… updated on Sunday, January 16, 2022 07:58 UTC
Building a BGP Anycast Lab
The Anycast Works Just Fine with MPLS/LDP blog post generated so much interest that I decided to check a few similar things, including running BGP-based anycast over a BGP-free core, and using BGP Labeled Unicast (BGP-LU).
The Big Picture
We’ll use the same physical topology we used in the OSPF+MPLS anycast example: a leaf-and-spine fabric (admittedly with a single spine) with three anycast servers advertising 10.42.42.42/32 attached to two of the leafs:
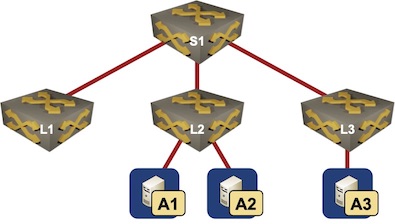
Lab topology
We’ll use BGP as the endpoint reachability protocol and OSPF as the core IGP:
- Switches run OSPF on the core links and belong to BGP AS 65000
- Spine switch is also a BGP route reflectors1
- Leaf switches are route reflector clients
- IBGP sessions follow the physical fabric topology
- Anycast servers run only BGP. They are in AS 65101
- There are EBGP sessions between anycast servers and adjacent switches. There are no IBGP sessions between the anycast servers.
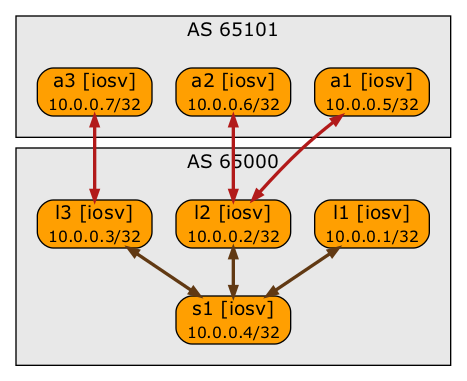
BGP sessions in the BGP anycast lab
Ideal end result: three equal-cost paths toward the anycast prefix on L1 and S1.
Acceptable end result: three equal-cost paths toward the anycast prefix on S1. All traffic from L1 has to go through S1 anyway (although that won’t be the case once we turn on MPLS).
Backup plan: 2-to-1 traffic split between L2 and L3 on S1 (and hopefully on L1).
Building the Lab Topology File
Before digging into the details: a friend of mine was reading this blog post and said “it looks like you have to turn a lot of nerd knobs to set it up”. He’s right, but do keep in mind that the end result is a fully configured lab running OSPF, EBGP, IBGP, and BGP RR.
Ready? Let’s go!
We’ll start with the lab topology file we used for the OSPF+MPLS lab, add BGP module, and describe the autonomous systems in the lab with bgp.as_list dictionary:
module: [ ospf, bgp ]
bgp:
as_list:
65000:
members: [ l1, l2, l3, s1 ]
rr: [ s1 ]
65101:
members: [ a1,a2,a3 ]
nodes:
[ l1, l2, l3, s1, a1, a2, a3 ]
links: [ s1-l1, s1-l2, s1-l3, l2-a1, l2-a2, l3-a3 ]
I knew I would have to enable BGP Additional Paths in AS 65000 to ensure L1 gets multiple paths toward the anycast prefix (we’ll need that when we add MPLS transport to the lab), and the easiest way to do that would be to create a group with a custom deployment template (like I did in the BGP AddPath lab):
groups:
network:
members: [ l1, l2, l3, s1 ]
config: [ bgp-addpath.j2 ]
anycast:
members: [ a1, a2, a3 ]
config: [ bgp-anycast-loopback.j2 ]
The “only” problem with this solution is duplicate data (and you know I hate that): I’m defining the same groups twice. Wouldn’t it be great if the BGP configuration module created groups based on AS membership (as65000 and as65101 in our case).
Sure thing – netlab includes auto-generated BGP groups that can also be used to set any other group attribute, simplifying my group definition. I have to define the custom deployment template, and the group members are added by the BGP topology transformation module based on bgp.as_list definition.
groups:
as65000:
config: [ bgp-addpath.j2 ]
as65101:
config: [ bgp-anycast-loopback.j2 ]
Next: I’d like to have an anycast attribute somewhere in the topology file instead of a hard-coded anycast prefix in the configuration template. bgp.anycast node data seems like a perfect choice, but I’d have to set it on three nodes, replacing my simple list of nodes with a more complex dictionary containing (yet again) duplicate data:
nodes:
l1:
l2:
l3:
s1:
a1:
bgp.anycast: 10.42.42.42/32
a2:
bgp.anycast: 10.42.42.42/32
a3:
bgp.anycast: 10.42.42.42/32
Wouldn’t it be nice if I could use an existing group to set an attribute for every node in the group? As it happens, netlab allows you to add node data to groups, significantly simplifying my lab topology (final topology file):
groups:
as65000:
config: [ bgp-addpath.j2 ]
as65101:
config: [ bgp-anycast-loopback.j2 ]
bgp.anycast: 10.42.42.42/32
nodes: [ l1, l2, l3, s1, a1, a2, a3 ]
Final touch: netlab checks module- and node data, so I had to tell the tool that I want to use bgp.anycast node attribute that has to be an IPv4 prefix:
defaults.bgp.attributes.node.anycast: { type: ipv4, use: prefix }
Next step: Jinja2 template that uses bgp.anycast attribute to configure another loopback interface and advertise it into BGP:
{% if bgp is defined and bgp.anycast is defined %}
interface loopback 42
ip address {{ bgp.anycast|ipaddr('address') }} {{ bgp.anycast|ipaddr('netmask') }}
!
router bgp {{ bgp.as }}
address-family ipv4
network {{ bgp.anycast|ipaddr('address') }} mask {{ bgp.anycast|ipaddr('netmask') }}
{% endif %}
Finally, I modified the IBGP Add Path template to enable bidirectional Add Path functionality within the autonomous system – we need that to allow the edge routers to send multiple paths to the route reflectors, hoping S1 and L1 will get three BGP paths to the anycast prefix.
router bgp {{ bgp.as }}
address-family ipv4 unicast
bgp additional-paths select all
bgp additional-paths send receive
maximum-paths 16
maximum-paths ibgp 16
{% for n in bgp.neighbors if n.type == 'ibgp' %}
neighbor {{ n.ipv4 }} advertise additional-paths all
{% endfor %}
Smoke Test
I started the lab with netlab up and inspected the BGP table on S1 (the spine node):
s1#show ip bgp 10.42.42.42
BGP routing table entry for 10.42.42.42/32, version 10
Paths: (3 available, best #2, table default)
Multipath: eBGP iBGP
Path not advertised to any peer
Refresh Epoch 1
65101, (Received from a RR-client)
10.0.0.2 (metric 2) from 10.0.0.2 (10.0.0.2)
Origin IGP, metric 0, localpref 100, valid, internal
rx pathid: 0x1, tx pathid: 0
Path advertised to update-groups:
1
Refresh Epoch 1
65101, (Received from a RR-client)
10.0.0.2 (metric 2) from 10.0.0.2 (10.0.0.2)
Origin IGP, metric 0, localpref 100, valid, internal, multipath, best
rx pathid: 0x0, tx pathid: 0x0
Path advertised to update-groups:
1
Refresh Epoch 1
65101, (Received from a RR-client)
10.0.0.3 (metric 2) from 10.0.0.3 (10.0.0.3)
Origin IGP, metric 0, localpref 100, valid, internal, multipath(oldest), all
rx pathid: 0x0, tx pathid: 0x1
Wow, almost there. There are three paths in the BGP table on S1 (the route reflector), the only glitch is that one of the paths advertised by L2 is not advertised to route reflector clients (like L1). No wonder, it’s identical to the other path advertised by L2. Even worse, it doesn’t get installed in the routing table either.
s1#show ip route 10.42.42.42
Routing entry for 10.42.42.42/32
Known via "bgp 65000", distance 200, metric 0
Tag 65101, type internal
Last update from 10.0.0.2 00:09:17 ago
Routing Descriptor Blocks:
* 10.0.0.3, from 10.0.0.3, 00:09:17 ago
Route metric is 0, traffic share count is 1
AS Hops 1
Route tag 65101
MPLS label: none
10.0.0.2, from 10.0.0.2, 00:09:17 ago
Route metric is 0, traffic share count is 1
AS Hops 1
Route tag 65101
MPLS label: none
The correct solution to this challenge is to use the DMZ Link Bandwidth BGP community, resulting in our backup plan. Trying to reach the original goal, let’s try to fix the problem by turning off the next-hop-self on AS edge routers.
Tweaking the BGP Next Hops
Turning off next-hop-self (the default setting) requires quite a bit of attribute haggling within netlab topology file:
- Set bgp.next_hop_self to false;
- Set bgp.ebgp_role to stub (default: external) to make sure the external subnets are included in the OSPF process;
- Set bgp.advertise_roles to an empty list, otherwise we’d get all the external subnets in the BGP table.
The modified topology file is available on GitHub.
bgp:
ebgp_role: stub
advertise_roles: []
next_hop_self: false
I could log into the individual devices (L2 and L3) and reconfigure them, but it’s more convenient (and maybe even faster) to destroy the whole lab with netlab down and bring a new lab up with netlab up, enjoying a sip of coffee in the meantime.
Here’s the BGP table on the route reflector (S1) after the changes to the lab topology file removed the neighbor next-hop-self configuration on the AS edge routers:
s1#sh ip bgp 10.42.42.42
BGP routing table entry for 10.42.42.42/32, version 11
Paths: (3 available, best #3, table default)
Multipath: eBGP iBGP
Path advertised to update-groups:
1
Refresh Epoch 1
65101, (Received from a RR-client)
10.1.0.21 (metric 2) from 10.0.0.3 (10.0.0.3)
Origin IGP, metric 0, localpref 100, valid, internal, multipath(oldest), all
rx pathid: 0x0, tx pathid: 0x1
Path not advertised to any peer
Refresh Epoch 1
65101, (Received from a RR-client)
10.0.0.2 (metric 2) from 10.0.0.2 (10.0.0.2)
Origin IGP, metric 0, localpref 100, valid, internal
rx pathid: 0x1, tx pathid: 0
Path advertised to update-groups:
1
Refresh Epoch 1
65101, (Received from a RR-client)
10.0.0.2 (metric 2) from 10.0.0.2 (10.0.0.2)
Origin IGP, metric 0, localpref 100, valid, internal, multipath, best
rx pathid: 0x0, tx pathid: 0x0
That’s totally weird: L3 is advertising the anycast prefix with the original next hop (A3), L2 is advertising two paths to the anycast prefix (toward A1 and A2), but changes the next hop to itself even though that was not configured. Changing the BGP next hop behavior bought us nothing.
Here’s what’s going on:
- L2 has two equal-cost paths to the anycast prefix;
- It tries to do its best, changing the next hop to itself (more details) to make sure it will get the traffic for the anycast prefix and spread it across multiple egress paths;
- Changing the next hop is unnecessary as we’ve configured Additional Paths, but it looks like those two bits of BGP code don’t work together in the Cisco IOS release I was running. I retried with IOS XE 16.06 and got the same results.
Next time: fixing the problem the right way with DMZ Link Bandwidth.
Revision History
- 2024-10-20
- Simplified the “adding bgp.anycast attribute” bit
- 2023-02-03
- Introduced new features available in release 1.5.0
- 2022-04-07
- Fixed GitHub links
- 2022-01-16
- Added definition of custom BGP attribute (not required at the time I published the original blog post).
-
In a real network you’d have more than one spine switch, and they would all be route reflectors for redundancy reasons. ↩︎
"Spine switches are also BGP route reflectors" <<< There's only one spine switch in your example.
"Ideal end result: three equal-cost paths toward the anycast prefix on L1 and S*2*." <<< should be S1
In the output "Routing table for the anycast prefix on the spine node (S1)" I think the next-hop "10.1.0.21" is wrong as you haven't disabled next-hop-self on leaf switches at that stage. It should be "10.0.0.3".
Maybe implicit next-hop-self and BGP Add-Path is an optimization mechanism because there's only one exit point (L2 in that example) anyway. Kinda like a summarization.
For the one minute/60 seconds delay after bootup maybe "bgp update-delay" will solve it. Found something from Petr: https://blog.ine.com/2010/11/22/understanding-bgp-convergence Otherwise I suggest to debug BGP.
FRR has a 'frr defaults datacenter' command which reduces BGP timer intervals from their (conservative) Internet-based BGP defaults. https://www.cisco.com/c/en/us/support/docs/ip/border-gateway-protocol-bgp/17612-bgp.html suggests that the default peer retry time on Cisco is 30s, try reducing that to the minimum (10s) (for example)
@Anonymous: Thank you, fixed.
The logic for implicit next hop self is probably going along this line: "if I have two paths, but I can only advertise one, let's make myself the next hop because I know how to use both of them, but others won't"
It seems the long delay is caused by
bgp nopeerup-delay, maybe in combination with Graceful Restart code, as the BGP RIB is evaluated as soon as the updates from the last BGP neighbor are received. More testing needed.But command "bgp nopeerup-delay" is not configured by default on Cisco IOS whereas "bgp update-delay" is set to 120 seconds by default. See: https://www.cisco.com/c/en/us/td/docs/ios-xml/ios/iproute_bgp/command/irg-cr-book/bgp-a1.html
Daniel also got a good explanation: https://lostintransit.se/2016/02/25/ccde-bgp-convergence/
It seems that someone has had success with "bgp update-delay" in the past: https://community.cisco.com/t5/routing/slow-bgp-convergence/td-p/2008294