If Something Can Fail, It Will
During a recent consulting engagement I had an interesting conversation with an application developer that couldn’t understand why a fully redundant data center interconnect cannot guarantee 100% availability.
Background
The customer had a picture-perfect design: layer-3 data center interconnect with two core routers per data center and two inter-DC links from different carriers (supposedly exiting the buildings at different corners and using different paths) ... and yet we were telling the application developers they shouldn’t deploy mission-critical services with components spread over both data centers. Mindboggling, isn’t it?
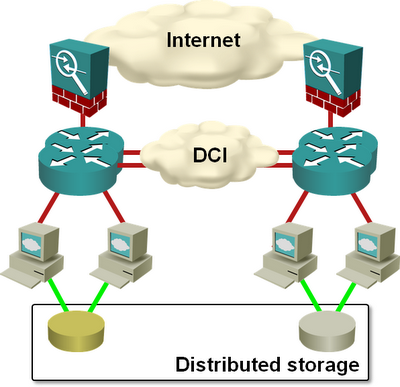
Fully redundant data center design
The Problem
What could possibly go wrong with a fully redundant design?
Every component you're using has a non-zero failure rate; the probability of redundant components failing at the same time is thus non-zero. However, assuming each component is reasonably reliable (let’s say it has 99.9% uptime), the probability of a total failure should be extremely low, right? Wrong. Interconnected things tend to fail at the same time.
An obvious example first: if the software of the core router happens to be susceptible to a killer packet (that causes it to reload), the second core router will probably get the same packet (due to retransmissions) a moment after the first one crashes (see also: BGP bugs)
A slightly less obvious example: almost everyone is using the same maintenance windows. A telco team could start working on one of your links while you’re upgrading the router that uses the other link (Yes, we’ve experienced that. Yes, they forgot to tell us they’d do maintenance, because everything was supposed to be fully redundant anyway).
The application developer still couldn’t believe me, so I told him another true story.
A while ago we were notified that our data center would lose power for two hours due to planned maintenance. No problem, the building we’re in has a diesel generator, and we have plenty of UPS capacity. However, once the power was cut at 3AM, the diesel generator failed to start… and it’s somewhat impossible to find someone to fix it in the middle of the night. Fortunately we had plenty of time to perform a controlled shutdown, but an hour later our data center was dead, even though we had triple redundancy.
The application developer’s response: “Ah, now I get it.” After that, it was pretty easy to agree on what needs to be done to make their data centers and services truly robust.
The fiber circled the campus, eventually coming together on the other side of the campus to the telco demarc, Inside the telco demarc, the fiber came in, plugged into two separate fiber media converters to transition it back to a regular DS-3.
Both media converters were sitting on a shelf in the telco room, plugged into a single household surge suppressor/power strip which was in turn plugged into a wall outlet.
About 12-13 years ago, I was working for a large telco in the UK (not BT), and one hot summer's day (yes, it was a rare hot summer's day!) I was doing some work in one of our major data centers, and when I arrived early in the morning, the data center was taking delivery of a large container.
When I asked what it was about, they said it contained a generator that was going to provide some extra power being as the cooling systems had been working on max, and so the existing power was straining somewhat. I thought to myself "cool" (pun intended) and went inside to start my work for the day.
Later that morning, the fire alarms went off, and suddenly the who DC shut down with only emergency lighting. When I got outside, I found out what had happened: the new container generator had been connected near one of the air intakes for the DC cooling system, and when they fired the generator up, the resulting rather large diesel cloud promptly got sucked into the DC air intakes, at which point the smoke detectors inside the building decided there was a fire and shut everything down.
When I arrived the next day to carry on with my work, they'd installed a fat pipe from the generator exhaust which carried the fumes significantly far away from the DC building itself.
There was plenty of redundancy in that DC, but none of it helped that particular day. :-)
More than enough for redundancy. Here is real story of 15th floor.
1st (or 4 th) elevator was not put into operation because peoples who leave in this buildind do not want to pay for extra elevators (3 is mor than enouth), 2nd stop funtioning for some reason (freezes by software bug), people do not use them (and they do not report the problem to dispatcher) because they have another 2 elevators . On the 15th floor button than evoked elevator crashed (sticked), not very bad, but same day 4th elevator have a problem - someone stuck in an elevator due to light earthquake.
The problem: young mother with a buggy on 15th floor have a unsolvable problem - he can't use elevator any more!
The link ran on diverse paths - one following the coast line and another going via an inland path. At around 3am the line card that terminated the coastal link had started to show errors and then failed. No problem all traffic routed across the inland path. Engineers were notified to go onsite at 9am to replace the faulty card... except that at around 6 or 7am, a backhoe went through the inland path. Next biggest problem was that many providers were reselling services across these links as well.
Now maybe the order was the other way around, but since then the title of this blog post has been my #1 Design Stipulation
in networking, routing instability, any number of events that disrupt multiple fiber paths at once, failures that fail to trigger failure detection... any number of things can, have, and will go wrong.
Power returns. Surrounding suburb lights up, $important_logistics_center turns black ...
As Murphy has it, diesel shut down as intended, but BIG_RELAY connecting $important_logistics_center to either public power or its own private diesel failed to switch back ...
"If something can fail, it will, and at the worst possible moment."
Although I basically agree with "they shouldn’t deploy mission-critical services with components spread over both data centers", what does the DCN Interconnect have to do with this? In the obvious example cited, the services would still be lost even if all the components are in one DCN, right?
Please help enlighten me on the "what needs to be done to make their data centers and services truly robust" too :-) Building a passive DR instead of spreading the functions of services in live-live DCN model above?
Thanks.
JG
Although I basically agree with "they shouldn’t deploy mission-critical services with components spread over both data centers", what does the DCN Interconnect have to do with this? In the obvious example cited, the services would still be lost even if all the components are in one DCN, right?
Please help enlighten me on the "what needs to be done to make their data centers and services truly robust" too :-) Building a passive DR instead of spreading the functions of services in live-live DCN model above?
Thanks.
JG ([email protected])
Until one day our data centre actually lost power - we found out that the building airconditioner was not on a UPS supply. The data centre quickly overheated and everything began shutting down within about 30-40 minutes.
I'm monitoring everything in our bunker data center (formerly an MRI room with thick concrete walls), sitting pretty. But wait, why is it getting so hot in here?? Maybe it's because the air conditioning systems were NOT WIRED to the generator circuits! We had to shut down all systems for over a day and still had some drives fail due to overheating. I won't even talk about what they had to do for the blood bank, or all the condensation on the linoleum floors, with patients slipping and sliding trying to get to the cafeteria.
It was soon found out that the fuel that was suppose to power them up, was stolen.
Well, two clowns of the DC provider had the brilliant idea to clean and sweep the floor in the DCs, unfortunately they used a bucket of water and a cleaning cloth like in the good old days... went all good until one of the two knocked it over...