Category: link aggregation
VMware vSwitch does not support LACP
This is very old news to any seasoned system or network administrator dealing with VMware/vSphere: the vSwitch and vNetwork Distributed Switch (vDS) do not support Link Aggregation Control Protocol (LACP). Multiple uplinks from the same physical server cannot be bundled into a Link Aggregation Group (LAG, also known as port channel) unless you configure static port channel on the adjacent switch’s ports.
When you use the default (per-VM) load balancing mechanism offered by vSwitch, the drawbacks caused by lack of LACP support are usually negligible, so most engineers are not even aware of what’s (not) going on behind the scenes.
Intelligent Redundant Framework (IRF) – Stacking as Usual
When I was listening to the Intelligent Redundant Framework (IRF) presentation from HP during the Tech Field Day 2010 and read the HP/H3C IRF 2.0 whitepaper afterwards, IRF looked like a technology sent straight from Data Center heavens: you could build a single unified fabric with optimal L2 and L3 forwarding that spans the whole data center (I was somewhat skeptical about their multi-DC vision) and behaves like a single managed entity.
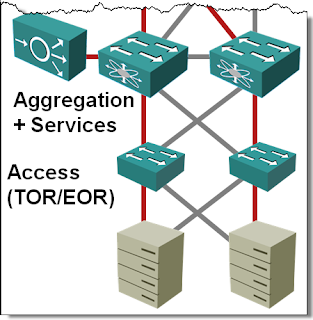
No wonder I started drawing the following highly optimistic diagram when creating materials for the Data Center 3.0 webinar, which includes information on Multi-Chassis Link Aggregation (MLAG) technologies from numerous vendors.
MLAG and Load Balancing
FullMesh added an excellent comment to my Multi-Chassis Link Aggregation (MLAG) and hot potato switching post. He wrote:
If there are two core routing switches and two access switches which are MLAGged together in both directions, and hosts that are dual-active LAGged to the pair of access switches, then the traffic would stay on whichever side the host places it.
He also opened another can of worms: load balancing in MLAG environment is dictated by the end hosts. It doesn’t pay to have fancy switches that support L3 or L4 load balancing; a stupid host implementing destination-MAC-address-based load balancing can easily ruin your day.
Multi-Chassis Link Aggregation (MLAG) and Hot Potato Switching
There are two reasons one would bundle parallel Ethernet links into a port channel (official term is Link Aggregation Group):
- Transforming parallel links into a single logical link bypasses Spanning Tree Protocol loop avoidance logic; all links belonging to the port channel can be active at the same time (see also: Multi-Chassis Link Aggregation basics).
- Load sharing across parallel links in a port channel increases the total bandwidth available between adjacent L2 switches or between routers/hosts and switches.
Ethan Banks wrote an excellent explanation of traditional port channel caveats (proving that 1+1 sometimes does not equal 2); things get way worse when you start using Multi-Chassis Link Aggregation due to hot potato switching (the switch tries to forward packets toward destination MAC address as soon as possible) used by all MLAG implementations I’m familiar with.
External Brains Driving an MLAG Cluster
Juniper has introduced an interesting twist to the Stacking on Steroids architecture: the brains of the box (control plane) are outsourced. When you want to build a virtual chassis (Juniper’s marketing term for stack of core switches) out of EX8200 switches, you offload all the control-plane functionality (Spanning Tree Protocol, Link Aggregation Control Protocol, first-hop redundancy protocol, routing protocols) to an external box (XRE200).
Multi-chassis Link Aggregation: Stacking on Steroids
In the Multi-chassis Link Aggregation (MLAG) Basics post I’ve described how you can use (usually vendor-proprietary) technologies to bundle links connected to two upstream switches into a single logical channel, bypassing the Spanning Tree Protocol (STP) port blocking. While every vendor takes a different approach to MLAG, there are only a few architectures that you’ll see. Let’s start with the most obvious one: stacking on steroids.
… updated on Sunday, May 8, 2022 09:21 UTC
Multi-Chassis Link Aggregation (MLAG) Basics
If you ask any networking engineer building layer-2 fabrics the traditional way about his worst pains, I’m positive Spanning Tree Protocol (STP) will be very high on the shortlist. In a well-designed fully redundant hierarchical bridged network where every device connects to at least two devices higher in the hierarchy, you lose half the bandwidth to STP loop prevention whims.