Another Spectacular Layer-2 Failure
Matjaž Straus started the SINOG 2 meeting I attended last week with a great story: during the RIPE70 meeting (just as I was flying home), Amsterdam Internet Exchange (AMS-IX) crashed.
Here’s how the AMS-IX failure impacted ATLAS probes (world-wide monitoring system run by RIPE) – no wonder, as RIPE uses AMS-IX for their connectivity.
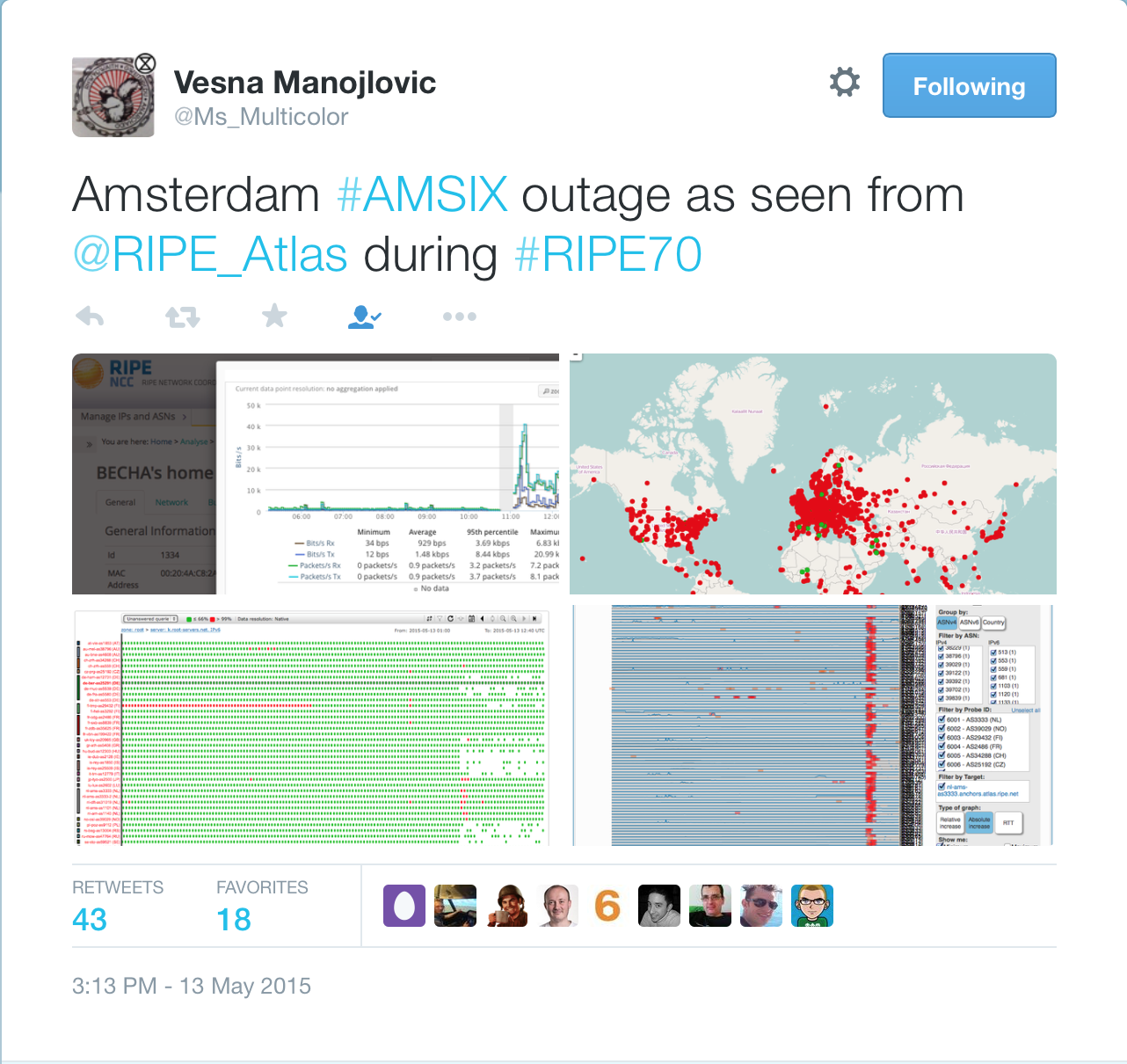
My friend Jeremy Stretch saved the daily traffic graph for posterity in one of his tweets:
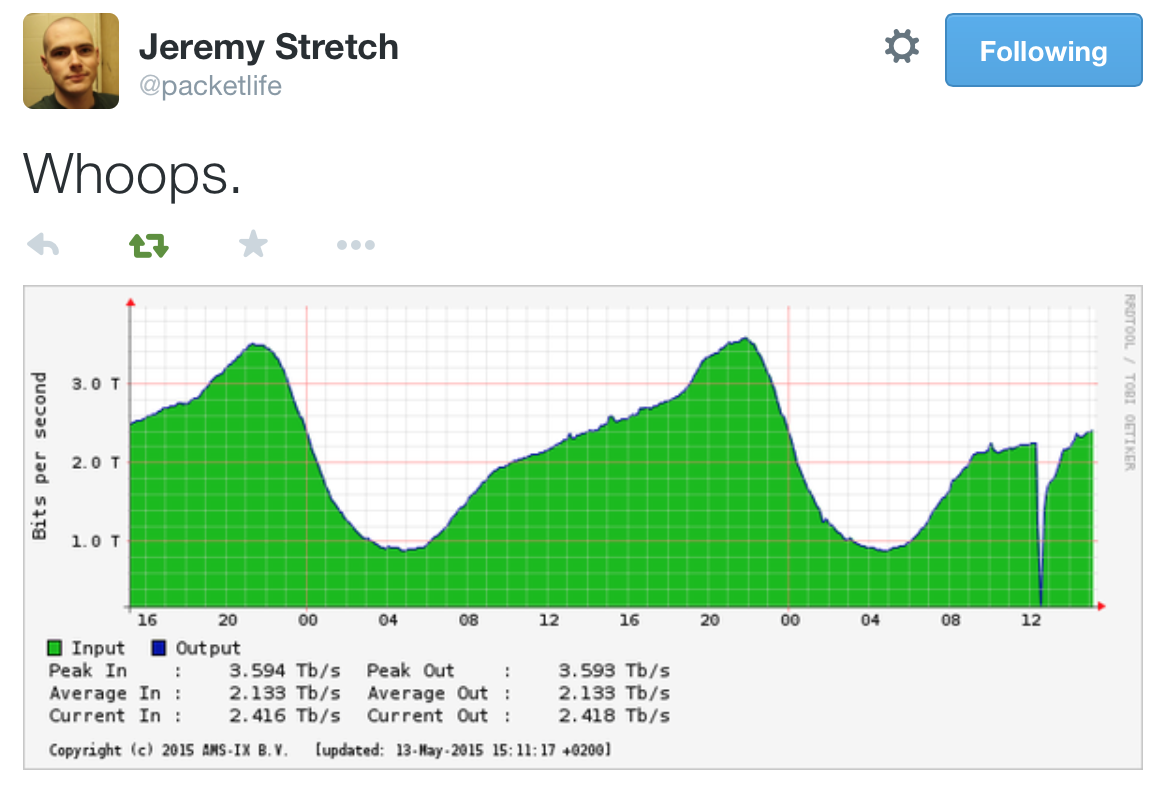
As you can see from the graph, Internet lost 2 Tbps of transit capacity, and many networks using AMS-IX (including some cloud services providers) were severely impacted.
You might wonder what the root cause for the outage was. Here’s the relevant tweet:
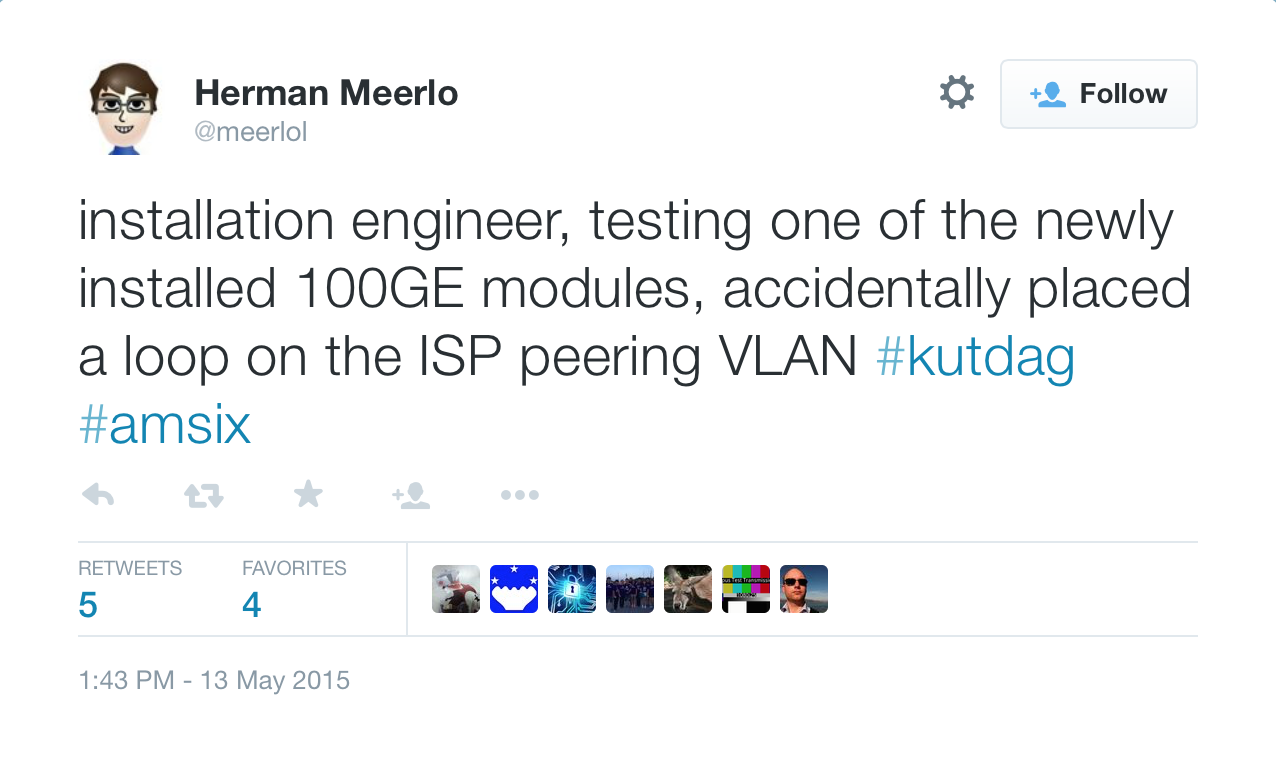
As I said many times before, it’s not a question of whether a large layer-2 fabric will crash, it’s only the question of when and how badly.
Also, keep in mind that there are a few significant differences between AMS-IX and clueless geniuses that tell you to build large layer-2 fabric (hopefully stretched across two data centers):
- AMS-IX is one of the large Internet exchanges and they usually know what they’re doing… and still bad things happen;
- AMS-IX has been in business for almost 20 years and thus has significant operational experience. They’ve learned loads of lessons during past outages and have built their own tools (like ARP sponge) to make their infrastructure more reliable;
- Internet exchanges that don’t want to dictate routing policies of their members have to be layer-2 fabrics (the proof is left as an exercise for the reader), while your data center doesn’t have to be.
Want Even More Horror Stories?
Jay Swan pointed me to a recent Cisco Live presentation (BRKDCT-3102), which documented several interesting layer-2 failures, including a split-brain cluster – I was telling people about these scenarios for years, and it’s so nice to have corroboration from a major vendor (not sure what the evangelists of layer-2 fabrics and DCI solutions working for that same vendor think about that presentation ;).
-bgolab
Multiple mistakes during upgrade, missing communication, loss of monitoring, lack of responsiveness during customer request/complaints.
We have been reassured they are handling these bad behavior, but we still have faults related to humans too often, the RIPE70 case being the top of the iceberg.
Other IX seems to handle things a little better, even if I have to admit their network being a lot simpler.. Nevertheless these fault are not related to net complexity, but rather to user actions.
See recent BGP leak from June 12-th, which caused serious problems for 2 hours:
www.bgpmon.net/massive-route-leak-cause-internet-slowdown/
On a L3 IXP, you'd eventually peer with the router's BGP instance, and add your netowrk's routes to the IXP's routing tables.
Now, you'd want to establish a direct session to another member to offer different routes and discard the common routing information for your prefixes.
Why couldn't you encapsulate that with any protocol supported in hardware by your router (GRE, IPIP, L2TPv3…) ? Of course it looks like a waste of ressources, but it would remove complexity from the IXP itself, making it even more robust…
There are probably other considerations that I'm not aware of as well - in any case, all big IXPs use L2 approach (and some new ones use customer-L2-over-transport-IP for internal stability) - either they're all stupid, or we're missing something ;)