MLAG and Load Balancing
FullMesh added an excellent comment to my Multi-Chassis Link Aggregation (MLAG) and hot potato switching post. He wrote:
If there are two core routing switches and two access switches which are MLAGged together in both directions, and hosts that are dual-active LAGged to the pair of access switches, then the traffic would stay on whichever side the host places it.
He also opened another can of worms: load balancing in MLAG environment is dictated by the end hosts. It doesn’t pay to have fancy switches that support L3 or L4 load balancing; a stupid host implementing destination-MAC-address-based load balancing can easily ruin your day.
Let’s start with simple baseline architecture: two web servers and a router connected to a switch. Majority of the traffic flows from the web servers through the router to outside users.
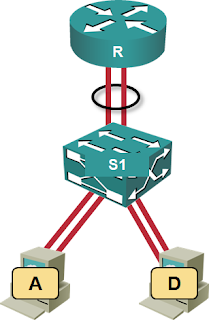
In this architecture, the switch can reshuffle the packets based on its load balancing algorithm regardless of the load balancing algorithm used by the servers. Even if the servers use source-destination-MAC algorithm (which would send all the traffic over a single link), the switch can spread packets sent to different destination IP addresses1 over both links toward the router. As long as the links between the servers and the switch aren’t congested, we don’t really care about the quality of the load balancing algorithm the servers use.
Now let’s make the architecture redundant, introducing a second switch and combining the two switches into a multi-chassis link aggregation group:
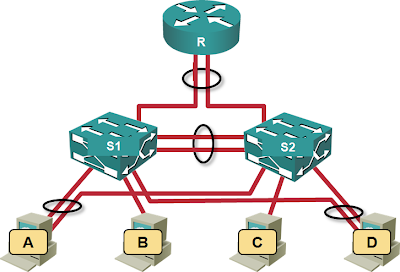
Redundant architecture using an MLAG cluster
All of a sudden, the switches (using hot potato switching) can no longer influence the traffic flow toward the router. If all the hosts decide to send their outgoing traffic toward S1, the link S1-R will be saturated even though the link S2-R will remain idle. The quality of the servers’ load balancing algorithm becomes vital.
Finally, let’s add two more links between the switches and the router:
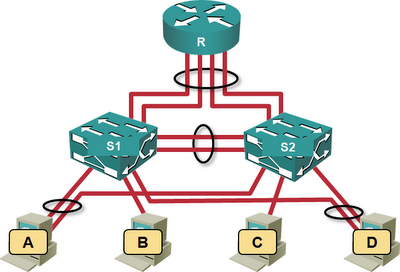
More is not always better
In this architecture, each switch can use its own load balancing algorithm on the directly connected links: if all the hosts decide to send outbound traffic to S1, S1 can still load-balance the traffic according to its own rules on the parallel links between S1 and R. Of course it still cannot shift any of the traffic toward S2.
More information
- Multi-chassis Link Aggregation (and numerous other LAN, SAN and virtualization technologies) is described in the Data Center 3.0 for Networking Engineers webinar (buy a recording or yearly subscription).
- Read my posts about Multi-chassis Link Aggregation basics, Stacking on Steroids and External Brains architectures.
- The load balancing issues described in this article are caused by the hot potato switching.
-
Or even packets from different TCP/UDP sessions sent to the same destination if you configured 5-tuple load balancing. ↩︎
First; Open discloure. I am an HP Networking Employee.
Great posts on the issues surrounding MLAG. I think that better hashing algos can combat some of the issues you bring up, but I also think there's a application that we are forgettign to address at all. MLAG can ALSO be useful in LAN enterprise ( not data center ) networks to gain the same benefits.
I would argue in a typical LAN, many of the issues you're bringing up are not going to be such an issue. In a LAN, I would feel that the true advantage of using MLAGG is not necessarily added capacity, but actually the benefit of a non-converging topology. Because MLAGG allows you to create logically loop-free topologies ( whether they use IRF/VSS/Virtual Chassis or other ), the issues caused in large networks by spanning-tree convergence are largely negated. Since there is no "loop" in the network, spanning tree becomes a purely protectionist mechnism.
What are your thoughts on MLAGG in a LAN enterprise as opposed to a data center? I'm not saying the techonlogy is 100%, but I do believe it's a heck of a lot better than the typical STP based networks that we're using today.
thoughts?
Chris
1. Most OS support multiple levels of hashing. SourceIP+DestIP I believe is available on most major operating systems.
2. Law of large numbers -- with a good hashing algorithm, the more hosts you have in the network, the more balanced your transit links should become. This is assuming that your network isn't comprised of identically configured and behaving clones.
3. What's the goal,.. network availability or bandwidth? My primary goal is end-to-end (host-to-host) high-availability, but the extra bandwidth is a nice bonus which I am careful not to sell. On a side note in regards to high availability, LACP is available on all major operating systems and, I can truly say, has finally come of age on the host side.
4. Good plumbing is critical to avoiding transit congestion.
To extend your topology above, I would add an additional router (L3 switch) such that the two routers appear to the access switches below as one switch (using MCLAG obviously) and to the IP (or IP/MPLS) network above as two routers. The access switch pair appears to the two routers above as one switch (using MCLAG obviously). Active-active VRRP is either available now (on N7K) or soon to be available on some routers (which I can't say yet) to ensure the interconnect between the routers won't take a hit in this topology.
#1 - while most OS support IP-based hashing, it's rarely enabled by default. The administrators have to be aware of the consequences (and the need to enable it).
#2 - absolutely agree ... if you use IP-based hashing. With MAC-based hashing, you're toast if most of the traffic goes beyond the first-hop router.
#3 - LACP is not available in VMware ESX(i) unless you use NX1K.