Category: Bridging
Use VRFs for VXLAN-Enabled VLANs
I started one of my VXLAN tests with a simple setup – two switches connecting two hosts over a VXLAN-enabled (gray tunnel) red VLAN. The switches are connected with a single blue link.
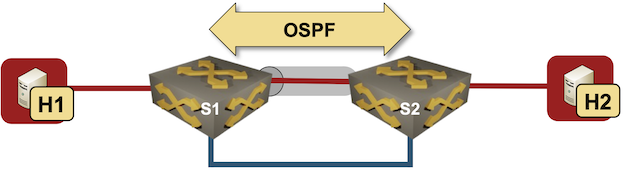
Test lab
I configured VLANs and VXLANs, and started OSPF on S1 and S2 to get connectivity between their loopback interfaces. Here’s the configuration of one of the Arista cEOS switches:
EVPN VLAN-Aware Bundle Service
In the EVPN/MPLS Bridging Forwarding Model blog post I mentioned numerous services defined in RFC 7432. That blog post focused on VLAN-Based Service Interface that mirrors the Carrier Ethernet VLAN mode.
RFC 7432 defines two other VLAN services that can be used to implement Carrier Ethernet services:
- Port-based service – whatever is received on the ingress port is sent to the egress port(s)
- VLAN bundle service – multiple VLANs sharing the same bridging table, effectively emulating single outer VLAN in Q-in-Q bridging.
And then there’s the VLAN-Aware Bundle Service, where a bunch of VLANs share the same MPLS pseudowires while having separate bridging tables.
Duplicate ARP Replies with Anycast Gateways
A reader sent me the following intriguing question:
I’m trying to understand the ARP behavior with SVI interface configured with anycast gateways of leaf switches, and with distributed anycast gateways configured across the leaf nodes in VXLAN scenario.
Without going into too many details, the core dilemma is: will the ARP request get flooded, and will we get multiple ARP replies. As always, the correct answer is “it depends” 🤷♂️
MUST READ: ARP Problems in EVPN
Decades ago there was a trick question on the CCIE exam exploring the intricate relationships between MAC and ARP table. I always understood the explanation for about 10 minutes and then I was back to I knew why that’s true, but now I lost it.
Fast forward 20 years, and we’re still seeing the same challenges, this time in EVPN networks using in-subnet proxy ARP. For more details, read the excellent ARP problems in EVPN article by Dmytro Shypovalov (I understood the problem after reading the article, and now it’s all a blur 🤷♂️).
Video: Typical Large-Scale Bridging Use Cases
In the previous video in the Switching, Routing and Bridging section of How Networks Really Work webinar we compared transparent bridging with IP routing. Not surprisingly (given my well-known bias toward stable solutions) I recommended using IP routing as much as possible, but there are still people out there pushing large-scale transparent bridging solutions.
In today’s video we’ll look at some of the supposed use cases and stable solutions you could use instead of stretching a virtual thick yellow cable halfway across a continent.
Comparing EVPN with Flood-and-Learn Fabrics
One of ipSpace.net subscribers sent me this question after watching the EVPN Technical Deep Dive webinar:
Do you have a writeup that compares and contrasts the hardware resource utilization when one uses flood-and-learn or BGP EVPN in a leaf-and-spine network?
I don’t… so let’s fix that omission. In this blog post we’ll focus on pure layer-2 forwarding (aka bridging), a follow-up blog post will describe the implications of adding EVPN IP functionality.
Video: Comparing Routing and Bridging
After covering the basics of transparent Ethernet bridging and IP routing, we’re finally ready to compare the two. Enjoy the ride ;)
Packet Forwarding and Routing over Unnumbered Interfaces
In the previous blog posts in this series, we explored whether we need addresses on point-to-point links (TL&DR: no), whether it’s better to have interface or node addresses (TL&DR: it depends), and why we got unnumbered IPv4 interfaces. Now let’s see how IP routing works over unnumbered interfaces.
The Challenge
A cursory look at an IP routing table (or at CCNA-level materials) tells you that the IP routing table contains prefixes and next hops, and that the next hops are IP addresses. How should that work over unnumbered interfaces, and what should we use for the next-hop IP address in that case?
… updated on Tuesday, August 13, 2024 07:26 +0200
Back to Basics: The History of IP Interface Addresses
In the previous blog post in this series, we figured out that you might not need link-layer addresses on point-to-point links. We also started exploring whether you need network-layer addresses on individual interfaces but didn’t get very far. We’ll fix that today and discover the secrets behind IP address-per-interface design.
In the early days of computer networking, there were three common addressing paradigms:
Back to Basics: Do We Need Interface Addresses?
In the world of ubiquitous Ethernet and IP, it’s common to think that one needs addresses in packet headers in every layer of the protocol stack. We have MAC addresses, IP addresses, and TCP/UDP port numbers… and low-level addresses are assigned to individual interfaces, not nodes.
Turns out that’s just one option… and not exactly the best one in many scenarios. You could have interfaces with no addresses, and you could have addresses associated with nodes, not interfaces.