QFabric is indeed a masterpiece of engineering.
Due to all the above-mentioned facts, I would expect to see it deployed primarily in very large Greenfield environments; huge Hadoop/MapReduce clusters immediately come to mind.
More information
The Juniper QFabric Packet Pushers Podcast is probably still the best independent source of information on QFabric hardware architecture and its data plane.
I’ll talk about data center fabric architectures and networking requirements for cloud computing at the upcoming EuroNOG conference.
Fabric-like architectures from various vendors are the main focus of the Data Center Fabric Architectures webinar.
You’ll find in-depth discussions of various data center and network virtualization technologies in Data Center 3.0 for Networking Engineers webinar (recording), which is also part of the Data Center Trilogy.
Both webinars (and numerous others) are included in the yearly subscription.
The only mention of the 100m Node-to-Interconnect cable length I found was in the PFC section (you have to stay within 100m if you want lossless transport).
There's a reason distributed architectures have been favored for thirty years.
Actually, the QFabric's control-plane architecture is pretty distributed. More in the next post.
Give me a bunch of 48+ port TOR-style switches connected with a folded-Clos (or fattened butterfly or 3D torus or whatever) topology that can be managed as one, have one unified control plane, and do ECMP across all links at layer 2 and layer 3. Bonus points for some smart adaptive routing that doesn't require global information sharing.
Plug-and-play, scale-out networking. That's revolutionary. QFabric isn't.
Is it just me or does it seem ripe for eventual OpenFlow support? To me it seems that the QF/Director must act in many ways like an OpenFlow Controller.
I agree the cost could be a prohibiting point, but I'm impressed with premise. Maybe some day they will release a scaled down version to gain footing in smaller deployments
See, what you're describing is more than one lookup. That's the beauty of QFabric... it's a single L2 lookup. So its actually a brilliant technology.
As far as cost goes, since the QFX3500 is just a 40x10GigE switch, you can actually deploy them as part of a migration. No need to green field! Interconnects can always be added later.
QFrabric is "brilliant" in the same way the Spruce Goose was brilliant. Impressive engineering, but a solution looking for a problem, and at way too high of a cost.
The cost of a redundant QFabric system is something like $2100 per host-facing 10 GbE port with 3:1 oversubscription for 1920 host-facing ports. A two-stage folded-clos network of the same size, also with 3:1 osub at the edge, would only be about $600 per host-facing port based on current list pricing of 56 * (48-port 10 GbE switch) pricing from other vendors (assuming such switches could someday actually do TRILL or other L2 ECMP).
Arista/Dell/HP: Juniper messed up, and you've got a big opportunity here.
Is your argument that you have to deploy two fabrics for redundancy? We have had a couple of early customers consider that path and elect to go with a single fabric instead. While the fabric behaves like a single switch, it is designed to be as resilient as the network many would like to deploy, but rarely do in practice.
As far as cost goes. We believe there is significant value that goes along with providing applications with the performance they want, infrastructure flexibility rarely found before, and what should be significant operational savings that typically overshadow the capital cost of a network. Time will tell which and to what degree those assumptions are true.
On the size front, there are those who have accused us of building something specifically for large search engines and such and others who say a 6000 port fabric is too small for their needs. We've said we know how to scale the architecture up and down, so don't count us out yet. This game is just getting interesting.
Cheers,
Abner from Juniper
Still I can't understand the "one-lookup" statement. I clearly see that the Edge Node will perform one lookup, decide which way to reach the destination QFabric port, and embed that forwarding information into the proprietary frame format for the Interconnect to use it to send the packet accordingly.
What I see is that, if this assumption is correct, the Interconnect must itself perform another, non-standard lookup in order to read that proprietary forwarding information and switch the frame to the destination node... which I assume will somehow know which port to place it into.
I see one "Ethernet destination MAC address" lookup, and two "proprietary forwarding information header" lookups.
Where am I wrong? I surely must be missing something.
What I don't see then is convergence time information. I understand that for the edge node to attach the proper "tag", it must have visibility of the topology relevant to its connected nodes. Therefore, every topology change (like a VM move) must trigger a FIB update to edge nodes from the QF Directors.
With potentially hundreds of edge nodes... What procedure is used to guarantee timely convergence times for the distribution of this info? What is the target convergence times advertised by JNPR?
As usual, congrats on the post Ivan.
Not that distributed, Ivan, as only first-tier protocols (LACP and such) are distributed. Forwarding information base building is delegated to a single control plane, with no visibility into how this information is propagated, what split-horizon mechanisms are implemented, how its coherence is protected... It's basically a huge black-box with regards to Control Plane.
Plus, it relies upon the stability of a separate out-of-band control network, with its own overlapping control plane...
Talk about stone age, Chris... ;)
One comment on "totally proprietary." To be clear - and I don't want to put words into your mouth - you are referring to the internals of the system that actually create the fabric. Just like a chassis switch system, the internal components are proprietary, while all external facing ports are Ethernet and/or fiber channel. More here: http://j.mp/ov18e2
Our view is that creating a protocol based fabric can get you slightly better efficiency and any to any connectivity than legacy kit, but switch fabrics will deliver much better efficiency, predictability, performance, security, and manageability. We expect those benefits to outweigh the complexity protocol based fabrics will foist on customers. While some have suggested the only way to deploy a QFabric is in a greenfield DC, that would be insane on our part. Early customers are deploying in a corner of the datacenter and expanding from there. I also expect the economics to get more interesting over time.
Cheers,
Abner (Juniper Networks)
However, seems like everyone is moving in the same direction, including Cisco's FEX products and OpenFlow (where although the controller-to-switch communication is standard, the real troubleshooting will have to be done in the guts of the controller, which will be proprietary).
Already looking forward to the NFD2 discussions 8-)
Ivan