Do we need DHCPv6 Relay Redundancy?
Instead of drinking beer and lab-testing vodka during the PLNOG party I enjoyed DHCPv6 discussions with Tomasz Mrugalski, the “master-of-last-resort” for the ISC’s DHCPv6 server. I mentioned my favorite DHCPv6 relay problem (relay redundancy) and while we immediately agreed I’m right (from the academic perspective), he brought up an interesting question – is this really an operational problem?
Some intro first
I wrote about DHCPv6 relaying before, but let’s revisit how it works:
- CPE sends DHCPv6 solicit message to figure out who the DHCPv6 server is;
- PE relays the message toward the DHCPv6 server (DHCPv6 relaying is not a simple packet forwarding, DHCPv6 relay wraps the original message into a new envelope);
- DHCPv6 server replies with the advertise message which is relayed to the CPE by the PE-router;
- CPE might get multiple advertise messages and selects one of the potential DHCPv6 servers;
- CPE sends DHCPv6 request message with IA-PD option to the PE-router.
- PE-router relays the message to the DHCPv6 server.
- DHCPv6 server allocates a prefix to the CPE router and returns the prefix in the DHCPv6 reply message.
- PE-router receives the reply message;
- PE-router installs a static route for the delegated prefix pointing toward the CPE-router;
- PE-router forwards the DHCPv6 reply message to the CPE;
- CPE starts using the delegated prefix to address its interfaces.
A brief overview of the process (actually, just the second half of it) is shown in the following diagram:
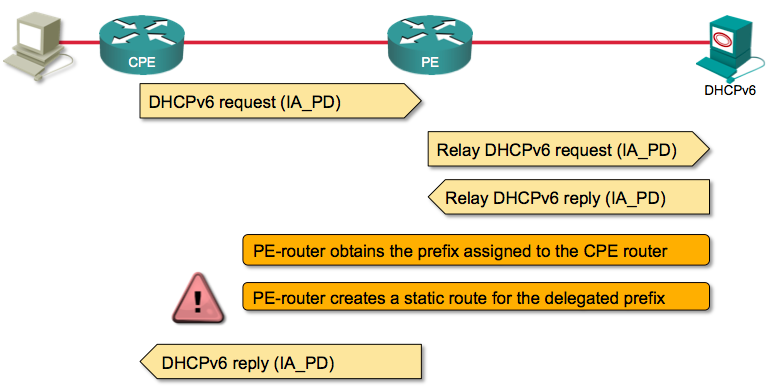
Relaying in Redundantly Designed Networks
Now imagine you have a switched layer-2 access network and two PE-routers connected to it for redundancy purposes.
This is not a good idea – the first-hop switch in the service provider network should be a layer-3 device for security reasons.
The CPE router still sends a single solicit message, but each PE-router relays that to the DHCPv6 server. DHCPv6 server will send back two advertise messages, both will get relayed to the CPE router (each PE-router will relay the response to its relayed solicit message), and the CPE router will pick one or the other.
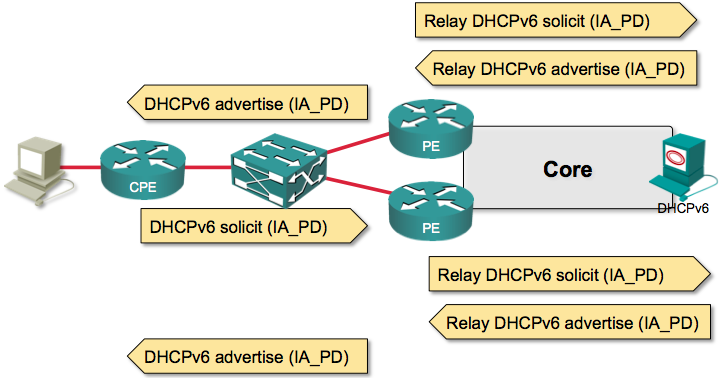
The CPE router subsequently sends a DHCPv6 request message to the selected PE-router (acting as a relay), eventually gets back the delegated prefix, and the PE-router has a static route … but the other PE-router is not aware of what’s going on.
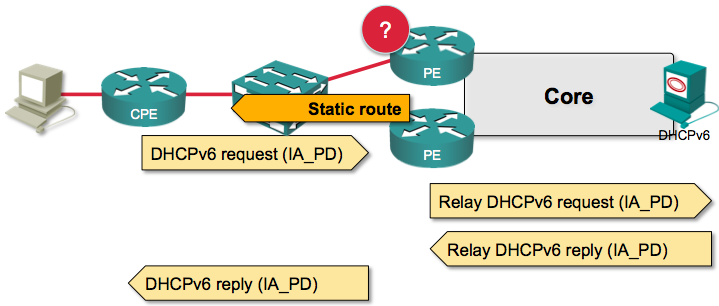
The Problem
One of the problems is obvious – you might get suboptimal routing, because one of the PE-routers lacks routes toward destination(s) with next hop in directly connected access network … but we can solve that with routing protocols that support third-party next hops.
However, matters get much worse if one of the PE-routers crashes. The static routes are lost (they can be regained with BULK LEASE mechanism once the PE-router completes the reload), but in the meantime the CPE devices served by that PE-router have no connectivity, even though you have a totally redundant access network.
The Question
Is this scenario relevant? Do you use something like that in your access network? Would you be impacted? Write a comment – Tomasz needs real-life use cases.
More information
- Enterprise IPv6 – the first steps webinar gives you an overview of IPv6 technologies, 4-to-6 migration alternatives and design recommendations.
- Service Provider IPv6 Introduction is an introductory-level webinar targeting ISP environments.
- Building Large IPv6 Service Provider Networks webinar describes access- and core-layer technologies and designs.
All three webinars (and numerous others) are part of the yearly subscription.
in the title you suggest a solution, but it might not be the only one.
Markus and I wrote a draft on state maintenance for PD a while back.
http://tools.ietf.org/id/draft-stenberg-v6ops-pd-route-maintenance-00.txt
my favourite approach would be a simple BFD echo mechanism done by the CPE.
There's part of the description that is wrong: "The CPE router subsequently sends a DHCPv6 request message to the selected PE-router (acting as a relay), eventually gets back the delegated prefix, and the PE-router has a static route … but the other PE-router is not aware of what’s going on.". What actually happens is: CPE chooses one response, but that is still usually multicast message (with a DUID that represents chosen server). Both relays (both PE routers) gets it and both forward them to a server. Server will get two copies of the same message and will generate two answers. All reasonable servers will generate the same answer twice, but each answer will be relayed back via appropriate relay (the one that transmitted this particular copy of the message). So it turns out that both relays will get the information.
You may possible get into described problems (sort of) if you use unicast option that allows CPEs to contact server directly, bypassing relays. However, my understanding is that no sane network operator would do that and expect his relays to operate properly.
I still think that the original solution I proposed will work. Each relay knows relay-ids of itself and the other relay. If it crashes, it can use bulk leasequery to retrieve lost routes, using query by relay-id.
Other minor corrections:
1. It is bulk leasequery mechanism, not bulk lease.
2. There was beer involved during some PLNOG discussions, *including* this one :)