Testing Network Automation Data Transformation
Every complex enough network automation solution has to introduce a high-level (user-manageable) data model that is eventually transformed into a low-level (device) data model.
High-level overview of the process
The transformation code (business logic) is one of the most complex pieces of a network automation solution, and there’s only one way to ensure it works properly: you test the heck out of it ;) Let me show you how we solved that challenge in netlab.
netlab has grown from a tiny Vagrantfile generator into a massive tool supporting a dozen technologies, each with its data transformation requirements. A rigorous automated testing process is the only way to ensure we don’t break stuff every other day. In this blog post, we’ll focus on the top part of the netlab architecture diagram:
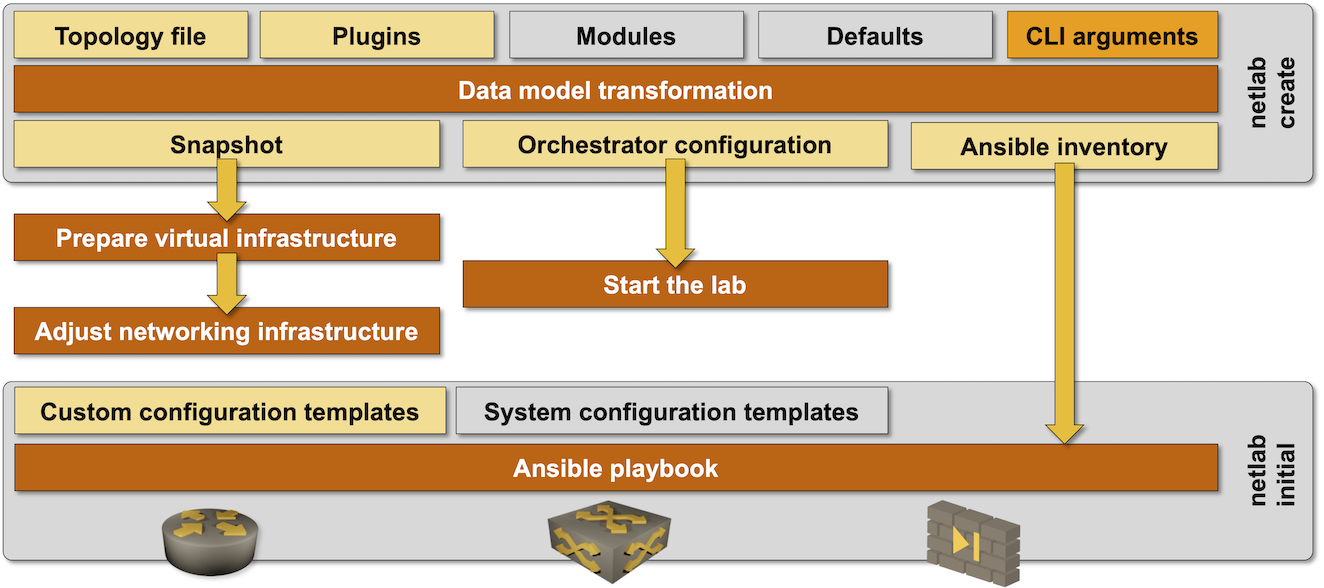
Netlab high-level architecture diagram
The journey starts with pre-commit and pre-push tests. These tests are implemented with the pre-commit tool and executed as Git actions on the developers’ machines. It’s impossible to enforce them1, so we’re repeating them as GitHub actions (running them locally just reduces the turnaround time) every time a new commit is pushed to the GitHub repository2.
The pre-commit tests are executed on every commit and should be as quick as possible. Our tests are running yamllint to validate the YAML markup.
The pre-push tests run mypy to check the Python code. More importantly, they run a battery of tests that check whether we broke the most complex bit of netlab: the transformation of lab topology data into device data models. Right now, we have ~100 transformation tests and another 100 tests checking netlab error handling. We’re adding new tests to cover new functionality and every time we deal with a major bug. The debugging process usually starts with a minimal lab topology that triggers the bug; that topology becomes a new test case once the bug is fixed.
The test harness for these tests is quite simple (more details):
- Read the lab topology
- Run the core transformation code
- Compare the transformed data mode with the expected results (or generated error messages with the expected error messages) and report the differences
While one could argue that the above approach isn’t equivalent to unit tests (it runs the whole transformation code, not a single component), it’s pretty efficient and has saved my bacon numerous times. It’s also a fantastic tool when I do code refactoring; something’s wrong if the refactored code cannot reproduce the expected results.
I also wanted to ensure that the essential bits of code (the core components used in almost any lab topology) are well-tested. The coverage tool was a perfect solution. It reports whether each line of Python code was executed, and adding a few test cases or tweaking lab topologies can bring you as close to 100% coverage as you wish.
Last but not least, we have over 150 integration tests (more about them in the next blog post), and just to be on the safe side, we run them through the data transformation engine on every pull request. The code merged into the main development branch is thus guaranteed to:
- Produce correct results for all transformation test scenarios.
- Not to crash on any lab topology used for integration tests.
Can you use the same approach to test your network automation solution? Of course; if you feel like borrowing some of the source code, please feel free to do so. There’s just one gotcha if you use a home-grown database or a third-party tool (like Nautobot) instead of YAML files as the source of truth: how will you create the test scenarios?
The most straightforward approach to that conundrum might be the one propagated by ancient Romans: divide and conquer3. Split the SoT-to-device-data process into data extraction and data transformation and test each one individually. You could use a sample database and the expected results to test the data extraction phase and numerous test scenarios (stored as YAML files) to test the data transformation logic.
Next: Testing Device Configuration Templates Continue
-
The developer must install and enable the pre-commit tool to make them work. ↩︎
-
We cannot enforce these tests in forked repositories, so we also run them on every pull request. ↩︎
-
A giant test case derived from a sample database would work, but figuring out which part of the data transformation code is broken would be a nightmare. It’s much better to have numerous test cases focusing on small subsets of functionality. ↩︎