Category: Switching
vSwitch in Multi-chassis Link Aggregation (MLAG) environment
Yesterday I described how the lack of LACP support in VMware’s vSwitch and vDS can limit the load balancing options offered by the upstream switches. The situation gets totally out-of-hand when you connect an ESX server with two uplinks to two (or more) switches that are part of a Multi-chassis Link Aggregation (MLAG) cluster.
Let’s expand the small network described in the previous post a bit, adding a second ESX server and another switch. Both ESX servers are connected to both switches (resulting in a fully redundant design) and the switches have been configured as a MLAG cluster. Link aggregation is not used between the physical switches and ESX servers due to lack of LACP support in ESX.
Intelligent Redundant Framework (IRF) – Stacking as Usual
When I was listening to the Intelligent Redundant Framework (IRF) presentation from HP during the Tech Field Day 2010 and read the HP/H3C IRF 2.0 whitepaper afterwards, IRF looked like a technology sent straight from Data Center heavens: you could build a single unified fabric with optimal L2 and L3 forwarding that spans the whole data center (I was somewhat skeptical about their multi-DC vision) and behaves like a single managed entity.
No wonder I started drawing the following highly optimistic diagram when creating materials for the Data Center 3.0 webinar, which includes information on Multi-Chassis Link Aggregation (MLAG) technologies from numerous vendors.
Multi-Chassis Link Aggregation (MLAG) and Hot Potato Switching
There are two reasons one would bundle parallel Ethernet links into a port channel (official term is Link Aggregation Group):
- Transforming parallel links into a single logical link bypasses Spanning Tree Protocol loop avoidance logic; all links belonging to the port channel can be active at the same time (see also: Multi-Chassis Link Aggregation basics).
- Load sharing across parallel links in a port channel increases the total bandwidth available between adjacent L2 switches or between routers/hosts and switches.
Ethan Banks wrote an excellent explanation of traditional port channel caveats (proving that 1+1 sometimes does not equal 2); things get way worse when you start using Multi-Chassis Link Aggregation due to hot potato switching (the switch tries to forward packets toward destination MAC address as soon as possible) used by all MLAG implementations I’m familiar with.
VMware Virtual Switch: no need for STP
During the Data Center 3.0 webinar I always mention that you can connect a VMware ESX server (with embedded virtual switch) to the network through multiple active uplinks without link aggregation. The response is very predictable: I get a few “how does that work” questions in the next seconds.
VMware did a great job with the virtual switch embedded in the VMware hypervisor (vNetwork Standard Switch – vSS – or vNetwork Distributed Switch – vDS): it uses special forwarding rules (I call them split horizon switching, Cisco UCS documentation uses the term End Host Mode) that prevent forwarding loops without resorting to STP or port blocking.
Data Center Bridging (DCB) Congestion Notification (802.1Qau)
The last (and the least popular) Data Center Bridging (DCB) standard tries to solve the problem of congestion in large bridged domains (PFC enables lossless transport and ETS standardizes DWRR queuing). To illustrate the need for congestion control, consider a simple example shown in the following diagram:
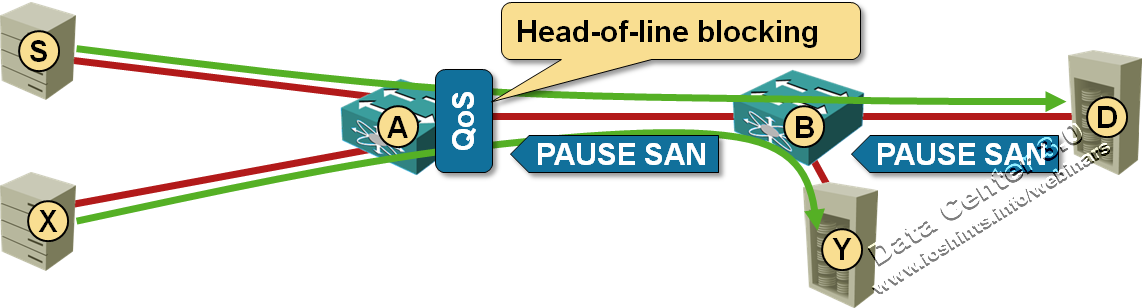
It came to my attention that a vendor might be using this blog post to justify the need for QCN in FCoE environments. Should that be the case, please make sure you also read about the difference between dense and sparse FCoE, the (lack of) need for QCN in FCoE and whether it makes sense to run FCoE over TRILL. Finally, consider how you’ll troubleshoot FCoE environments.
VPLS is a technology, not just a service provider offering
The Internet Exchange and Peering Points Packet Pushers Podcast is as good as the rest of them (listen to it first and then continue reading), but also strangely relevant to the data center engineers. When you look beyond the peering policies, route servers and BGP tidbits, an internet exchange is a high-performance large-scale layer-2 network that some data center switching vendors are dreaming about ... the only difference being that the internet exchanges have to perform extremely well using existing products and technologies, not the shortest-path-bridging futures promised by the vendors.
… updated on Sunday, May 8, 2022 09:21 UTC
Multi-Chassis Link Aggregation (MLAG) Basics
If you ask any networking engineer building layer-2 fabrics the traditional way about his worst pains, I’m positive Spanning Tree Protocol (STP) will be very high on the shortlist. In a well-designed fully redundant hierarchical bridged network where every device connects to at least two devices higher in the hierarchy, you lose half the bandwidth to STP loop prevention whims.
Introduction to 802.1Qaz (Enhanced Transmission Selection – ETS)
Enhanced Transmission Selection (ETS) is the second part of the Data Center Bridging puzzle (I’ve already described Priority Flow Control). It specifies two different technologies:
- Queuing mechanisms in bridges
- Data Center Bridging eXchange protocol: a Control/Negotiation protocol that allows bridges and hosts to negotiate QoS parameters in a bridged network.
Although some bridges from some vendors supported numerous QoS mechanisms in the past, 802.1Qaz is the first attempt to standardize a richer set of QoS behaviors than the strict priority queuing defined in 802.1p.
Virtual aggregation: a quick fix for FIB/TCAM overflow
Quick summary for the differently-attentive: virtual aggregation solves TCAM overflow problems (high-level description of how it works).
During the Big Hot and Heavy Switches podcast, Dan Hughes complained that the Nexus 7000 switch cannot take the full BGP table. The reason is simple: it’s TCAM (FIB) has only 56.000 entries and the BGP table has almost 350.000 routes.
Nexus 7000 is a Data Center switch, so the TCAM size is not really a limitation (it would usually have a default route toward the WAN core), but the same problem is experienced by Service Providers all over the world – the TCAM/FIB size of their high-speed routers is limited.
… updated on Saturday, December 26, 2020 13:51 UTC
RIBs and FIBs (aka IP Routing Table and CEF Table)
Every now and then, I’m asked about the difference between Routing Information Base (RIB), also known as IP Routing Table and Forwarding Information Base (FIB), also known as CEF table (on Cisco’s devices) or IP forwarding table.
Let’s start with an overview picture (which does tell you more than the next thousand words I’ll write):