Beware of fabric-wide Link Aggregation Groups
Fernando made a very valid comment to my Monkey Design Still Doesn’t Work Well post: if we would add a few more links between edge and core (fabric) switches to that network, we might get optimal bandwidth utilization in the core. As it turns out, that’s not the case.
Here is how you could use Fernando’s ideas to extend our network: add links A-D and E-D, and enable LACP on those links (without LACP, one of the edge-to-core links would be blocked by STP which is still needed outside of the fabric … regardless of what some of the vendors think).
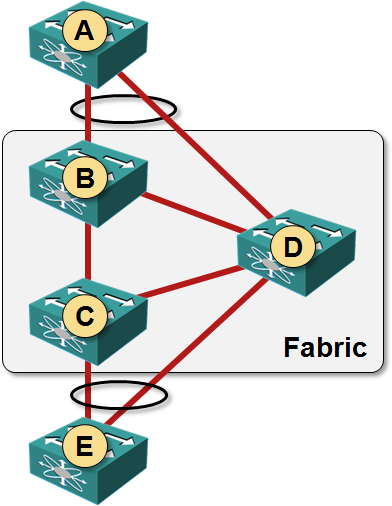
Note that you need a solution that implements fabric-wide LAG for this network to work. Brocade has such a solution, and you could use the 4-node IRF fabric (or Juniper’s Virtual Chassis). You can’t use Nexus 5K/7K or any other two-chassis MLAG solution as the network core if you want to implement this network (NX-OS can terminate LAGs on pairs of switches (VPC peers), not on any two switches in the FabricPath).
Assuming the fabric vendor did a good job and implemented equal-cost multipath within the fabric, let’s see how the traffic from A to E will flow:
- A would split the traffic across both links in the LAG (A has no idea LAG terminates on two switches). B and D will both get 50% of the traffic.
Remember that most switches don’t offer per-packet load balancing on layer-2 (exception: Brocade can do per-packet load balancing on intra-fabric links) – you can get a traffic split close to 50-50 ratio only if you have many flows and a bit of luck.
- B has two equal-cost paths to E and would thus perform equal-cost load balancing. Half of the traffic arriving from A would be sent to C, the other half to D.
- D sees E as being directly connected and sends all traffic directly to E (otherwise you could get some interesting traffic loops).
End result: 75% of the traffic is sent over the D-E link and only 25% of the traffic goes over C-E link.
Summary
Be careful with your fabric design. Just because you can connect Link Aggregation Group (aka Port Channel) member links to any switch in the fabric doesn’t mean that you should (or that you’ll get the results you expect).