First-hop Load Balancing in IPv6
“I want default router address in DHCPv6 options” is a popular religious war on various IPv6 mailing lists. One of the underlying reasons is the need to implement poor man’s first hop load balancing (I won’t even consider the “I don’t want to think, so want IPv6 to behave like IPv4” mentality in this blog post), and as always, the arguments have more to do with suboptimal implementations than true technical needs.
First-hop Load Balancing in IPv4
Imagine a subnet with two (somewhat) equivalent exit points.
Every networking engineer worth her salt would want to use both, and there are several tools in IPv4 world (some worse than others) to do that:
- GLBP, which uses multiple MAC addresses in ARP replies for the same virtual IP address, forcing individual hosts to use one or the other exit point;
- Multiple FHRP (HSRP or VRRP) groups on a single interface combined with different default gateway on the hosts. You could use DHCP in IPv4 world to set the default gateways … and this is the reason some people want to see equivalent functionality in DHCPv6.
Do We Really Need First-hop Load Balancing?
There are plenty of networks that achieve pretty optimal packet forwarding without GLBP or other FHRP tricks – the crucial design decision is the boundary between L2 and L3 forwarding. Layer-3 edge or core switches from almost any vendor offer active/active FHRP deployments, either within a MLAG group or across a whole fabric.
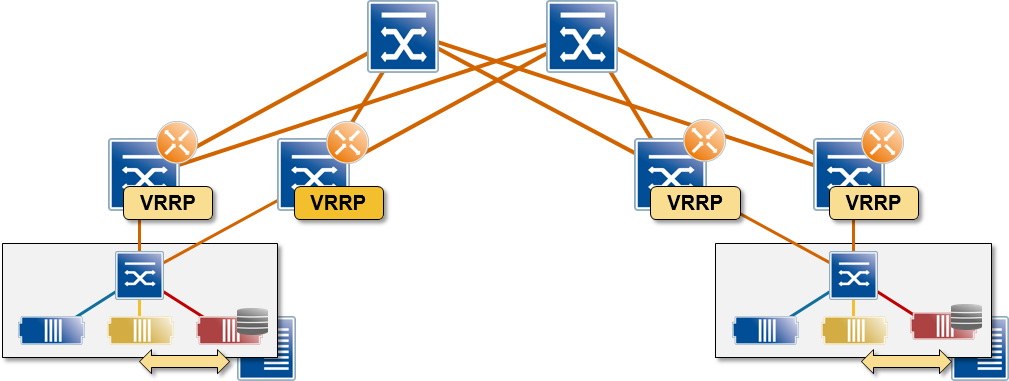
Pure layer-2 networks with layer-3 switches at the egress edge are problematic – anycast MAC addresses don’t work well (just ask anyone trying to implement Microsoft Network Load Balancing); the only kludge left are the above-mentioned FHRP tricks.
Moving to IPv6
IPv6 evangelists will be quick tell how IPv6 does things the right way: all routers connected to a subnet advertise themselves with Router Advertisement messages, and the hosts automatically select the currently available routers. Unfortunately there seems to be a gap between theory and practice – some host IPv6 stacks select one router and either stick with it or flip-flop between them after every incoming RA message.
FHRP tricks we used in IPv4 world don’t work in IPv6. You cannot use DHCPv6 to set host default gateway to the virtual IP address of one of multiple VRRPv3 groups, and GLBP MAC address tricks don’t work because the hosts listen to RA messages.
Keep in mind that networks with layer-3 core should work the same way they did in IPv4 – just make sure you buy switches that support active/active FHRP for IPv6 (oh, your vendor doesn’t support that? Maybe it’s time to vote with your wallet).
And the winner is …
The need for architecturally correct IPv6 first-hop load balancing solutions has been recognized more than a decade ago – the hosts should do ECMP load balancing across all available first-hop routers as defined in RFC 4311 (published more than 8 years ago).
According to RFC 6419 Windows Vista (and later versions) should implement RFC 4311, feedback about Mac OSX and Linux variants is highly appreciated. Thank you!
More information
Check out IPv6 resources page @ ipSpace.net.
- Ed