Don’t Try to Fake Multi-chassis Link Aggregation (MLAG)
Martin sent me an interesting challenge: he needs to connect an HP switch in a blade enclosure to a pair of Catalyst 3500G switches. His Catalysts are not stackable and he needs the full bandwidth between the switches, so he decided to fake the multi-chassis link aggregation functionality by configuring static LAG on the HP switch and disabling STP on it (the Catalysts have no idea they’re talking to the same switch):
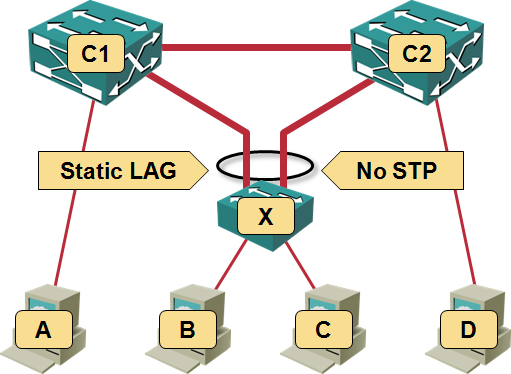
Faking MLAG like a boss
He was already aware of at least two problems (but, as a vendor product manager told me in a recent phone call, "that's nothing that couldn't be solved with a bit of scripting"):
- If one of the links fails, static LAG will not detect link failure and some of the servers connected to the HP switch will lose connectivity to the network.
- If the link between the Catalysts fails, he’ll face a split-brain scenario, as they won’t be able to use the connectivity through the HP switch.
In my opinion that should have been more than enough to run away from this “solution”, as I prefer to sleep during the night and like my network to survive single failures, but it only gets worse:
Forwarding loop following a configuration change. An overworked engineer trying to troubleshoot connectivity problems at 2AM might decide to disable LAG on the HP switch after an inter-switch link failure. The following morning, someone else (unaware of the configuration change) fixes the physical link and the whole network starts glowing in the dark.
Load balancing on the static LAG. If you configure source-MAC-based load balancing on the HP switch (X in my diagram), things just might work (of course we still won’t be able to survive a single link failure). However, if someone figures out a server is overloading its uplink and configures source-destination-MAC-based load balancing or (even worse) per-session load balancing on the LAG, the Catalysts (C1 and C2 in my diagram) will go crazy screaming about flapping MAC addresses (yet again, thanks to all of you who helped me understand this particular problem).
Suboptimal traffic flow. Assuming load balancing in X associates server B is with the X-C1 link, the traffic between D and B will flow over C2, C1 and X due to the way MAC address learning works.
Replicated multicasts. When a host attached to this network sends a broadcast (or multicast or unicast to unknown destination), all the hosts attached to X will receive two copies of the packet. For example, if A sends an ARP request (broadcast), C1 will propagate it to C2 and X and C2 will propagate a second copy to X. B and C will thus receive two copies of the same ARP request.
ARP will obviously work, as it has been designed for lossy unreliable networks. Some fainthearted protocols assuming Ethernet is lossless (I’m looking at you, FCoE) might not be so robust. Figuring out how various server clustering kludges (that rely on layer-2 connectivity between cluster nodes) work in this scenario would also be great fun.
Last but not least, if B sends a broadcast packet, it will receive a copy of its own broadcast propagated through X-C1-C2 (or X-C2-C1).
Anything else? Is there something else that can go wrong? Please let me know in the comments!
More information
Multi-chassis Link Aggregation (MLAG) technologies and data center architectures from Cisco, Juniper and HP are described in my Data Center 3.0 for Networking Engineers webinar.
Can you please clarify something for me?
You say "If one of the links fails, static LAG will not detect link failure". Are you saying that if we don't use LACP or PAGP and instead use 'channel-group 1 mode on', for example, and a link in etherchannel fails, some traffic will be dropped? As in packets are still load balanced over the dead link??
Or is this an HP thing?
"configuring static LAG on the HP switch and disabling STP on it (the Catalysts have no idea they're talking to the same switch)"
*DONT_KNOW*
You forgot to mention Nortel (now Avaya) when you say Chassis Aggregation technologiees. Nortel does SMLT since 2001.