… updated on Wednesday, June 7, 2023 05:04 UTC
Default EBGP Policy (RFC 8212)
One of the most common causes of Internet routing leaks is an undereducated end-customer configuring EBGP sessions with two (or more) upstream ISPs.
Without basic-level BGP knowledge or further guidance from the service providers, the customer network engineer1 might start a BGP routing process and configure two EBGP sessions, similar to the following industry-standard CLI2 configuration:
router bgp 65100
neighbor 10.1.0.2 remote-as 65001
neighbor 10.1.0.6 remote-as 65002
The results of such a simplistic configuration are too well-known3: the customer starts leaking routes between the two service providers, and if one of them happens to be Verizon, we have an Internet-wide meltdown.
I replicated that setup in a netlab lab using the following topology:
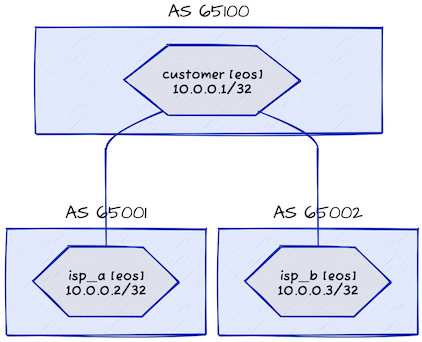
Lab topology
The netlab topology file is as simple as it can get:
- We’re using containerlab provider to reduce the lab startup times.
- All lab devices are running BGP
- We’re setting explicit BGP AS numbers on every device
- There are two links in the lab (from customer to ISP-A and ISP-B)
provider: clab
module: [ bgp ]
defaults.device: eos
nodes:
customer:
bgp.as: 65100
isp_a:
bgp.as: 65001
isp_b:
bgp.as: 65002
links: [ customer-isp_a, customer-isp_b ]
When I started the lab with Arista EOS devices, the route leaks were easy to observe:
isp-a>sh ip bgp
BGP routing table information for VRF default
Router identifier 10.0.0.2, local AS number 65001
Route status codes: s - suppressed contributor, * - valid, > - active, E - ECMP head, e - ECMP
S - Stale, c - Contributing to ECMP, b - backup, L - labeled-unicast
% - Pending BGP convergence
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI Origin Validation codes: V - valid, I - invalid, U - unknown
AS Path Attributes: Or-ID - Originator ID, C-LST - Cluster List, LL Nexthop - Link Local Nexthop
Network Next Hop Metric AIGP LocPref Weight Path
* > 10.0.0.1/32 10.1.0.1 0 - 100 0 65100 i
* > 10.0.0.2/32 - - - - 0 i
* > 10.0.0.3/32 10.1.0.1 0 - 100 0 65100 65002 i
Next, I changed the customer router to FRR using traditional defaults. I had to use a custom configuration template because the newer FRR versions ship with datacenter defaults.
The custom configuration template configured the traditional defaults, removed the BGP routing process (things get weird if you change the defaults after you’ve already configured BGP), and recreated the BGP configuration:
frr defaults traditional
!
no router bgp {{ bgp.as }}
!
router bgp {{ bgp.as }}
{% for af in ['ipv4'] %}
{% for n in bgp.neighbors if n[af] is defined %}
neighbor {{ n[af] }} remote-as {{ n.as }}
neighbor {{ n[af] }} description {{ n.name }}
{% endfor %}
{% if loopback[af] is defined and bgp.advertise_loopback %}
network {{ loopback[af]|ipaddr(0) }}
{% endif %}
{% endfor %}
Good news: the route leaks disappeared.
Bad news: the customer router refused to accept ISP prefixes and stopped announcing its routes to the two ISPs – it was time for another troubleshooting session.
The BGP table on the customer router had no ISP routes. It was like the router failed to establish the BGP sessions.
customer# sh ip bgp
BGP table version is 1, local router ID is 192.168.121.101, vrf id 0
Default local pref 100, local AS 65100
Status codes: s suppressed, d damped, h history, * valid, > best, = multipath,
i internal, r RIB-failure, S Stale, R Removed
Nexthop codes: @NNN nexthop's vrf id, < announce-nh-self
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 10.0.0.1/32 0.0.0.0 0 32768 i
Displayed 1 routes and 1 total paths
The BGP summary printout was confusing. It contained (Policy) in the column where one would expect to see the number of prefixes received from or sent to a neighbor.
customer# show bgp summary
IPv4 Unicast Summary (VRF default):
BGP router identifier 192.168.121.101, local AS number 65100 vrf-id 0
BGP table version 1
RIB entries 1, using 192 bytes of memory
Peers 2, using 1434 KiB of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt Desc
10.1.0.2 4 65001 8 5 0 0 0 00:02:44 (Policy) (Policy) isp_a
10.1.0.6 4 65002 8 5 0 0 0 00:02:44 (Policy) (Policy) isp_b
Total number of neighbors 2
FRR documentation describing the show bgp summary printout clears any potential doubts and includes a link to the bgp ebgp-requires-policy configuration command that describes FRR implementation of RFC 8212, a wonderful RFC that would stop most fat-finger leaks once implemented by major vendors.
RFC 8212 makes two small changes to the BGP route selection process:
- The BGP route selection process should not consider routes received from an EBGP neighbor without an explicit import policy.
- A router should not advertise its best routes to an EBGP neighbor without an explicit export policy.
FRR enforces RFC 8212 rules when using the traditional profile: ignoring all routes received from its EBGP neighbors and not sending any routes to them unless you have configured explicit neighbor policies.
With a bit of soul-searching, I was able to find the commands to configure AS-path access lists on FRR, resulting in the following BGP configuration:
router bgp 65100
neighbor 10.1.0.2 remote-as 65001
neighbor 10.1.0.2 description isp_a
neighbor 10.1.0.6 remote-as 65002
neighbor 10.1.0.6 description isp_b
!
address-family ipv4 unicast
network 10.0.0.1/32
neighbor 10.1.0.2 filter-list everything in
neighbor 10.1.0.2 filter-list own-as out
neighbor 10.1.0.6 filter-list everything in
neighbor 10.1.0.6 filter-list own-as out
exit-address-family
exit
!
bgp as-path access-list everything seq 5 permit .*
bgp as-path access-list own-as seq 5 permit ^$
End result: the customer is announcing its BGP prefixes to the two ISPs, but not leaking routes between them:
isp-a>show ip bgp
BGP routing table information for VRF default
Router identifier 10.0.0.2, local AS number 65001
Route status codes: s - suppressed contributor, * - valid, > - active, E - ECMP head, e - ECMP
S - Stale, c - Contributing to ECMP, b - backup, L - labeled-unicast
% - Pending BGP convergence
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI Origin Validation codes: V - valid, I - invalid, U - unknown
AS Path Attributes: Or-ID - Originator ID, C-LST - Cluster List, LL Nexthop - Link Local Nexthop
Network Next Hop Metric AIGP LocPref Weight Path
* > 10.0.0.1/32 10.1.0.1 0 - 100 0 65100 i
* > 10.0.0.2/32 - - - - 0 i
Obviously, you could use similar configuration commands on Arista EOS and get the same results. Still, you’re not forced to do so (but then FRR changed its default behavior away from RFC8212 in recent release as well), which brings us to the obvious question: which vendors support RFC8212 with the default settings?
The easiest way to find the answer is to look up Job Snijders’ RFC 8212 compliance tracking GitHub repository: the only commercial implementations compliant with RFC 8212 out-of-the-box are Cisco IOS XR and Nokia SR OS/SR Linux. You can configure Arista EOS, Cisco IOS XE, and Junos to be RFC8212-compliant, but that’s not their default behavior, An end-customer deploying BGP on Cisco IOS XE or Junos router for the first time would still be able to unknowingly leak routes between upstream ISPs.
There are at least three reasons I can see for the vendor reluctance to implement RFC 8212:
- RFC8212 compliance totally destroys the “using EBGP as a better IGP is simple” myth. That’s why FRR uses traditional and datacenter profiles with datacenter profile being the default.
- Support costs. Changing the default behavior results in customers opening support cases when the 20-year-old cheatsheet they got as the first Google hit doesn’t work.
- Backward compatibility. Upgrading the software would break some networks. Vendors were dealing with the same problem in the past (for example: migrating to BGP address families on Cisco IOS), so it’s not like the solution is a great unknown. Of course, it takes some effort to implement and document it.
And that’s why we still see tons of customer route leaks more than half a decade after RFC 8212 was published.
You’ll find more BGP route leak horror stories in the Internet Routing Security part of the Network Security Fallacies section of the How Networks Really Work webinar. For a deep dive, watch the Internet Routing Security webinar.
Revision History
- 2023-06-07
- In the initial version of this blog post, I complained how hard it might be for a newcomer to figure out why FRR doesn’t want to exchange routes with EBGP neighbors. A day later, Donatas Abraitis fixed the documentation (THANK YOU!!!), and the fix appeared in the official online FRR documentation less than 48 hours after I published the blog post. One has to love the agility of open-source development ;)
If I was an ISP, I would not give too much faith in customer's ability to have their BGP routing policy right. As a serious ISP I would always deploy a minimal inbound BGP routing policy set (for transit and peering) for safety reasons. If you are fluent you would automate routing policies (prefix-lists) based on e. g. RIPE database or equivalent service. In my opinion the ISPs are also in charge even more so.
From time to time there will be fat fingers where no RFC or routing policy will help.
I couldn't agree more, but unfortunately some big ISPs haven't got the memo yet.