Workload Mobility and Reality: Bandwidth Constraints
People talking about long-distance workload mobility and cloudbursting often forget the physical reality documented in the fallacies of distributed computing. Today we’ll focus on bandwidth, in a follow-up blog post we’ll deal with its ugly cousin latency.
TL&DR summary: If you plan to spread application components across the network without understanding their network requirements, you’ll get the results you deserve.
Every client-server application has to deal with bandwidth constraints. Some of them are reasonably well understood (eventually we get most web sites to work over real-life networks), but the intricacies of connectivity within the application stack usually remain a mystery. After all, most development environments have infinite bandwidth available on the loopback interface.
The Basics
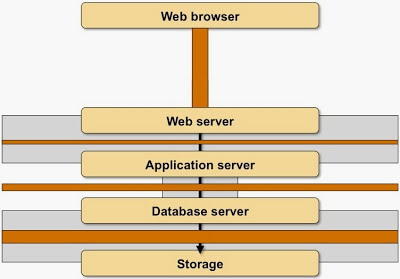
Almost every application stack providing interactive services to its clients uses architecture similar to this one:
Typical web applications organize the functionality of the generic architecture into the following components (one or more of the components might be missing, and there might be interactions with caching and authentication servers). Sometimes these components reside within a single server/VM/container; larger applications tend to spread them across multiple servers.
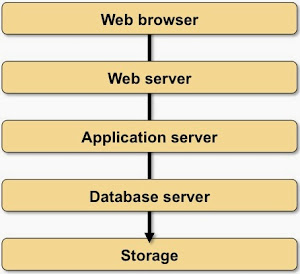
Collecting the Requirements
Whenever someone comes along with the wonderful idea of spreading an application stack across multiple locations, ask him to analyze the network requirements of the application. Let’s focus on the transferred data first: how much data is transferred between application tiers for a typical user interaction?
The results will probably resemble this diagram (which is definitely not to scale): the data transfer toward the web browser is pretty optimized, and there’s lots of data being transferred between the application tiers and between servers and storage nodes to generate the response to the user’s request.
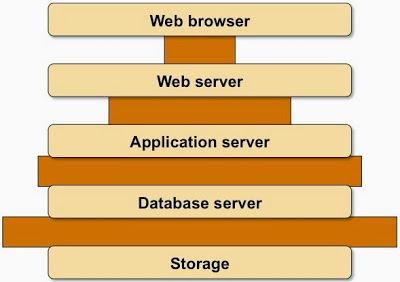
Bandwidth Constraints
Next: add the bandwidth constraints. There’s limited bandwidth between web browser and web server, and almost unlimited bandwidth between the web server and other parts of the application stack:
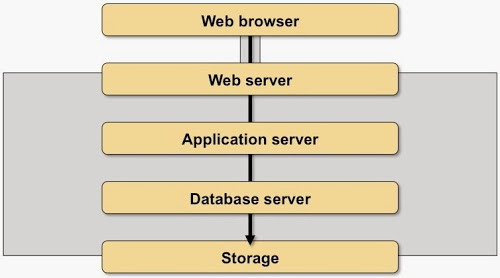
Add the amount of data transferred to the picture and you’ll get an idea about the time it takes to transfer the interaction-related data from storage (or wherever else the original data is stored) to the client (orange bars in the picture):
![]()
Impact of Workload Migration
Finally, change the bandwidth constraints between the components of the application stack based on where these components reside in the new geographically dispersed architecture. For example, the application developers might want to move the web- and application server into the cloud while the security team insists the database server remains in well-protected on-premises data center.
Reduced bandwidth between application- and database server results in increased response time (increased total height of all orange bars). For whatever reason, this result occasionally surprises some people.
Usable bandwidth between application tiers might be lower than the maximum available bandwidth due to TCP constraints - see TCP throughput calculator (based on Mathis formula) for more details (/HT to Julien Goodwin)
![]()
Try to remain realistic when estimating the available bandwidth between application components. If you move your application server to another data center reachable through an 80% utilized 1Gbps link, you won’t get more than 200 Mbps on that link (on a good day… and assuming nobody else gets the same ideas).
Isn’t This Obvious?
It should be, but as one of my fellow networking gurus recently told me: “You have no idea how many times your Do the math before considering long-distance vMotion post saved my day”.
Also, keep in mind that these days bandwidth is no longer the primary constraint. Latency plays a much bigger role than it used to.
"how much data is transferred between application tears for a typical user interaction?"
Did you mean Tiers????
Anyway when dealing with applications sometimes us networkers do have tears.
I guess Freud would have much to say about my lapsus digiti.