… updated on Wednesday, September 28, 2022 17:22 UTC
Combining MLAG Clusters with VXLAN Fabric
In the previous MLAG Deep Dive blog posts we discussed the innards of a standalone MLAG cluster. Now let’s see what happens when we connect such a cluster to a VXLAN fabric – we’ll use our standard MLAG topology and add a VXLAN transport underlay to it with another switch connected to the other end of the underlay network.
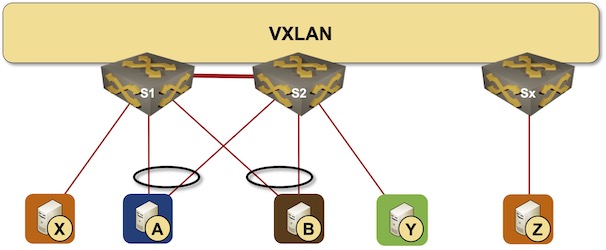
MLAG cluster connected to a VXLAN fabric
A few notes before we get to the cumbersome details:
- We still need the peer link between the MLAG cluster members. Replacing the peer link with a virtual link over the VXLAN fabric is another interesting topic that we’ll deal with some other time.
- Connecting MLAG clusters in a traditional bridging fabric is boring. Every MLAG cluster looks like a dual-homed host to adjacent clusters.
- Considerations similar to the ones described in this blog post apply to other transport technologies (TRILL, SPBM) or proprietary fabric solutions, but we won’t discuss them because those technologies aren’t exactly mainstream anymore.
Dynamic MAC Learning Ruins the Day
In a typical VXLAN-based fabric, we’d assign a unique VXLAN tunnel endpoint (VTEP) IP address to every leaf switch. That approach does not work for MLAG clusters if we want to rely on dynamic MAC learning instead of using EVPN control plane.
Imagine host A having a lot of TCP or UDP sessions with host Z:
- If the host A uses the typical 5-tuple hashing algorithm, it will probably use both uplinks (toward S1 and S2) to send Ethernet frames to Z.
- Ethernet frames with the same source MAC address (A) will be encapsulated into VXLAN frames on S1 and S2 and sent toward Sx.
- Sx might receive frames from the same source MAC address coming from two different source VTEPs (S1 and S2). That will totally confuse Sx if it uses dynamic MAC learning to build MAC-to-VTEP mapping tables
Conclusion: S1 and S2 must use the same source IP address when encapsulating the traffic coming from a dual-attached (MLAG) host.
Aside: The requirement to use an anycast VTEP IP address complicates the device configuration. VTEP IP address is usually attached to a loopback interface, and IP addresses configured on loopback interfaces are commonly used to set OSPF or BGP router ID.
Having two routers with the same router ID in a network running a link-state routing protocol produces interesting results. To alleviate that pitfall, vendors usually recommend configuring two loopback interfaces1, and using a static IGP router ID to ensure the automatic process doesn’t select the VTEP loopback interface as the source of router ID.
Back to VXLAN. The use of anycast VTEP IP address has an interesting side effect: load balancing works out of the box. S1 and S2 are advertising the same IP address with the same cost, and assuming the VXLAN transport network uses a leaf-and-spine topology, traffic from host Z to host A uses both switches (based on the source UDP port in the VXLAN packets).
Orphan Hosts
Orphan hosts are (as always) a source of pain. Imagine host X communicating with host Z:
- The traffic from X to Z will be encapsulated in VXLAN packets with anycast VTEP source IP address.
- Sx will use the anycast VTEP IP address to send the traffic from Z to X, and approximately half of those packets will end on the wrong egress switch (S2).
- S2 will have to use the peer link to send the packets received over the VXLAN fabric to X.
There’s a simple solution to this conundrum: use a different source VTEP IP address when encapsulating Ethernet packets received from orphan hosts. To do that, your ASIC has to support:
- Multiple destination VTEP addresses per switch – one for dual-attached hosts, another one for orphan hosts2
- Selecting the source VTEP address based on the ingress interface.
Looking at various VXLAN implementations, it seems like the above requirements aren’t exactly a walk in the park. Obviously we don’t know what data center switch ASICs can do (thanks a million, Broadcom, NVIDIA and friends), and people who could answer that question are not allowed to, but if you could say something without violating an NDA signed in blood, or send me an anonymous hint, you’d be most welcome.
Finally, this is the perfect moment for EVPN pundits to tell me how all the problems I just described get solved with EVPN multihoming. That’s not exactly true, and we’ll discuss the nuances in another blog post in this series.
Flooding Considerations
Now that we know how unicast forwarding works in MLAG clusters connected to a VXLAN fabric, let’s see how complex the flooding of BUM packets is.
Outbound direction is easy:
- Packets received from a host (orphan or MLAG-connected) are flooded to all other hosts, the peer link and the VXLAN fabric.
- Packets received from the peer link should not be flooded to the VXLAN fabric, as the MLAG peer already did that. From the perspective of the egress ACL discussed in MLAG Layer-2 Flooding blog post, VXLAN interface should be treated like an MLAG interface.
Now for the inbound direction, where the fabric could use IP multicast or ingress replication to flood BUM traffic.
When the VXLAN fabric uses multicast-based BUM flooding, all egress devices listening to the VNI IP multicast address receive all the flooded traffic, and the MLAG cluster members might have a fun time deciding who should forward the flooded packets to the MLAG hosts3.
The easiest solution to this challenge is to use a single MLAG cluster member as a dedicated flooder and register the VNI IP multicast address only on that node4. The Ethernet frames received from the VXLAN fabric would be flooded to all ports on the dedicated flooder – including the peer link – and the other member(s) of the MLAG cluster would use the exact same procedures they used in standalone MLAG cluster.5
What about VXLAN fabrics using ingress replication? That’s an even easier one. All MLAG cluster members advertise the same anycast VTEP IP address, and that address is used in the ingress replication lists on all other VTEPs.
When an ingress VTEP sends a replicated BUM packet to the anycast VTEP IP address, it’s received by a random MLAG cluster members. That switch can treat the flooded packet like it would be coming from an MLAG host: flood it to all other ports and the peer link. The standard MLAG flooding procedures take care of further flooding.
Revision History
- 2022-09-28
- Added flooding considerations, including outbound flooding, based on a comment by Erik Auerswald
Next: Using EVPN/VXLAN with MLAG Clusters Continue
-
In case you need a stable unique IP address per box. ↩︎
-
It looks like the ASICs used in Cisco Nexus switches can do that – this is exactly the functionality required for their EVPN vPC Multihoming implementation. ↩︎
-
Orphan hosts are easy ;) ↩︎
-
Alternatively, all members of MLAG cluster could listen to the VNI IP multicast address, and everyone but the dedicated flooder ignores BUM packets received over the VXLAN interface. Not listening to IP multicast might be simpler ;) ↩︎
-
If you’re keen on generating tons of interesting hardware bugs, you could go for a more complex implementation where all cluster members listen to the VNI IP multicast traffic, the dedicated flooder sends the VXLAN BUM packet to all local ports but not the peer link, and all other MLAG members send the VXLAN BUM packet only to the orphan ports. Have fun. ↩︎
Hi Ivan, Great blog as usual. For Orphan hosts, I am not sure how it is of any concern if the MLAG peer link has to be used if the traffic lands on other switch. You can always build a 80G or a 200G etherchannel (still they will be underutilized most of the times) MLAG peer link if there are too many orphan hosts. I think using single/anycast VTEP IP address in MLAG is perfect and works for all scenarios.
On your other question on EVPN ESI Multihoming, Route Types 1 and 4 exactly come to the rescue here for BUM traffic and Designated Forwarder concept from the ESI cluster members. But the 2 or >2 A/A ESI leafs from the ESI members will have lot of BGP EVPN route updates state churn happening within the layer 3 fabric.
Hello Ivan,
regarding "That switch can treat the flooded packet like it would be coming from an orphan host: flood it to all other ports and the peer link.":
I am not sure why you mention orphan port here. At least some MLAG implementations always flood via peer link and filter frames on egress to MLAG ports with active members on both switches.
I even think correlating Anycast VTEP and an orphan port might be a dangerous suggestion, because, at least in the filter on egress model mentioned above, the Anycast VTEP needs to be handled identically to an MLAG port. If the peer switch's Anycast VTEP is active, BUM traffic received via peer link must not be flooded via VXLAN, but it must be flooded otherwise.
One verification of the above I received was when I suggested a bug in the programming of said egress filters as cause for a network problem, and the vendor engineer looking into the case confirmed this suspicion.
... and you're absolutely right. Will fix, thank you!
Man, it sounds like adding MLAG to EVPN really creates a rather complex mess.
Under what circumstances would you choose this over a ESI LAG?
You haven't seen the ESI LAG mess yet ;)
I am eager to see it then!