Blog Posts in October 2010
Interesting links (2010-10-31)
This set of links is somewhat different: they all deal with IT, but mostly with non-technical part of it.
Kevin Bovis @ Etherealmind continues a series of great insightful articles with Network Design – Creativity and Compromise. Must-read for anyone striving to be involved in network design.
The IT Disconnect by Tom Carpenter tackles one of the fundamental IT issues: we’re too busy dealing with our problems to focus on the problems of those paying us to deliver the service.
Chuck Hollis is describing stupid approaches customer use to structure their RFPs. If you were ever working for a vendor or system integrator, you’ll find it hilarious.
Mike Workman is dealing with the same problem from the customer perspective: “Why is it so hard to shop?”
DHCPv6 relaying: another trouble spot?
My DHCPv6+PPPoE post received a very comprehensive comment from Ole Troan (thank you!) in which he explains the context in which DHCPv6 was developed (a mechanism to give a static IPv6 prefix to a customer) and its intended usage (as the prefix is static, it should have a very long lifetime).
However, when you deploy DHCPv6 in some modern access networks (it’s not just PPPoE, Carrier Ethernet fares no better), you might experience subtle problems. Let’s start with a step-by-step description of how DHCPv6 works:
DMVPN Scalability
Alexander sent me a very valid question: “Do you cover scalability problems in your DMVPN webinar?”. Of course I do, more than half of the webinar is devoted to them.
As you know, DMVPN is a combination of multiple technologies, including ISAKMP (key exchange), IPsec (encryption), GRE (tunneling), NHRP (tunnel endpoint resolution) and a routing protocol. Any one of these can be a limiting factor:
DHCPv6 over PPPoE: Total disaster
Every time someone throws me an IPv6 curveball, I’m surprised when I discover another huge can of worms (I guess I should have learned by now). This time it started pretty innocently with a seemingly simple PPPoE question:
What happens if an ISP decides to assign dynamic IPv6 subnets? With static assignment, the whole stuff is pretty straight-forward due to ND, RA & DHCPv6, but if dynamic addresses are used, what happens if the subnet changes - how will the change be propagated to the end-user devices? The whole thing is no problem today due to the usage of NAT / PAT...
LAN address allocation with changing DHCPv6 prefix is definitely a major problem, but didn’t seem insurmountable. After all, you can tweak RA timers on the LAN interface, so even though the prefix delegated through DHCPv6 would change, the LAN clients would pick up the change pretty quickly. WRONG ... at least if you use Cisco IOS.
Solution: EIGRP Summarization Breaks Phase 2 DMVPN
Last week I posted an interesting challenge: what happens if you configure route summarization in a Phase 2 DMVPN network? The only response came from an anonymous contributor strongly suspected to be a routing/DMVPN expert working for a CCIE-related training company.
The anonymous responder was somewhat cryptic, so let’s do a step-by-step explanation. We’ll use a simple 3-router network; C1 is hub, R2 and R3 are spokes.
QoS over MPLS/VPN Networks
A while ago John McManus wrote a great DSCP QoS Over MPLS Thoughts article at Etherealmind blog explaining how 6-bit IP DSCP value gets mapped into 3-bit MPLS EXP bits (now renamed to Traffic Class field). The most important lesson from his post should be “there is no direct DSCP-to-EXP mapping and you have to coordinate your ideas with the SP”. Let’s dig deeper into the SP architecture to truly understand the complexities of this topic.
We’ll start with a reference diagram: user traffic is flowing from Site-A to Site-B and the Service Provider is offering MPLS/VPN service between PE-A and PE-B. Traffic from multiple customer sites (including Site-A) is concentrated at SW-A and passed in individual VLANs to PE-A.
Yes, it's still the same blog
Don't worry, you're still reading the same blog ... finally I found some time to implement the new design that has been waiting in my Inbox for over a month. Numerous glitches still have to be fixed, but at least the major changes are done.
How do you like the new design? Please share your opinion in the comments. Thank you!
Coping with long-distance vMotion requests
During the last Data Center webinar I got an interesting question when describing the inherent problems of long-distance vMotion: “OK, I understand all the implications, but how do I persuade my server admins?”
The best answer I’ve heard so far came from an old battle-hardened networking guru: “Well, let them try”.
EIGRP Summarization in DMVPN Phase 2 Networks
Imagine the following scenario: you’ve configured a Phase 2 DMVPN network with a hub and a few spokes. DMVPN is configured properly, IPSec and NHRP are working, you can ping all around the DMVPN cloud.
Next step: configuring EIGRP. You know you have to disable EIGRP split horizon and EIGRP next-hop processing. You even remember to configure interface bandwidth.
Someone told you to minimize the EIGRP routing traffic, so you use EIGRP stub routers on the spokes and route summarization on the hub router. The final EIGRP configuration is shown in the following diagram:
Data Center Interconnect (DCI) encryption
Brad sent me an interesting DCI encryption question a while ago. Our discussion started with:
We have a pair of 10GbE links between our data centers. We talked to a hardware encryption vendor who told us our L3 EIGRP DCI could not be used and we would have to convert it to a pure Layer 2 link. This doesn't make sense to me as our hand-off into the carrier network is 10GbE; couldn't we just insert the Ethernet encryptor as a "transparent" device connected to our routed port ?
The whole thing obviously started as a layering confusion. Brad is routing traffic between his data centers (the long-distance vMotion demon hasn’t visited his server admins yet), so he’s talking about L3 DCI.
The encryptor vendor has a different perspective and sent him the following requirements:
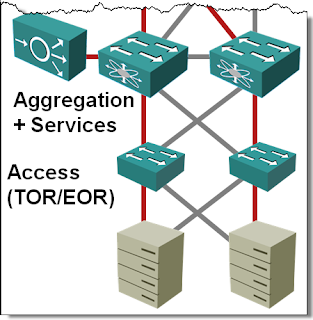
Multi-chassis Link Aggregation: Stacking on Steroids
In the Multi-chassis Link Aggregation (MLAG) Basics post I’ve described how you can use (usually vendor-proprietary) technologies to bundle links connected to two upstream switches into a single logical channel, bypassing the Spanning Tree Protocol (STP) port blocking. While every vendor takes a different approach to MLAG, there are only a few architectures that you’ll see. Let’s start with the most obvious one: stacking on steroids.
PFC/ETS and storage traffic: the real story
Data Center Ethernet (or DCB or CEE, depending on who you are) is a hot story these days and it’s no wonder that misconceptions galore. However, when I hear several CCIEs I highly respect talk about “Priority Flow Control can be used to stop all the other traffic when storage needs more bandwidth”, I get worried. Exactly the opposite is true: you use PFC to stop the overzealous storage traffic (primarily FCoE, but also iSCSI) to make sure you don’t drop it.
PPPoE Testbed
During my last Building IPv6 Service Provider Core webinar I got a lot of questions about IPv6 over PPPoE (obviously we’re close to widespread IPv6 implementation; I never got PPPoE questions before). I wanted to test various scenarios in my IPv6 lab and thus enabled PPPoE on an Ethernet link between CE and PE routers.
This time I wanted to test multiple configurations in parallel ... no problem thanks versatile PPPoE implementation in Cisco.
Ethernet versus FC: surfer versus banker
It looks like everyone (and their dog) is writing about DCB and FCoE these days, but occasionally we get a fresh thought: Ron Fuller compares FC/Ethernet to East/West coast mentality. Great analogy ;)
Ethernet inter-frame gap: Another living fossil?
Recently I’ve stumbled across a year-old post by James Ventre describing the reasons output rate on an Ethernet-type interface (as reported by the router) never reaches the actual interface speed. One of them: inter-frame/packet gap (IPG).
I was stunned ... I remember very well the early days of thick/thin coax Ethernet when the IPG was needed for proper carrier sense/collision avoidance detection (probability of a collision decreases drastically as you introduce IPG), but on a high-speed point-to-point full duplex link? You must be kidding.
DMVPN: from Concept to Pilot in 36 Hours
Participants of my webinars might remember the concept of on-site workshops that I kept mentioning until the COVID-19 pandemic brought my in-person business to a halt. Almost a decade before that calamity, the networking team from a large multinational company had decided to test it in practice and invited me for a 3-day DMVPN workshop.
The agenda of these workshops is usually pretty simple:
- Day 1: technology overview and review of the existing network design/challenges.
- Day 2: work on proposed new network design.
- Day 3: tying up loose ends and preparations for pilot/migration.
We agreed on a tentative agenda along these lines and I prepared the material for the technology overview using parts of my Choose the Optimal VPN Service webinar (to compare DMVPN with other VPN solutions) and the DMVPN webinar. Oh boy, was I in for a surprise.
Multiple EIGRP Autonomous Systems in a VRF
A while ago Ron sent me an intriguing question: “Is it possible to have two EIGRP AS numbers in the same VRF?” Obviously he’s working on a network with multiple EIGRP processes (not an uncommon pre-MPLS/VPN solution; I did a network design along the same lines almost 20 years ago).
It’s easy to run multiple EIGRP autonomous systems in the global IP routing table; just create more than one EIGRP process. They can even run over the same set of interfaces. EIGRP-in-a-VRF implementation is slightly different; you configure an address family within another EIGRP process and (optionally) specify an AS number that does not have to match the AS number of the EIGRP process.
Interesting links (2010-10-03)
Ethan Banks is continuing his deliberations on going independent (or not). He’s definitely collected some very interesting feedback.
Stephen Foskett shared a link to an interesting blog post: “How to Pitch A Tech Blogger”. A must read for vendors attending Tech Field Day (have you noticed there is no mention of Gartner or IDC? ;)
Another great read from Stephen: a large dose of common sense hidden under the “Four Fundamental Best Practices for Enterprise IT” title. I wonder if the vendors touting TRILL and inter-DC bridging with long-distance vMotion ever got to the “Minimize Complexity” part, let alone “Align Expectations with Reality”.
The “Hack The Stack Or Go On a Bender With a Vendor” tackles the age-old dilemma: build or buy, as it applies to the cloudy environments.
Brad Hedlund continues his series of great UCS posts with the explanation of UCS Fabric Failover feature.
Jeremy Gaddis documented his impressions of the Net Field Day 2010 event: day 1 and day 2. If you’ve missed NFD-related posts, Stephen Foskett makes sure you’re able to read them all via his Net Field Day 2010 Links page.
… updated on Sunday, May 8, 2022 09:21 UTC
Multi-Chassis Link Aggregation (MLAG) Basics
If you ask any networking engineer building layer-2 fabrics the traditional way about his worst pains, I’m positive Spanning Tree Protocol (STP) will be very high on the shortlist. In a well-designed fully redundant hierarchical bridged network where every device connects to at least two devices higher in the hierarchy, you lose half the bandwidth to STP loop prevention whims.