Video: Rogue IPv6 RA Challenges
IPv6 security-focused presentations were usually an awesome opportunity to lean back and enjoy another round of whack-a-mole, often starting with an attacker using IPv6 Router Advertisements to divert traffic (see also: getting bored at Brussels airport) .
Rogue IPv6 RA challenges and the corresponding countermeasures are thus a mandatory part of any IPv6 security training, and Christopher Werny did a great job describing them in IPv6 security webinar.
Using Custom Vagrant Boxes with netlab
A friend of mine started using Vagrant with libvirt years ago (it was his enthusiasm that piqued my interest in this particular setup, eventually resulting in netlab). Not surprisingly, he’s built Vagrant boxes for any device he ever encountered, created quite a collection that way, and would like to use them with netlab.
While I didn’t think about this particular use case when programming the netlab virtualization provider interface, I decided very early on that:
- Everything worth changing will be specified in the system defaults
- You will be able to change system defaults in topology file or user defaults.
Select the Best Switching ASIC For the Job
Last week I described some of the data center switching ASIC design tradeoffs and the ASIC families Broadcom created to fit somewhere in that multi-dimensional space.
Next step: how could you design your data center fabric to make the most out of them? To keep things simple, we’ll build a typical leaf-and-spine fabric with a WAN edge layer (sometimes called border leaf switches).
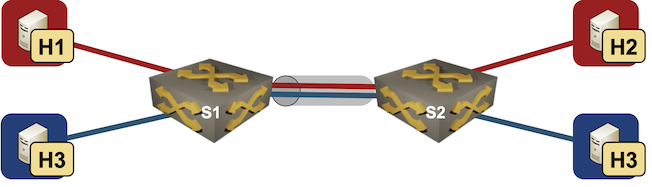
MLAG Deep Dive: Dynamic MAC Learning
In the first blog post of the MLAG Technology Deep Dive series, we explored the components of an MLAG system and the fundamental control plane requirements.
This post focuses on a major building block of the layer-2 data plane functionality: MAC learning. We’ll keep using the same network topology with two switches and five hosts, and assume our system tries its best to implement hot-potato switching (sending the frames toward the destination MAC address on the shortest possible path).
netlab VLAN Trunk Example
Last week I described how easy it is to use access VLANs in netlab. Next step: VLAN trunks.
We’ll add two Linux hosts to the lab topology used in the previous blog post, resulting in two switches, two Linux hosts in red VLAN and two Linux hosts in blue VLAN.
Lab topology
Video: Network Address Scopes
When defining network addresses in IEN 19 John Shoch said:
Addresses must, therefore, be meaningful throughout the domain, and must be drawn from some uniform address space.
But what is a domain? Welcome to the address scope discussion ;)
Data Center Switching ASICs Tradeoffs
A brief mention of Broadcom ASIC families in the Networking Hardware/Software Disaggregation in 2022 blog post triggered an interesting discussion of ASIC features and where one should use different ASIC families.
Like so many things in life, ASIC design is all about tradeoffs. Usually you’re faced with a decision to either implement X (whatever X happens to be), or have high-performance product, or have a reasonably-priced product. It’s very hard to get two out of three, and getting all three is beyond Mission Impossible.
MLAG Deep Dive: System Overview
Multi-Chassis Link Aggregation (MLAG) – the ability to terminate a Port Channel/Link Aggregation Group on multiple switches – is one of the more convoluted1 bridging technologies2. After all, it’s not trivial to persuade two boxes to behave like one and handle the myriad corner cases correctly.
In this series of deep dive blog posts, we’ll explore the intricacies of MLAG, starting with the data plane considerations and the control plane requirements resulting from the data plane quirks. If you wonder why we need all that complexity, remember that Ethernet networks still try to emulate the ancient thick yellow cable that could lose some packets but could never reorder packets or deliver duplicate packets.
VXLAN-Focused Design Clinic in June 2022
ipSpace.net subscribers are probably already familiar with the Design Clinic: a monthly Zoom call in which we discuss real-life design- and technology challenges. I started it in September 2021 and it quickly became reasonably successful; we covered almost two dozen topics so far.
Most of the challenges contributed for the June 2022 session were focused on VXLAN use cases (quite fitting considering I just updated the VXLAN Technical Deep Dive webinar), including:
- Can we implement Data Center Interconnect (DCI) with VXLAN? (Yes, but…)
- Can we run VXLAN over SD-WAN (and does it make sense)? (Yes/No)
- What happened to traditional MPLS/VPN Enterprise core and can we use VXLAN/EVPN instead? (Still there/Maybe)
- Should we use routers or switches as data center WAN edge devices, and how do we integrate them with VXLAN/EVPN data center fabric? (Yes 😊)
For more details, join us on June 6th. There’s just a minor gotcha: you have to be an active ipSpace.net subscriber to do it.
netlab Simple VLAN Example
I had no idea how convoluted VLANs could get until I tried to implement them in netlab.
We’ll start with the simplest option: a single VLAN stretched across two bridges switches with two Linux hosts connected to it. netlab can configure VLANs on Arista EOS, Cisco IOSv, Cisco Nexus OS, VyOS, Dell OS10, and Nokia SR Linux. We’ll use the quickest (deployment-wise) option: Arista EOS on containerlab.

Simple VLAN topology
Worth Reading: ACI Terraform Scalability
Using Terraform to deploy networking elements with an SDN controller that cannot replace the current state of a tenant with the desired state specified in a text file (because nobody ever wants to do that, right) sounds like a great idea… until you try to do it at scale.
Noël Boulene hit interesting scalability limits when trying to provision VLANs on Cisco ACI with Terraform. If you’re thinking about doing something similar, you REALLY SHOULD read his article.
Worth Reading: Automation Report From 1958
Are you afraid the network automation will eat your job? You might have to worry if you’re a VLAN-provisioning CLI jockey, but then you’re not alone. Textile workers faces the same challenges in 19th century and automation report from 1958 the clerical workers were facing the same dilemma when the first computers were introduced.
Guess what: unemployment rate has been going up and down in the meantime (US data), but mostly due to various crisis. Automation had little impact.
Video: Ugly Challenges of Using AI/ML in Networking
Javier Antich concluded the AI/ML in Networking webinar with the ugly challenges of using AI/ML in networking. I won’t spoil the fun, you REALLY SHOULD watch the video (keeping in mind he was trying to stay polite and diplomatic).
Worth Reading: Resolverless DNS
Every network engineer should be familiar with the DNS basics – after all, all network failures are caused by DNS… unless it’s BGP.
The May 2022 ISP Column by Geoff Huston is an excellent place to brush up on your DNS basics and learn about new ideas, including a clever one to push DNS entries that will be needed in the future to a web client through a DNS-over-HTTPS session.
ipSpace.net Blog Is in a Public GitHub Repository
I migrated my blog to Hugo two years ago, and never regretted the decision. At the same time I implemented version control with Git, and started using GitHub (and GitLab for a convoluted set of reasons) to host the blog repository.
After hesitating for way too long, I decided to go one step further and made the blog repository public. The next time a blatant error of mine annoys you fork it, fix my blunder(s), and submit a pull request (or write a comment and I’ll fix stuff like I did in the past).