vSwitch in Multi-chassis Link Aggregation (MLAG) environment
Yesterday I described how the lack of LACP support in VMware’s vSwitch and vDS can limit the load balancing options offered by the upstream switches. The situation gets totally out-of-hand when you connect an ESX server with two uplinks to two (or more) switches that are part of a Multi-chassis Link Aggregation (MLAG) cluster.
Let’s expand the small network described in the previous post a bit, adding a second ESX server and another switch. Both ESX servers are connected to both switches (resulting in a fully redundant design) and the switches have been configured as a MLAG cluster. Link aggregation is not used between the physical switches and ESX servers due to lack of LACP support in ESX.
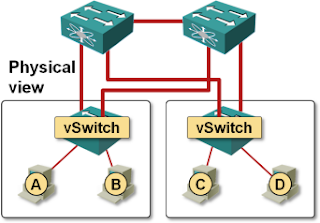
Two ESXi hosts connected to two ToR switches
The physical switches are unaware of the physical connectivity the ESX servers have. Assuming that vSwitches use per-VM load balancing and each VM is pinned to one of the uplinks, source MAC address learning in the physical switches produces the following logical topology:
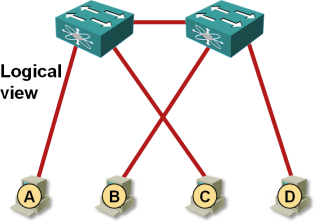
Each ESXi hosts looks like multiple single-attached servers
Each VM appears to be single-homed to one of the switches. The traffic between VM A and VM C is thus forwarded locally by the left-hand switch; the traffic between VM A and VM D has to traverse the inter-switch link because neither switch knows VM D can also be reached by a shorter path1.
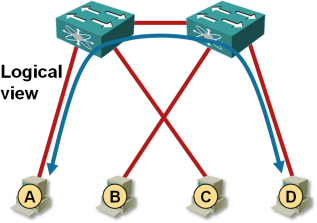
End-to-end traffic flow is suboptimal
When you use servers connected to a pair of edge switches2 and use all uplinks for VM traffic, you risk overloading the inter-switch link as the traffic between adjacent ESX servers is needlessly sent across that link. There are at least two solutions to this challenge:
- Use Multi-chassis Link Aggregation (MLAG) and combine server uplinks into a link aggregation group. Don’t even think about using static port channels, LACP is your only protection against wiring mistakes3. When using this approach, it’s probably best to configure IP-hash-based load balancing in vSwitch.
- Use active/standby failover policy and dedicate each server uplink to a subset of traffic. For example, use the left-hand uplink for VM and vMotion traffic, and the right-hand uplink for storage (iSCSI/NFS) traffic.
More information
Interaction of vSwitch with link aggregation is just one of many LAG-related topics covered in the Data Center 3.0 for Networking Engineers webinar.
For even more details, watch the vSphere 6 Networking Deep Dive and Designing Private Cloud Infrastructure webinars.
Revision History
- 2022-05-08
- Removed Cisco Nexus 1000v references, and added active/standby scenario
-
And even if the elf ToR switch would send the traffic toward VM D on the direct link, ESXi would drop it due to its built-in “we don’t need no STP” loop prevention logic. ↩︎
-
And who doesn’t – most of us can’t afford to lose access to dozens of servers after a switch failure. ↩︎
-
And yes, I know VMware charges you extra (enterprise license) for the privilege of having a working LACP implementation on ESXi hosts. ↩︎
Is this a workable scenario?
If I understand correctly, you're saying that we've got two static MLAGs configured: one to each ESX host.
Your second drawing appears to show MAC addresses being learned on *physical*ethernet*ports*, rather than the logical aggregate interfaces.
Assuming the static aggregations are Po1 (left ESX) and Po2 (right ESX), then the resulting MAC->port mapping on *both* pSwitches should be:
A -> Po1
B -> Po1
C -> Po2
D -> Po2
...Because MACs don't get learned on link members of an aggregation.
A frame from A to C will be okay, because it's path is:
- ingress left pSwitch on Po1
- egress left pSwitch on Po2
- ingress right ESX on the *correct* pNIC
A frame from A to D will fail, because its path is:
- ingress left pSwitch on Po1
- egress left pSwitch on Po2
- ingress right ESX on the *wrong* pNIC.
A->D frames will ingress the ESX host on the pNIC that's pinned to vm C. I expect that the vSwitch split horizon bridging will drop this frame. Maybe it doesn't?
And since you HAVE TO HAVE static LAGs, you also need IP-hash-based load balancing in ESX, otherwise the incoming frames arriving through the wrong port will get dropped.
Certainly ESX hash-based and static LAG *must* go together. There's no disagreement there.
But I disagree with "Each VM appears to be single-homed to one of the switches."
From the pSwitch perspective, each VM is homed to an *aggregation*, and MAC learning will happen on the aggregation, regardless of the link member where they arrive.
Taking just the left pSwitch, all of A's frames will arrive on link member 0 and all of C's frames will arrive on link member 1... But the pSwitch won't notice this. The pSwitch will associate both MACs with the aggregate interface, and will forward downstream frames according to whichever hashing method is configured, totally ignoring which MAC showed up on which link member.
Traffic won't flow across the inter-switch link. It will flow *down* the aggregate, and only *maybe* get delivered to the VMs.
Ah! Okay, I'd missed the "aggregation is not used" sentence until just now. Looking back at your previous comment, I guess this is the part that got clarified (after my misunderstanding of the topology was firmly cemented in my brain)
The extra east-west hop would be nice to avoid.