Full Mesh Is the Worst Possible Fabric Architecture
One of the answers you get from some of the vendors selling you data center fabrics is “you can use any topology you wish” and then they start to rattle off an impressive list of buzzword-bingo-winning terms like full mesh, hypercube and Clos fabric. While full mesh sounds like a great idea (after all, what could possibly go wrong if every switch can talk directly to any other switch), it’s actually the worst possible architecture (apart from the fully randomized Monkey Design).
Imagine you just bought a bunch (let’s say eight, to keep the math simple) of typical data center switches. Most of them use the same chipset today, so you probably got 48x10GE ports and 4x40GE ports1 that you can split into 16x10GE ports. Using the pretty standard 1:3 oversubscription, you dedicate 48 ports for server connections and 16 ports for intra-fabric connectivity … and you wire them in a full mesh (next diagram), giving you 20 Gbps of bandwidth between any two switches.
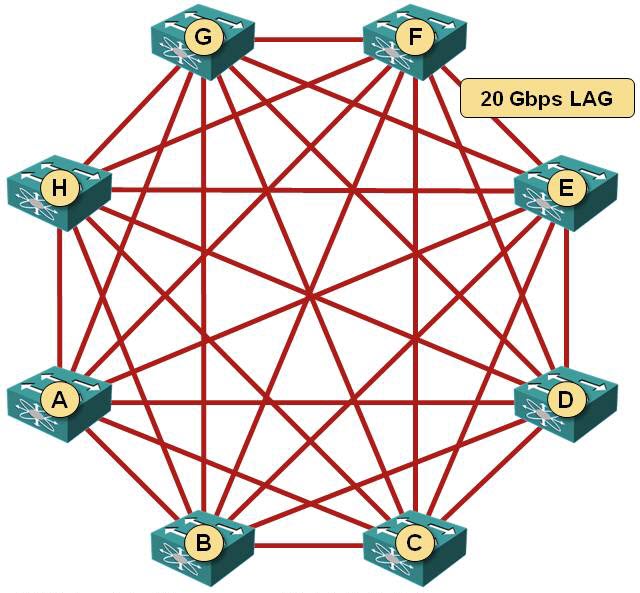
Full mesh between leaf switches
Guess what … unless you have a perfectly symmetrical traffic pattern, you’ve just wasted most of the intra-fabric bandwidth. For example, if you’re doing a lot of vMotion between servers attached to switches A and B, the maximum throughput you can get is 20 Gbps (even though you have 160 Gbps of uplink bandwidth on every single switch).
Now let’s burn a bit more budget: buy two more switches with 40GE ports, and wire all ten of them in a Clos fabric. You’ll get 80 Gbps of uplink bandwidth from each edge switch to each core switch.
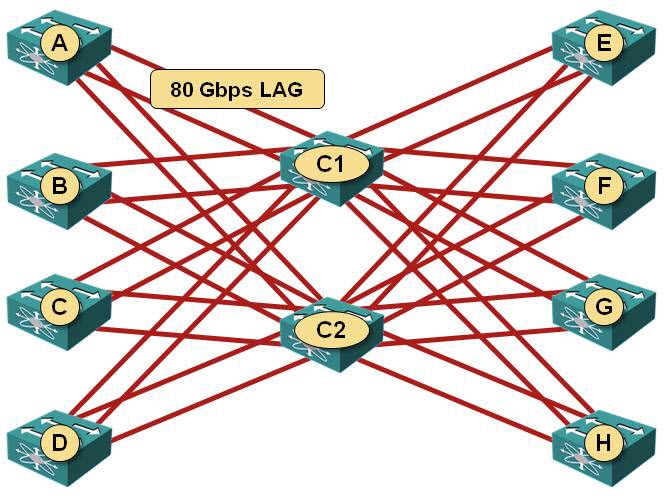
Clos fabric
Have we gained anything (apart from some goodwill from our friendly vendor/system integrator)?
Actually we did – using the Clos fabric you get a maximum of 160 Gbps between any pair of edge switches. Obviously the maximum amount of traffic any edge switch can send into the fabric or receive from it is still limited to 160 Gbps2, but we’re no longer limiting our ability to use all available bandwidth.
Now shake the whole thing a bit, let the edge switches “fall to the floor” and you have the traditional 2-tier data center network design. Maybe we weren’t so stupid after all …
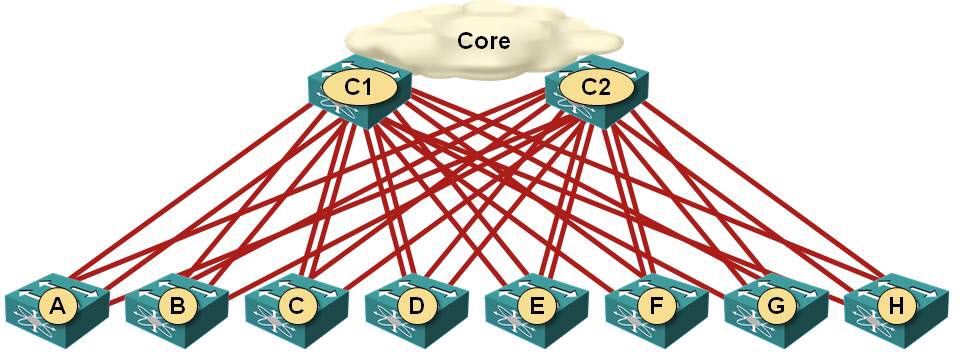
Leaf-and-spine fabric
More Information
Since publishing this blog post I created a whole series of webinars on data center fabrics, leaf-and-spine fabric architectures, and EVPN.
Revision History
- 2023-01-15
- Mentioned 25GE/100GE ports and cleaned up the wording.
-
… or 48 x 25GE ports and 4 x 100GE ports if you’re reading this is 2020s ↩︎
-
Unless you use unicorn-based OpenFlow powered by tachyons. ↩︎
It is also possibly to utilize practically full capacity in the fully meshed fabric by using adaptive routing methods, which are, however, harder to implement. For instance, you can run a full-mesh of MPLE-TE tunnels ;) Though this model has way too slow response time to be used in data-center.
Overall, adaptive routing has been a big area of research in 70-90s for HPC systems, and a lot of interesting results could be borrowed from there. It's just that modern DC's are built from commodity gear which normally has pretty limited functionality.
In a proper CLOS Leaf/Spine topology you can scale the fabric pretty large using existing 1RU and 2RU switches.
And I will in fairness say that there could be applications written in the future that take advantage of more full mesh designs. And it does depend on your design goals, bandwidth vs latency vs consistency vs resiliency etc. As Plapukhov stated above, there are ways to do full mesh to one's benefit today. That is just not how we do things today in datacenters, and my guess is we won't any time soon.
But for the most part ever since Charles Clos released his work in 1953 http://en.wikipedia.org/wiki/Clos_network communications have proven time and time again that a CLOS based architecture gives the best performance.
This is illustrated (somewhat humorously) by the fact that if you build a full mesh fabric today that most if not all of the switches you would be using to do so have inside them asics on a board that are in CLOS configuration.
For most applications today CLOS ROCKS.
I personally do talk in some of my presentations that things like TRILL mean you can more safely look at new topologies like full mesh and others and that we may see more of that in the future. But I know of no datacenter application today that would be helped by a full mesh topology.
If you can point me to where you saw this I'm more than happy to look into it. It's very possible that it's simply the miss use of the phrase "full mesh".
I wasn't actually holding back - I just wanted to make a quick comparison between two topologies. There will be more blog posts on Clos fabrics.
Also, if you do have something on ASICs you can share, that would be most appreciated. It's getting harder and harder to get access to HW documentation without NDA (or similar restrictions).
Not to go too far off of the topic of this blog, the main issue that jumped out to me was the limitation of only 24 switches in a VCS fabric. If 2+ switches are used as spine nodes, that would leave 22 or less for leaf nodes. I guess that led me to the thought that you would want to be able to use all available nodes as leaf nodes, and my mind constructed the idea of a full mesh to accomplish this.
Given that their largest switch supporting VCS (that I know of) is the VDX6730-76 with 60 ethernet ports, I would assume 4 spine nodes to allow full bandwidth within the fabric (2 spine nodes wouldn't have enough ports for 4 uplinks each from all 22 leaf nodes). That leaves only 20 leave nodes, with 52 ports each as your maximum access port count, and even then it's at 6.5:1 oversubscription.
http://www.plexxi.com/