Leaf-and-Spine Fabrics: Implicit or Explicit Complexity?
During Shawn Zandi’s presentation describing large-scale leaf-and-spine fabrics I got into an interesting conversation with an attendee that claimed it might be simpler to replace parts of a large fabric with large chassis switches (largest boxes offered by multiple vendors support up to 576 40GE or even 100GE ports).
As always, you have to decide between implicit and explicit complexity.
Please note: I don’t claim it’s always better to build your network with 1RU switches instead of using chassis switches. However, you should know what you’re doing (beyond the level of vendor whitepapers) and understand the true implications of your decisions.
Explicit complexity
This is the fabric Shawn described in his presentation. The inner leaf-and-spine fabrics (blue, orange, green, yellow) contain dozens of switches interconnected with fiber cables.
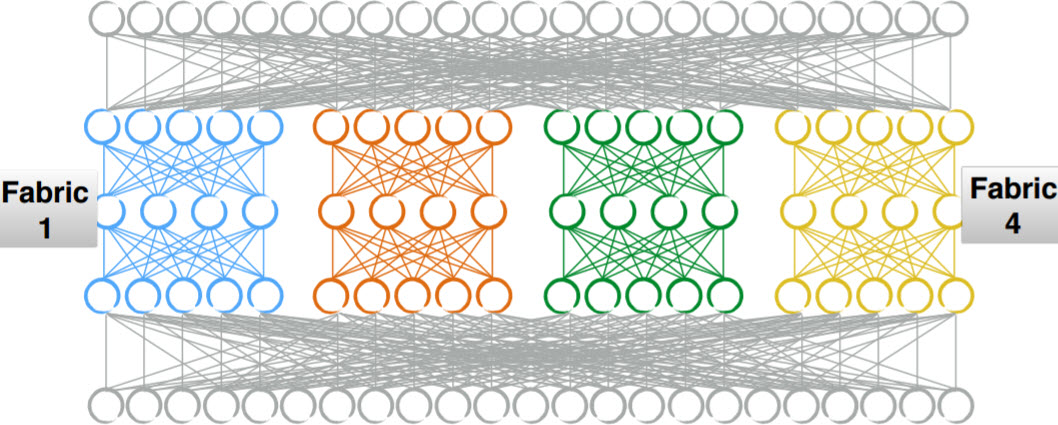
Implicit complexity
Imagine replacing each of the inner leaf-and-spine fabrics with a large chassis switch. Fewer management points, fewer explicit interconnects (transceivers and cables are replaced with intra-chassis connections). Sounds like a great idea.
It depends strikes again
Shawn addressed a few of the challenges of using chassis switches during the presentation:
- You’ll manage hundreds of switches anyway. If you can’t do that automatically, it will turn into a nightmare no matter what. However, once you manage to automate the data center fabric, it doesn’t matter how many switches you have in the core.
- Large chassis switches are precious, and you don’t want them to fail. Ever. Welcome to the morass of ISSU, NSF, graceful restart… Upgrading an individual component of a large fabric is way easier, and all you need is fast failure detection and reasonably fast converging routing protocol. I wrote about this dilemma two years ago, and three years ago, but of course nobody ever listens to those arguments ;)
- Restarting a 1RU switch with a single ASIC is way faster than restarting a complex distributed system with two supervisors, and two dozen linecards and fabric modules (Nexus 7700 anyone?). There’s a rumor a large chassis switch can bring down a cloud provider when restarted at the wrong time ;)
We didn’t even consider pricing – that’s left as an exercise for the reader.
I also asked around and got these points from other engineers with operational experience running very large data center fabrics:
- Make failure domain (blast radius) of any failure be as small as possible. Large chassis switches are a large failure domain that can take down a significant amount of data center bandwidth.
- Scalability of control plane: the ratio of CPU cycles to port bandwidth is much higher in 1RU switches than in large chassis switches with supervisor modules (remember the limited number of spanning tree instances on Nexus 7000?) Worst case, consider the world of containers where containers can come and go rapidly, and there can be hundreds of them per rack.
- Simple fixed-form switches fail in relatively simple ways. Redundant architectures (dual supervisors in fail-over scenario) can fail in arcane ways. Also, two is the worst possible number when it comes to voting… but I guess it would be impossible to persuade the customers to buy three supervisor modules per chassis.
- Ask anyone who's tried to debug a non-working chassis. The protocols they run internally are proprietary, frame formats are equally so, making a hard task even harder.
- With single fixed-form factor switches, you can easily carry cost-effective spares. When things fail, you can replace them quickly with spares and troubleshoot the failing system off production network. Harder to do with expensive chassis switches.
- What if you decide to run custom apps on data center switches (natively on Arista EOS or Cumulus Linux, in containers on Nexus-OS)? App developers and others are more familiar with building distributed apps than with writing something that has to work with each vendor's ISSU model. Compute got rid of ISSU a long time ago.
Anything else? Please write a comment.
Obviously, the leaf-and-spine wiring remains a mess. No wonder Facebook decided to build a chassis switch… but did you notice that they configure and manage every linecard and fabric module separately? Their switch behaves exactly the same way as Shawn’s leaf-and-spine fabric with more stable (and cheaper) wiring.
Want to know more? The update session of the Leaf-and-Spine Fabrics webinar on June 13th will focus on basic design aspects, sample high-level designs (we covered routing and switching design details last year), and multi-stage fabrics.
Well, it depends. :) Even a large enterprise, working 24/7/365, has less busy hours when you can afford losing 16-25% of your bandwidth (with 4-6 chassis switches as spines). In such case, just reload that switch and have a coffee while it's booting.
Disclaimer: large enterprise ≠ public cloud providers (obviously).
What would you think of using those chassis?
We have layer-2 across multiple management switches partially due to the legacy reasons. We are using juniper EX copper switches bonded in virtual chassis, so there is no problem with layer-3, or DHCP support. VC size is limited up to 10 switches, so we have a couple of VC clusters. Each cluster is a separate layer-3 domain.
The alternative solution would be having a dedicated small management network per rack. It has some drawbacks, such as - additional complexity (will have to write additional ansible templates for management switches), subnetting existing management subnet or introducing new management subnets.
Don't know if this is the right blog post to comment this on, but this seems relatively appropiate and it is far newer than the rest. :)
I'm considering deploying Juniper's Virtual Chassis Fabric in my core and I'm facing a dilemma
I've never used VCF before and I don't know how stable it is during operations, how do upgrades really work and what happens when individual switches fail.
I'm so unsure of it all that I'm thinking that I should consider a VCF a single failure domain (even if it is multiple discrete switches) and if we end up going that way then we really need 2x VCFs setup in the datacentre (with all that it entails -- reminds me of FC)
If we move around the issue a little we could say: EVPN VXLAN and an overlay... could I then consider having a single 'fabric'?
In summary: given the tons of different 'fabric' options that we have these days, which ones could be considered a "single failure domain" and which ones not?
Any thoughts?
I know a very large customer who's using two QFabric fabrics per data center (very much like SAN-A/SAN-B), so your idea of using two VCFs is not exactly outlandish.
My guess:
MC-LAG/VC/VCF/QFabric/JunOS Fusion: single
IP Fabric/EVPN VXLAN: not a single
NSX (not really the same thing but you get the idea I hope): I don't know enough, I hope not single!
At the end of the day I guess that if the devices are able to work completely indepedently of each other for all operations (except exchanging routes to the neighbours and forwarding & receiving frames) then its not a single failure domain