Category: fabric
Response: The Usability of VXLAN
Wes made an interesting comment to the Migrating a Data Center Fabric to VXLAN blog post:
The benefit of VXLAN is mostly scalability, so if your enterprise network is not scaling… just don’t. The migration path from VLANs is to just keep using VLANs. The (vendor-driven) networking industry has a huge blind spot about this.
Paraphrasing the famous Dinesh Dutt’s Autocon1 remark: I couldn’t disagree with you more.
… updated on Thursday, June 13, 2024 11:02 +0200
The Mythical Use Cases: Traffic Engineering for Data Center Backups
Vendor product managers love discussing mythical use cases to warrant complex functionality in their gear. Long-distance VM mobility was one of those (using it for disaster avoidance was Mission Impossible under any real-world assumptions), and high-volume network-based backups seems to be another. Here’s what someone had to say about that particular unicorn in a LinkedIn comment when discussing whether we need traffic engineering in a data center fabric.
When you’re dealing with a large cluster on a fabric, you will see things like inband backup. The most common one I’ve seen is VEEAM. Those inband backups can flood a single link, and no amount of link scheduling really solves that; depending on the source, they can saturate 100G. There are a couple of solutions; IPv6 or eBGP SID has been used to avoid these links or schedule avoidance for other traffic.
It is true that (A) in-band backups can be bandwidth intensive and that (B) well-written applications can saturate 100G server links. However:
Why Are We Using EVPN Instead of SPB or TRILL?
Dan left an interesting comment on one of my previous blog posts:
It strikes me that the entire industry lost out when we didn’t do SPB or TRILL. Specifically, I like how Avaya did SPB.
Oh, we did TRILL. Three vendors did it in different proprietary ways, but I’m digressing.
Data Center Fabric Designs: Size Matters
The “should we use the same vendor for fabric spines and leaves?” discussion triggered the expected counterexamples. Here’s one:
I actually have worked with a few orgs that mix vendors at both spine and leaf layer. Can’t take names but they run fairly large streaming services. To me it seems like a play to avoid vendor lock-in, drive price points down and be in front of supply chain issues.
As always, one has to keep two things in mind:
Worth Reading: Networking for AI Workloads
Sharada Yeluri (Senior Director of Engineering at Juniper Networks) wrote a long article describing the connectivity requirements of AI workloads and new approaches to Ethernet fabrics. Definitely worth reading if you’re interested in these topics.
Dealing with Cisco ACI Quirks
Sebastian described an interesting Cisco ACI quirk they had the privilege of chasing around:
We’ve encountered VM connectivity issues after VM movements from one vPC leaf pair to a different vPC leaf pair with ACI. The issue did not occur immediately (due to ACI’s bounce entries) and only sometimes, which made it very difficult to reproduce synthetically, but due to DRS and a large number of VMs it occurred frequently enough, that it was a serious problem for us.
Here’s what they figured out:
What Happened to Leaf Switches with Four Uplinks?
The last time I spent days poring over vendor datasheets collecting information for the overview part of Data Center Fabrics webinar a lot of 1RU data center leaf switches came in two form factors:
- 48 low-speed server-facing ports and 4 high-speed uplinks
- 32 high-speed ports that you could break out into four times as many low-speed ports (but not all of them)
I expected the ratios to stay the same when the industry moved from 10/40 GE to 25/100 GE switches. I was wrong – most 1RU leaf data center switches based on recent Broadcom silicon (Trident-3 or Trident-4) have between eight and twelve uplinks.
External Links on Spine Switches
A networking engineer attending the Building Next-Generation Data Center online course asked this question:
What is the best practice to connect DC fabric to outside world assuming there are 2 spine switches in the fabric and EVPN VXLAN is used as overlay? Is it a good idea to introduce edge (border) switches, or it is better to connect outside world directly to the spine?
As always, the answer is “it depends,” this time based on:
Leaf-and-Spine Fabrics Between Theory and Reality
I’m always envious of how easy networking challenges seem when you’re solving them in PowerPoint, for example, when an innovation specialist explains how scalability works in leaf-and-spine fabrics in a LinkedIn comment:
One of the main benefits of a CLOS folded spine topology is the scale out spine where you can scale out the number of spine nodes increasing your leaf-spine n-way ECMP as well as minimizing the blast radius with the more spine nodes the more redundancy and resiliency.
Isn’t that wonderful? If you need more bandwidth, sprinkle the magic spine powder on your fabric, add water, and voila! Problem solved. Also, it looks like adding spine switches reduces the blast radius. Who would have known?
How Many Spines Should a Leaf-and-Spine Fabric Have?
One of my readers sent me a question along these lines:
How do we determine the number of spines needed in a leaf-and-spine fabric? It’s easy to calculate the number of leaf nodes from the required number of server ports, and two spines give you the redundancy. Does it make sense to have more spines if two are good enough from the capacity perspective?
There are at least two factors to consider:
IRB Models: Edge Routing
The simplest way to implement layer-3 forwarding in a network fabric is to offload it to an external device1, be it a WAN edge router, a firewall, a load balancer, or any other network appliance.
Routing at the (outer) edge of the fabric
Integrated Routing and Bridging (IRB) Design Models
Imagine you built a layer-2 fabric with tons of VLANs stretched all over the place. Now the users want to exchange traffic between those VLANs, and the obvious question is: which devices should do layer-2 forwarding (bridging) and which ones should do layer-3 forwarding (routing)?
There are four typical designs you can use to solve that challenge:
- Exchange traffic between VLANs outside of the fabric (edge routing)
- Route on core switches (centralized routing)
- Route on ingress (asymmetric IRB)
- Route on ingress and egress (symmetric IRB)
This blog post is an overview of the design models; we’ll cover each design in a separate blog post.
What Happened to FabricPath and Its Friends?
Continuing the what happened to old technologies saga, here’s another question by Enrique Vallejo:
Are FabricPath, TRILL or SPB still alive, or has everyone moved to VXLAN? Are they worth studying?
TL&DR: Barely. Yes. No.
Layer-2 Fabric craziness exploded in 2010 with vendors playing the usual misinformation games that eventually resulted in totally fragmented market full of partial- or proprietary solutions. At one point in time, some HP data center switches supported only TRILL, and other data center switches from the same company supported only SPB.
Now for individual technologies:
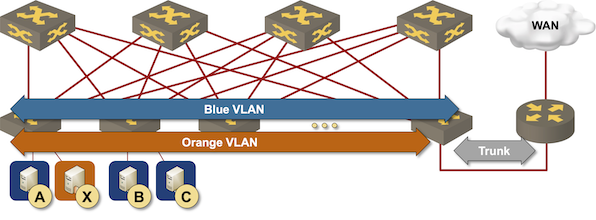
Building a Small Data Center Fabric with Four Switches
One of my subscribers has to build a small data center fabric that’s just a tad too big for two switch design.
For my datacenter I would need two 48 ports 10GBASE-T switches and two 48 port 10/25G fibber switches. So I was watching the Small Fabrics and Lower-Speed Interfaces part of Physical Fabric Design to make up my mind. There you talk about the possibility to do a leaf and spine with 4 switches and connect servers to the spine.
A picture is worth a thousand words, so here’s the diagram of what I had in mind:
Worth Reading: Switching to IP fabrics
Namex, an Italian IXP, decided to replace their existing peering fabric with a fully automated leaf-and-spine fabric using VXLAN and EVPN running on Cumulus Linux.
They documented the design, deployment process, and automation scripts they developed in an extensive blog post that’s well worth reading. Enjoy ;)