Category: IS-IS
Lab: Summarizing IS-IS Level-1 Routes
IS-IS was designed to carry node addresses (NSAPs) between level-1 routers (called Intermediate Systems) within an area and area prefixes between level-2 routers, resulting in a perfect separation of concerns and forwarding information summarization. When IETF tried to use the same routing protocol for a networking stack with a completely different addressing mentality, something had to give.
Lab: Build an SR-MPLS Network with IS-IS
Want to spend an hour or two configuring some cool stuff this weekend? How about getting SR-MPLS to work with IS-IS and building a BGP-free core with it?

If you already set up your own netlab environment, you probably know what to do (or you can get the details here). Alternatively, you can click here to start the lab in your browser using GitHub Codespaces. After starting the lab environment, change the directory to advanced/10-sr and execute netlab up.
Lab: Distributing Level-2 IS-IS Routes into Level-1 Areas
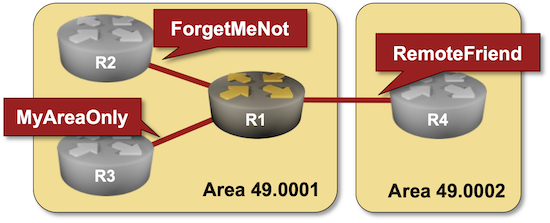
One of the major differences between OSPF and IS-IS is their handling of inter-area routes. Non-backbone OSPF intra-area routes are copied into the backbone area and later (after the backbone SPF run) copied into other areas. IS-IS does not copy level-2 routes into level-1 areas; level-1 areas (by default) behave like totally stubby OSPF areas with the level-1 routers using the Attached (ATT) bit of level-1-2 routers in the same area to generate the default route.
Do You Need IS-IS Areas?
TL&DR: Most probably not, but if you do, you’d better not rely on random blogs for professional advice #justSaying 😜
Here’s an interesting question I got from a reader in the midst of an OSPF-to-IS-IS migration:
Why should one bother with different [IS-IS] areas when the routing hierarchy is induced by the two levels and the appropriate IS-IS circuit types on the links between the routers?
Well, if you think you need a routing hierarchy, you’re bound to use IS-IS areas because that’s how the routing hierarchy is implemented in IS-IS. However…
Lab: Multilevel IS-IS Deployments
Like OSPF, IS-IS was designed when router memory was measured in megabytes and clock speeds in megahertz. Not surprisingly, it includes a scalability mechanism similar to OSPF areas. An IS-IS router could be a level-1 router (having in-area prefixes and a default route), a level-2 router (knowing just inter-area prefixes), or a level-1-2 router (equivalent to OSPF ABR).
Even though multilevel IS-IS is rarely used today, it always makes sense to understand how things work, and the Multilevel IS-IS Deployments lab exercise created by Dan Partelly gives you a perfect starting point.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to advanced/1-multilevel and execute netlab up.
Lab: IS-IS Route Redistribution
Route redistribution into IS-IS seems even easier than its OSPFv2/OSPFv3 counterparts. There are no additional LSAs/LSPs; the redistributed prefixes are included in the router LSP. Things get much more interesting once you start looking into the gory details and exploring how different implementations use (or do not) the various metric bits and TLVs.
You’ll find more details (and the opportunity to explore the LSP database contents in a safe environment) in the IS-IS Route Redistribution lab exercise.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/7-redistribute and execute netlab up.
Lab: Adjust IS-IS Timers
Like any other routing protocol, IS-IS has several timers you can tweak to improve the convergence speed of your network, or make your network unstable (eventually breaking it completely) if you reduce them too much (if you care about fast convergence, you REALLY SHOULD use BFD).
You’ll find more details (and the opportunity to tweak the timers in a safe environment) in the Adjust IS-IS Timers lab exercise.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/6-timers and execute netlab up.
Lab: Drain Traffic From an IS-IS Node Before Starting Maintenance
Here’s a cool feature every routing protocol should have: a flag that tells everyone a node is going down, giving them time to adjust their routing tables before disrupting traffic flow.
OSPF never had such a feature; common implementations set the cost of all interfaces to a very high value to emulate it. BGP got it (the Graceful BGP Session Shutdown) almost 30 years after it was created. IS-IS had the overload bit from day one, and it’s just what an IS-IS router needs to tell everyone else they should stop using it for transit traffic. You can try it out in the Drain Traffic Before Node Maintenance lab exercise.
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/5-drain and execute netlab up.
Lab: Hide Transit Subnets in IS-IS Networks
Sometimes you want to assign IPv4/IPv6 subnets to transit links in your network (for example, to identify interfaces in traceroute outputs), but don’t need to have those subnets in the IP routing tables throughout the whole network. Like OSPF, IS-IS has a nerd knob you can use to exclude transit subnets from the router PDUs.
Want to check how that feature works with your favorite device? Use the Hide Transit Subnets in IS-IS Networks lab exercise.
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/4-hide-transit and execute netlab up.
Lab: Protect IS-IS Routing Data with MD5 Authentication
Like OSPF and BGP, IS-IS contains a simple mechanism to authenticate routing traffic – IS-IS packets can include a cleartext password or an MD5- or SHA hash. Unlike OSPF, IS-IS can also authenticate:
- The hello packets exchanged between routers
- The contents of Link State PDUs flooded across an area or a domain.
Want to know more? Check out the Protect IS-IS Routing Data with MD5 Authentication lab exercise.
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to feature/3-md5 and execute netlab up.
Lab: Running IS-IS over IPv4 Unnumbered and IPv6 LLA Interfaces
IS-IS does not use IPv4 or IPv6, so it should be a no-brainer to run it over IPv4 unnumbered or IPv6 LLA interfaces. The latter is true; the former is smack in the middle of the It Depends™ territory.
Want to know more or test the devices you’re usually working with? The Running IS-IS Over Unnumbered/LLA-only Interfaces lab exercise is just what you need.

Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to basic/7-unnumbered and execute netlab up.
IS-IS 3-Way Handshake and the Power of SHOULD
Yesterday, I mentioned that a Cisco router running pre-standard IS-IS 3-way handshake (this is why you need it) interoperates with multiple implementations of RFC 5303. How’s that possible, and does it matter whether you configure the ancient Cisco routers (release 15.x) to use IETF 3-way handshake instead of the “proprietary” one?
I took a trip to the Wireshark land to figure out the details (you can download the capture file):
Lab: IS-IS Designated Router Election
Like OSPF, IS-IS needs a router to originate the pseudo-node for a LAN segment. IS-IS standards call that router a Designated Intermediate System (DIS), and since it is not responsible for flooding, it does not need a backup.
Want to know more? The Influence the Designated IS Election lab exercise provides the details (and some hands-on work).
Lab: Passive IS-IS Interfaces
The initial IS-IS labs covered the IS-IS basics. It’s time to move on to interesting IS-IS features (and why you might want to use them), starting with passive IS-IS interfaces.

Lab: Level-1 and Level-2 IS-IS Routing
One of the recipes for easy IS-IS deployments claims that you should use only level-2 routing (although most vendors enable level-1 and level-2 routing by default).
What does that mean, and why does it matter? You’ll find the answers in the Optimize Simple IS-IS Deployments lab exercise.