Category: IP routing
… updated on Tuesday, August 13, 2024 07:26 +0200
Back to Basics: The History of IP Interface Addresses
In the previous blog post in this series, we figured out that you might not need link-layer addresses on point-to-point links. We also started exploring whether you need network-layer addresses on individual interfaces but didn’t get very far. We’ll fix that today and discover the secrets behind IP address-per-interface design.
In the early days of computer networking, there were three common addressing paradigms:
Video: IP Routing Fundamentals
A few weeks ago we covered transparent bridging fundamentals, now it’s time to recap IP routing fundamentals… and then we’ll be ready to compare the two.
Back to Basics: Do We Need Interface Addresses?
In the world of ubiquitous Ethernet and IP, it’s common to think that one needs addresses in packet headers in every layer of the protocol stack. We have MAC addresses, IP addresses, and TCP/UDP port numbers… and low-level addresses are assigned to individual interfaces, not nodes.
Turns out that’s just one option… and not exactly the best one in many scenarios. You could have interfaces with no addresses, and you could have addresses associated with nodes, not interfaces.
… updated on Tuesday, February 15, 2022 15:00 UTC
Building Unnumbered Ethernet Lab with netlab
Last week I described the new features added to netsim-tools release 0.4, including support for unnumbered interfaces and OSPF routing. Now let’s see how I used them to build a multi-vendor lab to test which platforms could be made to interoperate when running OSPF over unnumbered Ethernet interfaces.
- This blog post has been updated to use the new netlab CLI introduced in netsim-tools release 0.8 and new IPAM features introduced in release 1.0
- netsim-tools project has been renamed to netlab.
Unequal-Cost Multipath in Link State Protocols
TL&DR: You get unequal-cost multipath for free with distance-vector routing protocols. Implementing it in link state routing protocols is an order of magnitude more CPU-consuming.
Continuing our exploration of the Unequal-Cost Multipath world, why was it implemented in EIGRP decades ago, but not in OSPF or IS-IS?
Ignoring for the moment the “does it make sense” dilemma: finding downstream paths (paths strictly shorter than the current best path) is a side effect of running distance vector algorithms.
Video: Path Discovery in Transparent Bridging and Routing
In the previous video in this series, I described how path discovery works in source routing and virtual circuit environments. I couldn’t squeeze the discussion of hop-by-hop forwarding into the same video (it would make the video way too long); you’ll find it in the next video in the same section.
… updated on Friday, March 5, 2021 16:22 UTC
Chasing Anycast IP Addresses
One of my readers sent me this question:
My job required me to determine if one IP address is unicast or anycast. Is it possible to get this information from the bgp dump?
TL&DR: Not with anything close to 100% reliability. An academic research paper (HT: Andrea di Donato) documents a false-positive rate of around 10%.
If you’re not familiar with IP anycast: it’s a brilliant idea of advertising the same prefix from multiple independent locations, or the same IP address from multiple servers. Works like a charm for UDP (that’s how all root DNS servers are built) and supposedly pretty well across distant-enough locations for TCP (with a long list of caveats when used within a data center).
Does Unequal-Cost Multipathing Make Sense?
Every now and then I’m getting questions along the lines “why doesn’t X support unequal-cost multipathing (UCMP)?” for X in [ OSPF, BGP, IS-IS ].
To set the record straight: BGP does support some rudimentary form of unequal-cost multipathing with the DMZ Bandwidth community, but it only works across multiple egress points from a single autonomous system. Follow-up nerd knobs described how to use the same community over EBGP sessions; not sure whether anyone implemented that part (comments welcome).
Virtual Networks and Subnets in AWS, Azure, and GCP
Now that we know what regions and availability zones are, let’s go back to Daniel Dib’s question:
As I understand it, subnets in Azure span availability zones. Do you see any drawback to this? Does subnet matter if your VMs are in different AZs?
Wait, what? A subnet is stretched across multiple failure domains? Didn’t Ivan claim that’s ridiculous?
TL&DR: What I claimed was that a single layer-2 network is a single failure domain. Things are a bit more complex in public clouds. Keep reading and you’ll find out why.
Video: Finding Paths Across the Network
Regardless of the technology used to get packets across the network, someone has to know how to get from sender to receiver(s), and as always, you have multiple options:
- Almighty controller
- On-demand dynamic path discovery (example: probing)
- Participation in a routing protocol
For more details, watch Finding Paths Across the Network video.
FreeRTR Deep Dive on Software Gone Wild
This podcast introduction was written by Nick Buraglio, the host of today’s podcast.
In today’s evolving landscape of whitebox, brightbox, and software routing, a small but incredibly comprehensive routing platform called FreeRTR has quietly been evolving out of a research and education service provider network in Hungary.
Kevin Myers of IPArchitechs brought this to my attention around March of 2019, at which point I went straight to work with it to see how far it could be pushed.
Reviving Old Content, Part 3
We had the usual gloomy December weather during the end-of-year holidays, and together with the partial lockdown (with confusing ever-changing rules only someone in Balkans could dream up) it managed to put me in OCD mood… and so I decided to remove broken links from the old blog posts.
While doing that I figured out how fragile our industry is – I encountered a graveyard of ideas and products that would make Google proud. Some of those blog posts were removed, I left others intact because they still have some technical merits, and I made sure to write sarcastic update notices on product-focused ones. Consider those comments Easter eggs… now go and find them ;))
What Exactly Happens after a Link Failure?
Imagine the following network running OSPF as the routing protocol. PE1–P1–PE2 is the primary path and PE1–P2–PE2 is the backup path. What happens on PE1 when the PE1–P1 link fails? What happens on PE2?
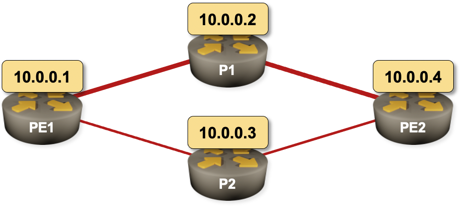
Sample 4-router network with a primary and a backup path
The second question is much easier to answer, and the answer is totally unambiguous as it only involves OSPF:
Fast Failover: Techniques and Technologies
Continuing our Fast Failover saga, let’s focus on techniques and technologies available to implement it (assuming you still think it’s worth the effort).
There are numerous technologies you can use to implement fast reroute, from the most complex to the easiest one:
Fast Failover: Hardware and Software Implementations
In previous blog posts in this series we discussed whether it makes sense to invest into fast failover network designs, the topologies you can use in such designs, and the fault detection techniques. I also hinted at different fast failover implementations; this blog post focuses on some of them.
Hardware-based failover changes the hardware forwarding tables after a hardware-detectable link failure, most likely loss-of-light or transceiver-reported link fault. Forwarding hardware cannot do extensive calculations; the alternate paths are thus usually pre-programmed (more details below).