Why Do Internet Exchanges Need Layer-2?
My tweet about the latest proof of my layer-2 = single failure domain claim has raised numerous questions about the use of bridging (aka switching) within Internet Exchange Points (IXP). Let’s see why most IXPs use L2 switching and why L2 switching is the simplest solution to the problem they’re solving.
What is an Internet Exchange Point?
This section is a gross oversimplification intended for readers who have never been exposed to this topic. Please listen to the Packet Pushers Show 24 for a more in-depth IXP discussion.
Quick summary: IXP is the place where ISPs (member of the IXP) exchange traffic.
Only a few very large transit providers are considered Tier 1 networks (see Renesys blog for yearly updates), everyone else has to buy transit to the rest of the Internet from one or more of the bigger fish in the pond.
The smaller providers are thus interested in minimizing the amount of transit traffic and peering agreements are usually a good mechanism. However, there are usually tens or hundreds of ISPs operating in a given geographical area, and private peering between them would result in an N-square full mesh problem. It’s thus in interest of almost everyone to meet in a common place, connect to a shared infrastructure – Internet Exchange Point – and exchange traffic.
How does an IXP work?
To keep things simple, let’s gloss over the details, and assume that every ISP participating in an IXP brings its own router to premises owned by IXP, and connects it to a shared network infrastructure.
Each ISP has its own AS number and uses BGP to exchange routes with other ISPs. ISPs might decide to peer with everyone, or with a select set of peers, and accept all routes or just a few routes from their peers.
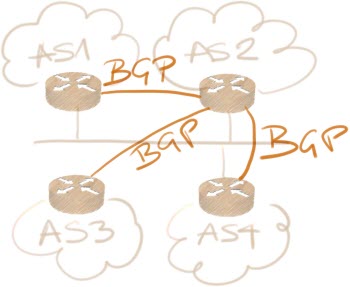
An ISP can also decide to implement local transit agreements across an IXP infrastructure, or prefer routes from one of the peering partners over routes received from another peering partner.
In the example in the following diagram, AS 3 receives two paths toward AS X, one from AS 2, one from AS 4. It might prefer the route through AS 4, whereas AS 1 cannot use that route, since it’s not peering with AS 4 (unless AS 2 is willing to provide transit services).

To summarize: each ISP participating in an IXP might have its own BGP routing policy, resulting in an individualized view of the local parts of the Internet.
IP- or MAC-based forwarding in an IXP?
In the previous diagrams, the IXP infrastructure was drawn as a symbolic Ethernet cable, and some very early IXPs were actually implemented that way, using either thick coax or Ethernet hubs.
Today we could use L2 or L3 switches to implement the IXP infrastructure. Ethernet-based IXP design is obvious and simple (while we’re still glossing over details): all ISP routers connect to a switched LAN.
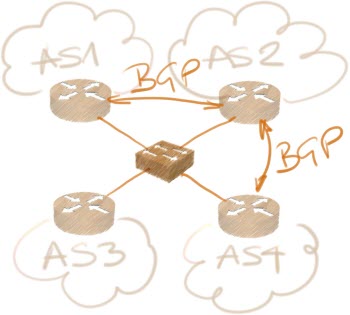
We all know bridging doesn’t scale, so one might want to implement IP-based IXP infrastructure – all ISP routers would be connected to an IXP router, exchange BGP routes with it, and potentially still run BGP between themselves to support various routing policies.

This scenario might work as long as all ISPs share the same routing policy. IP uses hop-by-hop destination-only forwarding (tunnels are obvious exceptions triggering the scholastic Is MPLS Tunneling problem), and thus it’s impossible for the IXP router to forward packets from different ISPs based on their preferred routing policy.
Going back to our example: if the IXP router decides to prefer route to AS X going through AS 2, it’s impossible for AS 3 to forward the packets toward AS X through AS 4. While the router in AS 3 might decide to prefer the path advertised by AS 4, once the IP packets leave it and arrive at the IXP router, the IXP router will make its own independent forwarding decision and send the packets to AS 2.
Conclusion: Internet Exchange Points are one of the rare scenarios where large L2 domains actually make sense, and once they grow and get distributed across multiple locations (example: AMS-IX, LINX), they get exposed to the same set of problems all large L2 networks face, including occasional meltdowns.
And we all know how much high speed router interfaces are.
Just my 2c.
In terms of routes, yes this would be too much for an entry level floor switch like a 3560, but hardly a big job for a modern software based router like the ISR G2's.
As a point of reference the ISP I operate pulls about 1/3 of our total traffic from the PIPE Sydney Peering here in Australia, and we get just a shade over 10,000 IPv4 routes.
The savings we make from that particular peering link instead of purchasing more upstream capacity saves the cost of probably half a dozen 2900s each month alone. So it's really a no brainer, and if I had to put a dedicated router in to do this function there would be no issue justifying the capital spend.
If you aren't saving enough money from peering to at least fund the very modest hardware required then it's probably marginal in so far as it even being worth your while setting up in the first place.
simplified routing, as all they need to do is bridge few mac(router) over large l2 domain.
and still have TE to handle their huge traffic volume.
Also, If I read you correctly, the IP-based IXP you mention sounds pretty close to a route server service. Difference is, it still uses the "unscalable" L2 domain, but it *does* provide server based filtering for members to peruse, usually either via BGP communities or IRRdb expressions, so they can pretty much apply distinct routing policies.
The real difference between IP-based IXP and route server service is that the route server is optional. I can decide not to use a route server, use it as a backup mechanism, or augment it with direct peerings, whereas IP-based IXP enforces a common routing policy in the forwarding plane.
1. The IXP can provide an "L3 mesh" which is a lot more stable
2. The IP prefix scale requirements on the IXP router would be pretty small (would mimic the IGP scale which is well within the bounds supported by most DC switches)
Now perhaps the availability of a robust BGP stack and GRE support on DC switches does not leave the IXPs with a lot of vendor choice, but surely the option is worth exploring.
Kirill
It didn't mention in the presentation but AMS-IX has been using MPLS/VPLS for the last 3 years.
That could be brought to scale, right?
Remember: in an IP network, each router performs an independent L3 lookup on the destination IP address.
I just thought it would be good to tell the whole world about his good work and how genuine he is, i wasn't thinking i could get any help because of my past experiences with other fake casters who could not bring my husband back to me and they all promised heaven and earth and all they are able to do is ask for more money all the time until i met with this man. he does all spells, Love spells, money spells, lottery spells e.t.c i wish i can save every one who is in those casters trap right now because i went though hell thinking and hoping they could help me.i recommend MERUJA OWO for any kind of help you want.
his email address is: [email protected]
if you want to ask me anything my e-mail is: [email protected]
Kind Regards!