Soft Switching Might not Scale, but We Need It
Following a series of soft switching articles written by Nicira engineers (hint: they are using a similar approach as Juniper’s QFabric marketing team), Greg Ferro wrote a scathing Soft Switching Fails at Scale reply.
While I agree with many of his arguments, the sad truth is that with the current state of server infrastructure virtualization we need soft switching regardless of the hardware vendors’ claims about the benefits of 802.1Qbg (EVB/VEPA), 802.1Qbh (port extenders) or VM-FEX.
A virtual switch embedded in a typical hypervisor OS serves two purposes: it does (usually abysmal) layer-2 forwarding and (more importantly) hides the details of the physical hardware from the VM. Virtual machines think they work with a typical Ethernet NIC – usually based on a well-known chipset like Intel’s 82545 controller or AMD Lance controller – or you could use special drivers that allow the VM to interact with the hypervisor more effectively (for example, VMware’s VMXNET driver).
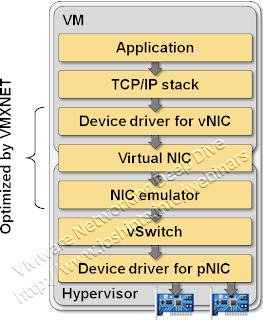
Typical network virtualization stack
In both cases, the details of the physical hardware are hidden from the VM, allowing you to deploy the same VM image on any hypervisor host in your data center (or cloudburst it if you believe in that particular mythical beast), regardless of the host’s physical Ethernet NIC. The hardware abstraction also makes the vMotion process run smoothly – the VM does not need to re-initialize the physical hardware once it’s moved to another physical host. VMware (and probably most other hypervisors) solves the dilemma in a brute force way – it doesn’t allow you to vMotion a VM that’s communicating directly with the hardware using VMDirectPath.
The hardware abstraction functionality is probably way more resource-consuming than the simple L2 forwarding performed by the virtual switches; after all, how hard could it be to do a hash table lookup, token bucket accounting, and switch a few ring pointers?
The virtualized networking hardware also allows the hypervisor host to perform all sorts of memory management tricks. Most modern NICs use packet buffer rings to exchange data between the operating system and the NIC; both parties (NIC and the CPUs) can read or write the ring structures at any time. Allowing a VM to talk directly with the physical hardware effectively locks it into the physical memory, as the hypervisor can no longer control how the VM has set up the NIC hardware and the ring structures; the Ethernet NIC can write into any location belonging to the VM it’s communicating with at any time.
I am positive there are potential technical solutions to all the problems I’ve mentioned, but they are simply not available on any server infrastructure virtualization platform I’m familiar with. The vendors deploying new approaches to virtual networking thus have to rely on a forwarding element embedded in the hypervisor kernel, like the passthrough VEM module Cisco is using in its VM-FEX implementation.
In my opinion, it would make way more sense to develop a technology that tightly integrates hypervisor hosts with the network (EVB/VDP parts of the 802.1Qbg standard) than to try to push a square peg into a round hole using VEPA or VM-FEX, but we all know that’s not going to happen. Hypervisor vendors don’t seem to care and the networking vendors want you to buy more of their gear.
The biggest IaaS clouds in existence all use soft switching (AWS, Rackspace, etc.)
Just Say'n
Having implemented hardware abstraction, it doesn’t cost much to add minimal L2 forwarding functionality (which is the part usually called “soft switching”). More complex soft switching methods (like MAC-over-IP) will be more CPU-expensive, but it’s still the hardware abstraction that consumes most of the CPU resources.
Vendor bias aside (I do belong to one) the reluctance of accepting one/several standards -- e.g SR-IOV VEPA/802.1Qbg or VN-tag/E-tag/802.1Qbh/802.1BR etc (lost track of that...) depending which house colors one currently wears / what cooks ones noodle -- seems to push us back into the vSwitch & dvSwitch nightmares. So, the choice I see is btw letting a hypvervisor dictates a de-facto modus operandi or continue working on interop standards.
I do agree on the need of HW abstraction, but AFAICT current SR-IOV approach does adress that in the adapter (at least in part i.e. the logical division of a physical device into several logical).
So, my question is: What part of current approaches do you consider "square peg / round hole" and what would be the disadvantages of continuing the SR-IOV path ? Or the thought of having e.g. Brocade Trident+ (or similar capable ASICs) as powering (future) "physical interface" adaptors ?
If all vendors could agree on using the same HW interface (for example, AMD LANCE or Intel's 82545), then we would have a fighting change. Not likely though.
And finally there's the cleanup/initialization phase before/after vMotion event. Somewhat hard to do with a generic NIC driver.
Of course you could develop new drivers and try to push them into production environments, but I don't think anyone (but the NIC/switch vendors) is interested.