BGP Graceful Restart Considered Harmful
A networking engineer with a picture-perfect implementation of a dual-homed enterprise site using BGP communities according to RFC 1998 to select primary- and backup uplinks contacted me because they experienced unacceptably long failover times.
They measured the failover times caused by the primary uplink loss and figured out it takes more than five minutes to reestablish Internet connectivity to their site.
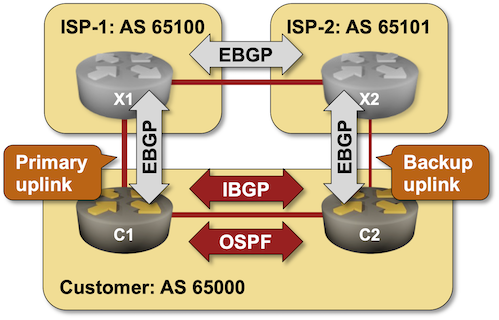
Approximate network diagram
Such a long convergence time is unusual and often indicates a failure to detect link- or neighbor loss in a timely manner. BFD is the best alternative when the link loss is not signaled correctly to the higher-layer protocols. Unfortunately, one has to configure it on both ends of a connection, and some ISPs still haven’t got the “BFD is better than BGP timers” memo.
BFD Echo mode might seem to be a workaround; using it, a router sends packets to itself and uses layer-2 encapsulation to route them through the adjacent device. However:
- Even if a system uses BFD Echo procedure, the use of BFD has to be negotiated with the neighbor
- Even if it were possible to use BFD without the remote system’s awareness, it wouldn’t solve the failover of incoming traffic. If the BGP neighbor believes the link is up, it won’t revoke the BGP prefix, and convergence won’t happen.
Lacking BFD, reducing BGP timers is the next best thing one can do. I suggested reducing them to something low enough for their needs but still sane and acceptable to the upstream ISP.
Did you know that BGP neighbors negotiate the BGP timers during the BGP session establishment process? You can reduce the timers on one BGP neighbor and have the other neighbor accept the changes.
If I were a Service Provider, I’d want to prevent my customers from hogging my CPU with very short BGP timers. Some network operating systems allow you to specify the minimum BGP timer values a device is willing to accept from its BGP neighbors.
However, the default BGP timers cause a three-minute convergence delay. Two minutes were still unaccounted for, and we couldn’t figure out what might be causing that extra delay until Andrea di Donato made an interesting remark when we were discussing the problem in one of the Design Clinics: “Make sure you haven’t configured BGP Graceful Restart.”
Here’s what’s going on behind the scenes:
- Any recent BGP implementation will accept that its neighbor uses Graceful Restart regardless of whether the Graceful Restart is configured locally.
- After losing a BGP neighbor, the Graceful Restart procedure keeps BGP routes in the BGP table until the Graceful Restart timer expires, effectively prolonging the convergence process.
- The default Cisco IOS Graceful Restart timer is two minutes. Bingo – we figured out the root cause for the five-minute convergence time.
Takeaway:
- Don’t configure BGP Graceful Restart until you know full well what you’re doing and what the implications are1
- Graceful Restart is a good idea if and only if you can reliably detect forwarding path failures using a mechanism like BFD (more caveats).
- Using Graceful Restart when relying on BGP timers to detect BGP neighbor loss is useless. All it does is prolong the inevitable pain unless you experience control-plane failures more often than link failures, in which case you’re dealing with a more severe challenge than convergence speed.
Obviously, no list of caveats ever stopped marketers from promoting a feature as the next best thing since sliced bread. For example, Cilium proudly announced its BGP Graceful Restart capability in a scenario where it makes no sense to use it – it’s a cluster, so run two BGP daemons on two service nodes and move on.
Finally, no technology can ever resist the siren song of ever more nerd knobs. For example, RFC 9494 describes long-lived BGP Graceful Restart that uses BGP communities to allow you to delay the convergence process for even longer.
Need Hands-on Practice?
Try out these BGP lab exercises:
- Use BFD to Speed Up BGP Convergence to master BGP timers and using BFD with BGP.
- BGP Local Preference in a Complex Routing Policy to implement RFC 1998-style routing policy.
-
That same rule can be applied to many other things. It is consistently ignored in the blatant throwing-spaghetti-at-the-wall style by people indiscriminately using Google or AI to solve their challenges. ↩︎
Most of the HA clustering solutions for stateful firewalls that I know implement a single-brain model, where the entire cluster is seen by the outside network as a single node. On the node which is currently primary runs the control plane (hence I call it single-brain). Sessions are syncronized between the nodes, as well as the forwarding plane. Therefore, in the event of HA failover, all the existing sessions are preserved, and user traffic can just keep flowing. You can get a subsecond failover, delayed only by the failure detection (which is based on HA keepalives sent back-to-back between the nodes, as well as link failure detection and things like that). But since it is a single-brain solution, the BGP daemon runs only on the primary node. Upon HA failover, it starts from scratch on the ex-secondary (new primary). This is where Graceful Restart comes into play, because it allows your peers to keep their forwarding state, believeing that your HA clustering solution successfully did the same on your side. Hence, you get your Non-Stop Forwarding and you don't bother the rest of your network with BGP convergence, while the new HA primary re-establishes its BGP control plane.
This is the most common use case for BGP GR that I saw in my career at least... There are also dual-brain HA solutions, where every node runs its own independent BGP/OSPF/whatever. But like I said, most of the stateful firewall vendors I encountered offer this single-brain solution, based on NSF + BGP GR.
By the way, since we are a bit nerdy here, I'd claim that the router X1 did not behave nicely, according to your description =) You say that the primary uplink failed. Then, three minutes later, the BGP Hold Timer expired. At this point, as per your conclusion, the router X1 assumed that C1 was restarting and entered the GR Helper mode, adding two more minutes to your misery. Well... it shouldn't have! The Hold Timer expiration is not a valid reason to assume GR. BGP GR process is initiated by a new OPEN message sent by the restarting peer. We could claim (as it is useful) that detecting TCP session death could also be considered as the start of GR. But not the Hold Timer expiration! If the Hold Timer expires, and the peer didn't send a new OPEN by that time, then the peer is just dead. No GR. So e.g. see RFC 4724 and the changes to the BGP FSM. It doesn't change the standard BGP behavior expected upon Hold Timer expiration. And neither should it.
One last point - regarding BFD... It makes a huge difference whether BFD is sharing fate with control plane or not (that is, whether the C-bit is set - as per section 4.3 in RFC 5882). If BFD is sharing fate with control plane, then upon losing BFD, the remote peer cannot understand whether you are dead or just restarting. The previous expectation to receive an OPEN message is no longer enough, because you obviously cannot send this message faster than BFD loss. Hence, this combination of BGP GR + control-dependent BFD is totally harmful and makes no sense. BUT the combination of BGP GR + control-independent BFD is good, because it helps you distinguish between a forwarding-plane failure (in which case the routes must be flushed asap) and GR (in which case the routes must be preserved).
Since we are a bit nerdy ;) Quoting RFC 4724:
> When the Receiving Speaker detects termination of the TCP session for a BGP session with a peer that has advertised the Graceful Restart Capability, it MUST retain the routes received from the peer for all the address families that were previously received in the Graceful Restart Capability and MUST mark them as stale routing information.
The termination of TCP session is detected when the TCP Hold Timer expires, and that's when the routes go into STALE state but are retained. After that...
> If the session does not get re-established within the "Restart Time" that the peer advertised previously, the Receiving Speaker MUST delete all the stale routes from the peer that it is retaining.
And because Cisco IOS advertises the 2-minute restart time, the peer waits for five minutes before triggering the convergence process.
> The termination of TCP session is detected when the TCP Hold Timer expires, and that's when the routes go into STALE state but are retained.
That's not how I read it. The Hold Timer expiration indicates the termination of the BGP session, not of the TCP session. I don't think they mean this kind of termination in this passage.
Proof: section 5 of that RFC where they propose the changes to the finite-state machine. Specifically:
Replace this text:
with
In other words, they refer here to the termination of the underlying TCP connection. Not a BGP event, but a TCP event! Not BGP that kills the underlying TCP (as in Hold Timer expiration), but the other way around. Example: imagine that your HA cluster fails over, but still doesn't send the new OPEN message (forgot ;)). The peer still doesn't know anything about this, so from its perspective the old TCP socket is still established, and so is the old BGP session. So it will send its next BGP Keepalive as usual, using that TCP connection, right? Except that on the other side we now have a new fresh primary node, which knows nothing about this TCP connection. Therefore, upon receiving a TCP segment which is not a SYN, it will react with TCP RST (or silently drop it, but that will not demonstrate my case, so let's assume it replies with TCP RST ;)). Upon receivng this TCP RST, the peer understands that something is wrong with that TCP connection. So it's a TCP event, not a BGP event! And I believe it's this kind of events that will result in TcpConnectionFail (Event 18) they refer above.
> The termination of TCP session is detected when the TCP Hold Timer expires, and that's when the routes go into STALE state but are retained.
That's not how I read it. The Hold Timer expiration indicates the termination of the BGP session, not of the TCP session. I don't think they mean this kind of termination in this passage.
Proof: section 5 of that RFC where they propose the changes to the finite-state machine. Specifically:
Replace this text:
with
In other words, they refer here to the termination of the underlying TCP connection. Not a BGP event, but a TCP event!
Not BGP that kills the underlying TCP (as in Hold Timer expiration), but the other way around.
Example: imagine that your HA cluster fails over, but still doesn't send the new OPEN message (forgot ;)). The peer still doesn't know anything about this, so from its perspective the old TCP socket is still established, and so is the old BGP session. So it will send its next BGP Keepalive as usual, using that TCP connection, right? Except that on the other side we now have a new fresh primary node, which knows nothing about this TCP connection. Therefore, upon receiving a TCP segment which is not a SYN, it will react with TCP RST (or silently drop it, but that will not demonstrate my case, so let's assume it replies with TCP RST ;)). Upon receivng this TCP RST, the peer understands that something is wrong with that TCP connection. So it's a TCP event, not a BGP event! And I believe it's this kind of events that will result in TcpConnectionFail (Event 18) they refer above.
RFC 9494 (Long-Lived Graceful Restart for BGP) de-preferences the routes under GR. This (immediately) triggers BGP convergence toward the backup routes. So I don't think this is quite the same as GR and that your last sentence is fair.
Thanks for the feedback. While you're right that the routes marked with LLGR_STALE are de-preferenced, (if I'm reading the RFC correctly) the depreferencing kicks in only if the neighbor already marked the routes with LLGR_STALE (in which case they're pretty useless anyway unless they're the only route to the destination) or if the GR helper marks them, which only happens after the GR timeout expires.
So, yet again assuming I'm reading the RFC correctly, the LLGR procedures kick in after the GR timeout expires. Until then, it's the same as GR. Obviously, one could lower the GR timer now that we have LLGR, but that just opens another can of worms.