Blog Posts in September 2022
Video: Kubernetes Services Types
Kubernetes services are like networking standards: there are so many to choose from. In his brief introduction to Kubernetes service types, Stuart Charlton listed six of them, and I’m positive there are more. That’s what you get when you’re trying to reinvent every network load balancing method known to mankind ;)
Cumulus Linux Network Command Line Utility (NCLU)
While ranting about Linux data plane configuration, I mentioned an interesting solution: Cumulus Linux Network Command Line Utility (NCLU), an attempt to make Linux networking more palatable to more traditional networking engineers.
NCLU is a simple wrapper around ifupdown2 and frr packages. You can execute net add and net del commands to set or remove configuration parameters1, and NCLU translates those commands into changes to corresponding configuration files.
… updated on Wednesday, September 28, 2022 17:22 UTC
Combining MLAG Clusters with VXLAN Fabric
In the previous MLAG Deep Dive blog posts we discussed the innards of a standalone MLAG cluster. Now let’s see what happens when we connect such a cluster to a VXLAN fabric – we’ll use our standard MLAG topology and add a VXLAN transport underlay to it with another switch connected to the other end of the underlay network.
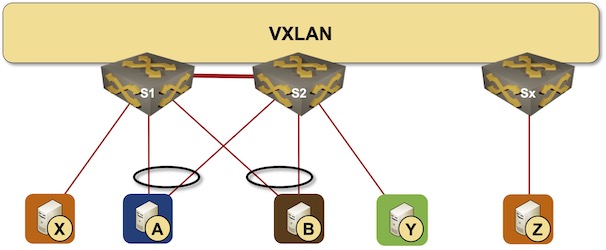
MLAG cluster connected to a VXLAN fabric
Repost: On the Viability of EVPN
Jordi left an interesting comment to my EVPN/VXLAN or Bridged Data Center Fabrics blog post discussing the viability of using VXLAN and EVPN in times when the equipment lead times can exceed 12 months. Here it is:
Interesting article Ivan. Another major problem I see for EPVN, is the incompatibility between vendors, even though it is an open standard. With today’s crazy switch delivery times, we want a multi-vendor solution like BGP or LACP, but EVPN (due to vendors) isn’t ready for a multi-vendor production network fabric.
netlab VXLAN Bridging Example
netlab release 1.3 introduced support for VXLAN transport with static ingress replication. Time to check how easy it is to replace a VLAN trunk with VXLAN transport. We’ll use the lab topology from the VLAN trunking example, replace the VLAN trunk between S1 and S2 with an IP underlay network, and transport Ethernet frames across that network with VXLAN.

Lab topology
Worth Reading: The Hierarchy Is Bullshit
Charity Majors published another masterpiece: The Hierarchy Is Bullshit (And Bad For Business).
I doubt that anyone who would need this particular bit of advice would read or follow it, but (as they say) hope springs eternal.
Video: Cloud-Native Environments
One of the overused buzzwords of the cloudy days is the Cloud-Native Environment. What should that mean and why could that be better than what we’ve been doing decades ago? Matthias Luft and Florian Barth tried to answer that question in the Introduction to Cloud Computing webinar.
SR-MPLS or SRv6 for Greenfield Networks
Here’s an interesting question randomly appearing in my Twitter feed:
If you had a greenfield network, would you choose SR-MPLS, or SRv6? And why?
TL&DR: SR-MPLS, assuming you’re building a network providing end-to-end connectivity between hardware edge devices.
Now for the why part of the question:
Linux Networking Data Plane Configuration
I spent a rainy day implementing VLANs, VRFs, and VXLAN on Cumulus Linux VX and came to “appreciate” the beauties of Linux networking configuration.
TL&DR: It sucks
There are two major ways of configuring data plane constructs (interfaces, port channels, VLANs, VRFs) on Linux:
EVPN/VXLAN or Bridged Data Center Fabric?
An attendee in the Building Next-Generation Data Center online course sent me an interesting dilemma:
Some customers don’t like EVPN because of complexity (it is required knowledge BGP, symmetric/asymmetric IRB, ARP suppression, VRF, RT/RD, etc). They agree, that EVPN gives more stability and broadcast traffic optimization, but still, it will not save DC from broadcast storms, because protections methods are the same for both solutions (minimize L2 segments, storm-control).
We’ll deal with the unnecessary EVPN-induced complexity some other time, today let’s start with a few intro-level details.
netlab Release 1.3.1: BGP local-as, FRR and Cumulus Data Plane Enhancements
netlab release 1.3.1 contains major additions to FRR and Cumulus Linux, and new BGP features:
- VXLAN, VLANs, VRFs, and EVPN implemented on FRR and Cumulus Linux
- BGP local-as implemented in the BGP configuration module and supported on Arista EOS, Cisco IOS, Dell OS10, FRR, and Nokia SR Linux.
- Configurable BGP transport sessions
- Configurable default BGP address families supported on Arista EOS, Cisco IOS, Cumulus Linux, FRR, and Nokia SR Linux.
Here are some of the other goodies included in this release:
The Basics of Network Address Translation (NAT)
The last video in the 2-hour-long Network Addressing part of How Networks Really Work discusses Network Address Translation.
After watching it, you might want to spend some extra quality time (with a bit of soap opera vibe) enjoying the recent Dual ISP deployment operational issues and uncertainties thread on the v6ops mailing list with a “surprising” result: NPTv6 or NAT66 is the least horrible way to do it.
Multi-Cloud: Myths and Reality
I keep hearing numerous variations of the following argument from people believing in the unlimited powers of multi-cloud1 (deploying your workloads in multiple public cloud providers):
We don’t install all our servers in the same DC. But would you trust one Cloud Server Provider with all your applications? That’s why you should use multi-cloud.
I’ve been hearing similar arguments for at least 30 years, including:
… updated on Tuesday, March 11, 2025 13:48 +0100
VLAN Interfaces and Subinterfaces
Early bridges implemented a single bridging domain across all ports. Within a few years, we got multiple bridging domains within a single device (including bridging implementation in Cisco IOS). The capability to have multiple bridging domains stretched across several devices was still missing… until the modern-day Pandora opened the VLAN box and forever swamped us in the complexities of large-scale bridging.
Infrastructure-as-Code Sounds Scary
One of my readers preparing for public cloud deployment sent me an interesting observation:
I pushed to use infrastructure-as-code as we move to Azure, but I’m receiving a lot of pushback due to most of the involved parties not having any experience with code. Management is scared to use any kind of “homegrown” tools that only a few would understand. I feel like I’m stuck deploying and managing the environment manually.
It looks like a bad case of suboptimal terminology for this particular audience. For whatever reason, some infrastructure engineers prefer to stay as far away from programming as possible1, and infrastructure-as-code sounds like programming to them.
netlab: VRF Lite Topology with VLAN Trunks
In the last blog post in the VLANs and VRFs in netlab series, I described how we can combine VLANs and VRFs and create a VRF Lite solution with stretched VLANs. Wonder how hard would it be to create a routed multi-hop VRF Lite topology? It’s trivial.
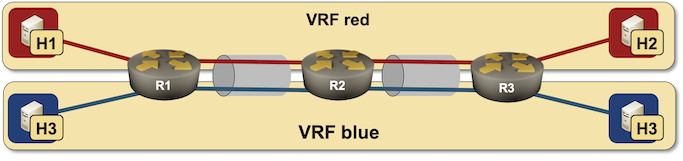
Routed VRF Lite lab topology
Worth Exploring: NetDoc – Automated Network Discovery and Documentation
Andrea Dainese released an interesting tool that performs automated network discovery, pushes the discovered data into NetBox, and then uses netbox-topology-views plugin to create network topology diagrams.
Definitely worth exploring!
Fun Times: Is Cisco ACI Dead?
A recent blog post by Andrew Lerner asks whether Cisco ACI is dead. According to Betteridge’s law of headlines, the answer is NO (which is also Andrew’s conclusion), but I liked this gem:
However, Gartner assesses that Nexus Dashboard Fabric Controller is the optimal fabric management software for most Cisco data center environments.
An automation intent-based system provisioning a traditional routed network is considered a better solution than a black-box proprietary software-defined blob of complexity? Who would have thought…
Video: Testing IPv6 RA Guard
After discussing rogue IPv6 RA challenges and the million ways one can circumvent IPv6 RA guard with IPv6 extension headers, Christopher Werny focused on practical aspects of this thorny topic: how can we test IPv6 RA Guard implementations and how good are they?
From Bits to Application Data
Long long time ago, Daniel Dib started an interesting Twitter discussion with this seemingly simple question:
How does a switch/router know from the bits it has received which layer each bit belongs to? Assume a switch received 01010101, how would it know which bits belong to the data link layer, which to the network layer and so on.
As is often the case, Peter Paluch provided an excellent answer in a Twitter thread, and allowed me to save it for posterity.
How Routers Became Bridges
Network terminology was easy in the 1980s: bridges forwarded frames between Ethernet segments based on MAC addresses, and routers forwarded network layer packets between network segments. That nirvana couldn’t last long; eventually, a big enough customer told Cisco: “I don’t want to buy another box if I already have your too-expensive router. I want your router to be a bridge.”
Turning a router into a bridge is easier than going the other way round1: add MAC table and dynamic MAC learning, and spend an evening implementing STP.
Was IPv6 Really the Worst Decision Ever?
A few weeks ago, Daniel Dib tweeted a slide from Radia Perlman’s presentation in which she claimed IPv6 was the worst decision ever as we could have adopted CLNP in 1992. I had similar thoughts on the topic a few years ago, and over tons of discussions, blog posts, and creating the How Networks Really Work webinar slowly realized it wouldn’t have mattered.

netlab Release 1.3: VXLAN and EVPN
netlab release 1.3 contains two major additions:
- VXLAN transport using static ingress replication or EVPN control plane – implemented on Arista EOS, Cisco Nexus OS, Dell OS10, Nokia SR Linux and VyOS.
- EVPN control plane supporting VXLAN transport, VLAN bridging, VLAN-aware bundles, and symmetric IRB – implemented on Arista EOS, Dell OS10, Nokia SR Linux, Nokia SR OS (control plane), VyOS, and FRR (control plane).
Here are some of the other goodies included in this release:
Feedback Appreciated: Next-Generation Metro Area Networks
Etienne-Victor Depasquale, a researcher at University of Malta, is trying to figure out what technologies service providers use to build real-life metro-area networks, and what services they offer on top of that infrastructure.
If you happen to be involved with a metro area network, he’d love to hear from you – please fill in this survey – and he promised that he’ll share the results of the survey with the participants.
Worth Reading: Latency Matters When Migrating Workloads
It’s so refreshing to find someone who understands the impact of latency on application performance, and develops a methodology that considers latency when migrating a workload into a public cloud: Adding latency: one step, two step, oops by Lawrence Jones.
Video: Kubernetes Services Overview
After completing the discussion of basic Kubernetes networking with a typical inter-pod traffic scenario, Stuart Charlton tackled another confusing topic: an overview of what Kubernetes services are.
… updated on Tuesday, March 11, 2025 10:49 +0100
Router Interfaces and Switch Ports
When I started implementing the netlab VLAN module, I encountered (at least) three different ways of configuring physical interfaces and bridging domains even though the underlying packet forwarding operations (and sometimes even the forwarding hardware) are the same. That confusopoly is guaranteed to make your head spin for years, and the only way to figure out what’s going on behind the scenes is to go back to the fundamentals.