Blog Posts in June 2022
When You Find Yourself on Mount Stupid
The early October 2021 Facebook outage generated a predictable phenomenon – couch epidemiologists became experts in little-known Bridging the Gap Protocol (BGP), including its Introvert and Extrovert variants. Unfortunately, I also witnessed several unexpected trips to Mount Stupid by people who should have known better.
To set the record straight: everyone’s been there, and the more vocal you tend to be on social media (including mailing lists), the more probable it is that you’ll take a wrong turn and end there. What matters is how gracefully you descend and what you’ve learned on the way back.
Repost: Buffers, Congestion, Jitter, and Shapers
Béla Várkonyi left a great comment on a blog post discussing (among other things) whether we need large buffers on spine switches. I don’t know how many people read the comments; this one is too valuable to be lost somewhere below the fold
You might want to add another consideration. If you have a lot of traffic aggregation even when the ingress and egress port are roughly at the same speed or when the egress port has more capacity, you could still have congestion. Then you have two strategies, buffer and suffer jitter and delay, or drop and hope that the upper layers will detect it and reduce the sending by shaping.
Worth Reading: Smart Highways or Smart Cars?
I stumbled upon an interesting article in one of my RSS feeds: should we build smart highways or smart cars?
The article eloquently explains how ridiculous and expensive it would be to put the smarts in the infrastructure, and why most everyone is focused on building smart cars. The same concepts should be applied to networking, but of course the networking vendors furiously disagree – the network should be as complex, irreplaceable, and expensive as possible. I collected a few examples seven years ago, and nothing changed in the meantime.
netlab VLAN Module Is Complete
One of the last things I did before starting the 2022 summer break was to push out the next netlab release.
It includes support for routed VLAN subinterfaces (needed to implement router-on-a-stick) and routed VLANs (needed to implement multi-hop VRF lite), completing the lengthy (and painful) development of the VLAN configuration module. Stefano Sasso added VLAN support for Mikrotik RouterOS and VyOS, and Jeroen van Bemmel completed VLAN implementation for Nokia SR Linux. Want to see VLANs on other platforms? Read the contributor guidelines and VLAN developer docs, and submit a PR.
I’ll be back in September with more blog posts, webinars, and cool netlab features. In the meantime, automate everything, get away from work, turn off the Internet, and enjoy a few days in your favorite spot with your loved ones!
MLAG Deep Dive: Layer-3 Forwarding
The layer-2 forwarding and flooding in an MLAG cluster are intricate but still reasonably easy to understand. Layer-3 gets more interesting; its quirks depend heavily on layer-2 implementation. While most MLAG implementations exhibit similar bridging behavior, expect interesting differences in routing behavior.
We’ll have to expand by-now familiar network topology to cover layer-3 edge cases. We’ll still work with two switches in an MLAG cluster, but we’ll have an external router attached to both of them. The hosts connected to the switches belong to two subnets (red and blue).
VXLAN-to-VXLAN Bridging in DCI Environments
Almost exactly a decade ago I wrote that VXLAN isn’t a data center interconnect technology. That’s still true, but you can make it a bit better with EVPN – at the very minimum you’ll get an ARP proxy and anycast gateway. Even this combo does not address the other requirements I listed a decade ago, but maybe I’m too demanding and good enough works well enough.
However, there is one other bit that was missing from most VXLAN implementations: LAN-to-WAN VXLAN-to-VXLAN bridging. Sounds weird? Supposedly a picture is worth a thousand words, so here we go.
Help Appreciated: netsim-tools Device Features
There are (at least) two steps to get new functionality (like VLANs) implemented in netsim-tools:
- We have to develop a data transformation module that takes high-level lab-, node-, link- or interface attributes and transforms them into device data.
- Someone has to create Jinja2 templates for each supported device that transform per-device netsim-tools data into device configurations.
I usually implement new features on Cisco IOSv and Arista EOS1, Stefano Sasso adds support for VyOS, Dell OS10, and Mikrotik RouterOS, and Jeroen van Bemmel adds Nokia SR Linux and/or SR OS support. That’s less than half of the platforms supported by netsim-tools, and anything you could do to help us increase the coverage would be highly appreciated.
Worth Reading: Is IPv6 Faster Than IPv4?
In a recent blog post, Donal O Duibhir claims IPv6 is faster than IPv4… 39% of the time, which at a quick glance makes as much sense as “60% of the time it works every time”. The real reason for his claim is that there was no difference between IPv4 and IPv6 in ~30% of the measurements.
Unfortunately he measured only the Wi-Fi part of the connection (until the first-hop gateway); I hope he’ll keep going and measure response times from well-connected dual-stack sites like Google’s public DNS servers.
Video: IPv6 RA Guard and Extension Headers
Last week’s IPv6 security video introduced the rogue IPv6 RA challenges and the usual countermeasure – RA guard. Unfortunately, IPv6 tends to be a wonderfully extensible protocol, creating all sorts of opportunities for nefarious actors and security researchers.
For years, the networking vendors were furiously trying to plug the holes created by the academically minded IPv6 designers in love with fragmented extension headers. In the meantime, security researches had absolutely no problem finding yet another weird combination of IPv6 headers that would bypass any IPv6 RA guard implementation until IETF gave up and admitted one cannot have “infinitely extensible” and “secure” in the same sentence.
For more details watch the video by Christopher Werny describing how one could use IPv6 extension headers to circumvent IPv6 RA guard
… updated on Sunday, June 19, 2022 16:02 UTC
MLAG Deep Dive: Layer-2 Flooding
In the previous blog post of the MLAG Technology Deep Dive series, we explored the intricacies of layer-2 unicast forwarding. Now let’s focus on layer-2 BUM1 flooding functionality of an MLAG system.
Our network topology will have two switches and five hosts, some connected to a single switch. That’s not a good idea in an MLAG environment, but even if you have a picture-perfect design with everything redundantly connected, you will have to deal with it after a single link failure.
Beware of Vendors Bringing White Papers
A few weeks ago I wrote about tradeoffs vendors have to make when designing data center switching ASICs, followed by another blog post discussing how to select the ASICs for various roles in data center fabrics.
You REALLY SHOULD read the two blog posts before moving on; here’s the buffer-related TL&DR for those of you ignoring my advice ;)
netlab: Combining VLANs with VRFs
Last two weeks we focused on access VLANs and VLAN trunk netlab implementation. Can we combine them with VRFs? Of course.
The trick is very simple: attributes within a VLAN definition become attributes of VLAN interfaces. Add vrf attribute to a VLAN and you get all VLAN interfaces created for that VLAN in the corresponding VRF. Can’t get any easier, can it?
How about extending our VLAN trunk lab topology with VRFs? We’ll put red VLAN in red VRF and blue VLAN in blue VRF.
Video: Rogue IPv6 RA Challenges
IPv6 security-focused presentations were usually an awesome opportunity to lean back and enjoy another round of whack-a-mole, often starting with an attacker using IPv6 Router Advertisements to divert traffic (see also: getting bored at Brussels airport) .
Rogue IPv6 RA challenges and the corresponding countermeasures are thus a mandatory part of any IPv6 security training, and Christopher Werny did a great job describing them in IPv6 security webinar.
Using Custom Vagrant Boxes with netlab
A friend of mine started using Vagrant with libvirt years ago (it was his enthusiasm that piqued my interest in this particular setup, eventually resulting in netlab). Not surprisingly, he’s built Vagrant boxes for any device he ever encountered, created quite a collection that way, and would like to use them with netlab.
While I didn’t think about this particular use case when programming the netlab virtualization provider interface, I decided very early on that:
- Everything worth changing will be specified in the system defaults
- You will be able to change system defaults in topology file or user defaults.
Select the Best Switching ASIC For the Job
Last week I described some of the data center switching ASIC design tradeoffs and the ASIC families Broadcom created to fit somewhere in that multi-dimensional space.
Next step: how could you design your data center fabric to make the most out of them? To keep things simple, we’ll build a typical leaf-and-spine fabric with a WAN edge layer (sometimes called border leaf switches).
MLAG Deep Dive: Dynamic MAC Learning
In the first blog post of the MLAG Technology Deep Dive series, we explored the components of an MLAG system and the fundamental control plane requirements.
This post focuses on a major building block of the layer-2 data plane functionality: MAC learning. We’ll keep using the same network topology with two switches and five hosts, and assume our system tries its best to implement hot-potato switching (sending the frames toward the destination MAC address on the shortest possible path).
netlab VLAN Trunk Example
Last week I described how easy it is to use access VLANs in netlab. Next step: VLAN trunks.
We’ll add two Linux hosts to the lab topology used in the previous blog post, resulting in two switches, two Linux hosts in red VLAN and two Linux hosts in blue VLAN.
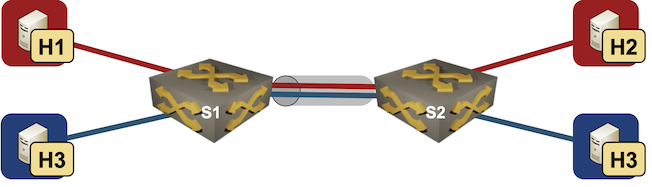
Lab topology
Video: Network Address Scopes
When defining network addresses in IEN 19 John Shoch said:
Addresses must, therefore, be meaningful throughout the domain, and must be drawn from some uniform address space.
But what is a domain? Welcome to the address scope discussion ;)
Data Center Switching ASICs Tradeoffs
A brief mention of Broadcom ASIC families in the Networking Hardware/Software Disaggregation in 2022 blog post triggered an interesting discussion of ASIC features and where one should use different ASIC families.
Like so many things in life, ASIC design is all about tradeoffs. Usually you’re faced with a decision to either implement X (whatever X happens to be), or have high-performance product, or have a reasonably-priced product. It’s very hard to get two out of three, and getting all three is beyond Mission Impossible.
MLAG Deep Dive: System Overview
Multi-Chassis Link Aggregation (MLAG) – the ability to terminate a Port Channel/Link Aggregation Group on multiple switches – is one of the more convoluted1 bridging technologies2. After all, it’s not trivial to persuade two boxes to behave like one and handle the myriad corner cases correctly.
In this series of deep dive blog posts, we’ll explore the intricacies of MLAG, starting with the data plane considerations and the control plane requirements resulting from the data plane quirks. If you wonder why we need all that complexity, remember that Ethernet networks still try to emulate the ancient thick yellow cable that could lose some packets but could never reorder packets or deliver duplicate packets.