Mythbusting: NFV Data Center Fabric Buffering Requirements
Every now and then I stumble upon an article or a comment explaining how Network Function Virtualization (NFV) introduces new data center fabric buffering requirements. Here’s a recent example:
For Telco/carrier Cloud environments, where NFVs (which are much slower than hardware SGW) get used a lot, latency is higher with a lot of jitter due to the nature of software and the varying link speeds, so DC-level near-zero buffer is not applicable.
It seems to me we’re dealing with another myth. Starting with the basics:
- NFV is Network Function Virtualization – routing, switching, network security, or load balancing running in virtual machines or containers (often within a carrier cloud).
- Some people add voice gateways to the mix, like voice wouldn’t be just another application using small packets on top of the network infrastructure (like DNS).
- In any case, I haven’t seen many network functions that would create significant amount of new traffic. In most cases, a packet gets into the (virtual or physical) appliance, is inspected, mangled, and sent out or dropped.
One-to-many media gateways are an obvious exception to that rule, but I wouldn’t worry about them1. After all, we’re running most of our voice and video calls over public Internet, and they mostly work reasonably well in an environment that’s way more demanding than anything that could happen in a data center fabric.
For the ballpark discussion we’re having right now, let’s assume NFV instances do packet processing and not packet generation. Now let’s look at a typical NFV-hosting data center and try to figure out what that means assuming NFV consumers are outside of the data center:
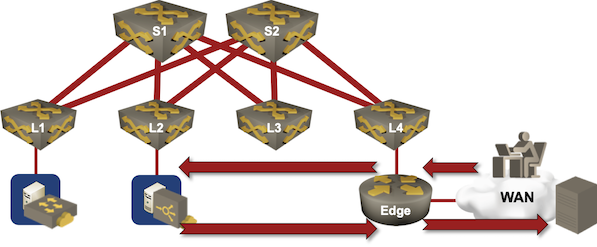
Typical NFV architecture
- The total bandwidth requirement of your NFV cloud is limited by the WAN ingress bandwidth.
- You need more bandwidth within the fabric if you chain NFV devices, but unless you’re doing something extremely convoluted, you won’t need more than an order of magnitude more bandwidth.
- Required egress WAN bandwidth is comparable to the ingress bandwidth (obvious exception: media gateways).
- Aggregate data center fabric bandwidth is usually order(s) of magnitude bigger than the WAN bandwidth. Four pizza-box spine switches give you 50 Tbps of forwarding bandwidth2. Compare that to a few 100 Gbps WAN links you might have (or not).
- There are no traffic bursts. Speeds within the data center fabric are higher than the WAN speeds, which means that the packets arriving to an NFV appliance are effectively trickling in.
- NFV instances might be batching packets to optimize processing, but I wouldn’t expect to see megabyte-size bursts. That would just introduce too much latency.
Considering all that, it looks to me like:
- NFV deployments might be even less demanding than typical data center applications (because they’re bandwidth-limited).
- There is no buffering problem within a data center fabric.
- You still need decent buffers in the WAN edge router, but probably not any more than what you have on the other side of the WAN link.3
Of course I could be totally wrong (even though this thingy was simmering for a few years before I managed to write it down). Should that be the case, I would appreciate someone pointing out my errors.
-
And I still don’t understand why someone would call them network function. You don’t call a web site implementing a video streaming a network function, do you? ↩︎
-
Make that 100 Tbps when using marketing math. ↩︎
-
If the remote buffers were good enough to get a packet into the data center, similar egress buffers should be good enough to get the processed packet out of it. ↩︎
"Network Function": the telcos used to use a lot of dedicated network boxes: small routers, firewalls, load balancers, and the like. They realized some years ago that scaling those designs to next gen wired or wireless bandwidths would lead to a stupid level of CapEx. So the intent was to run those appliances as software in regular arrays of commodity servers, the same as had been done for applications in VMs and containers.
There isn't a good name for the set of things which used to run in dedicated boxes sold for 10x the cost of parts. So I'll allow "Network Function", which is not intuitive to me either, as that name.
Hi Ivan and all,
The major difference with a traditional DC (i.e. a modern Fabric-based DC with no NFV deployment) are the following to me:
There's a much higher and vary RTT in a Telco Cloud environment
There's a much higher-volume north-South component compared to a traditional Telco DC as, within the former, the mobile PEs and business PEs and especially your fixed NAS/BRAS are all virtualised and thus all of your customers' traffic ends up traversing the fabric several times
The BW*RTT product of the average TCP flow is higher in a Telco Cloud
In a Telco Cloud, the NFV service-chaining design, for both mobile and fixed services, often induces a lot of unavoidable east-west tromboning on top of the east-west induced traffic. It's not easy to coordinate over a common fabric the design requirements from different Carrier/Telco's teams (e.g. mobile backhauling, fixed backhauling, mobile packet core, IMS, CDN, security, ... and so forth) and sometimes you also need to factor in Leaf and/or controller routing/chipset limitations forcing you to do tromboning or detouring in order to circumvent them
In a Telco Cloud there is no control over the TCP stacks involved and powerful network-level solutions such as ECN are normally not present either as chipsets are quite cheap
In any Fabric, Telco cloud's included, Leaf nodes tend to have small/shallow buffers as they must be cheap - that's one of the major advantages of having a fabric at the end of the day. Leaf nodes with deeper (not huge) buffer resulting in much higher costs would defeat the purpose of deploying a Fabric I guess ...
So, in the above-mentioned context, buffers too small tend to overflow in some scenarios and in a high and vary RTT scenario with a higher BW*RTT product it means lower performance. Huge buffers do not help for sure but buffers too small are truly detrimental.
I witnessed an implementation exercise that resulted, amongst other things, in the pretty regular congestion of the Leaf-to-server buffer which ended up being one of the major showstoppers.
Cheers/Ciao
Andrea
Hi (Ciao!) Andrea,
related to your comment "Huge buffers do not help for sure but buffers too small are truly detrimental"
Is there a general guideline on minimum buffering in KB per port speed that a spine or leaf switch should support for deployments with less than 1ms RTT, typical of small DCs where the switch is used as a fabric?
I am doing a lot of TCP flow testing on Ethernet switches via iperf3, and at a given RTT, buffer size can impact a great deal the performance of a given TCP stack, cubic, reno, or DCTCP. I am trying to find a general formula.. or guideline. Yes-- large buffers become very costly in ASICs, and it seems like there is a sweet spot in buffer memory that the switch should support, actually a given port/queue, to enable great TCP performance even under light oversubscription.
Any pointers to relevant literature would be greatly appreciated as well!
Best Regards Giuseppe Scaglione