Category: data center
Published on , commented on July 6, 2022
Open Networking Foundation – Fabric Craziness Reaches New Heights
Some of the biggest buyers of the networking gear have decided to squeeze some extra discount out of the networking vendors and threatened them with open-source alternative, hoping to repeat the Linux/Apache/MySQL/PHP saga that made it possible to build server farms out of low-cost commodity gear with almost zero licensing costs. They formed the Open Networking Foundation, found a convenient technology (OpenFlow) and launched another major entrant in the Buzzword Bingo – Software-Defined Networking (SDN).
Networking vendors, either trying to protect their margins by stalling the progress of this initiative, or stampeding into another Wild West Gold Rush (hoping to unseat their bigger competitors with low-cost standard-based alternatives) have joined the foundation in hordes; the list of initial members (see the press release for details) reads like Who’s Who in Networking.
TRILL/Fabric Path – STP Integration
Every Data Center fabric technology has to integrate seamlessly with legacy equipment running the venerable Spanning Tree Protocol (STP) or one of its facelifted incarnations (for example, RSTP or MST). The alternative, called rip-and-replace when talking about other vendors’ boxes or synchronized upgrade when promoting your wares (no, I haven’t heard it yet, but I’m sure it’s coming), is simply indigestible to most data center architects.
TRILL and Cisco’s proprietary Fabric Path take a very definitive stance: the new fabric is the backbone of the network routing TRILL-encapsulated layer-2 frames across bridged segments (TRILL) or contiguous backbone (Fabric Path). Both architectures segment the original STP domain into small chunks at the edges of the network as shown in the following figure:
Does Bridge Assurance Make UDLD Obsolete?
I got an interesting question from Andrew:
Would you say that bridge assurance makes UDLD unnecessary? It doesn't seem clear from any resource I've found so far (either on Cisco's docs or on Google)."
It’s important to remember that UDLD works on physical links whereas bridge assurance works on top of STP (which also implies it works above link aggregation/port channel mechanisms). UDLD can detect individual link failure (even when the link is part a LAG); bridge assurance can detect unaggregated link failures, total LAG failure, misconfigured remote port or a malfunctioning switch.
Don’t lie about proprietary protocols
A few months ago Brocade launched its own version of Data Center Fabric (VCS) and the VDX series of switches claiming that:
The Ethernet Fabric is an advanced multi-path network utilizing an emerging standard called Transparent Interconnection of Lots of Links (TRILL).
Those familiar with TRILL were immediately suspicious as some of the Brocade’s materials mentioned TRILL in the same sentence as FSPF, but we could not go beyond speculations. The Brocade’s Network OS Administrator’s Guide (Supporting Network OS v2.0, December 2010) shows a clear picture.
The Data Center Fabric architectures
Have you noticed how quickly fabric got as meaningless as switching and cloud? Everyone is selling you data center fabric and no two vendors have something remotely similar in mind. You know it’s always more fun to look beyond white papers and marketectures and figure out what’s really going on behind the scenes (warning: you might be as disappointed as Dorothy was). I was able to identify three major architectures (at least two of them claiming to be omnipotent fabrics).
Business as usual
Each networking device (let’s confuse everyone and call them switches) works independently and remains a separate management and configuration entity. This approach has been used for decades in building the global Internet and thus has proven scalability. It also has well-known drawbacks (large number of managed devices) and usually requires thorough design to scale well.
Traffic Trombone (what it is and how you get them)
Every so often I get a question “what exactly is a traffic trombone/tromboning”. Here’s my attempt at a semi-formal definition.
Traffic trombone is a term (probably invented by Greg Ferro) that colorfully describes inter-VLAN traffic flows in a network with stretched (usually overlapping) L2 domains.
In a traditional L2/L3 data center architecture with small L2 domains in the access layer and L3 forwarding across the core network, the inter-subnet traffic flows were close to optimal: a host would send a packet toward the first-hop (ingress) router (across a bridged L2 subnet), the ingress router would forward the packet across an optimal path toward the egress router, and the egress router would deliver the packet (yet again, across a bridged L2 subnet) to the destination host.
What exactly makes something “mission critical”?
Pete Welcher wrote an excellent Data Center L2 Interconnect and Failover article with a great analogy: he compares layer-2 data center interconnect to beer (one might be a good thing, but it rarely stops there). He also raised an extremely good point: while it makes sense to promote load balancers and scale-out architectures, many existing applications will never run on more than a single server (sometimes using embedded database like SQL Express).
L2 DCI with MLAG over VPLS transport?
One of the answers I got to my “How would you use VPLS transport in L2 DCI” question was also “Can’t you just order two VPLS services, use them as P2P links and bundle the two links into a multi-chassis link aggregation group (MLAG)?” like this:
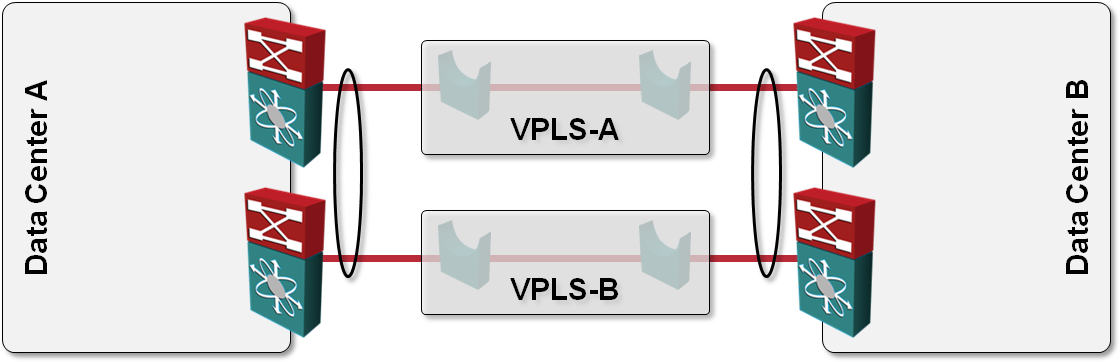
How would you use VPLS transport in L2 DCI?
One of the questions answered in my Data Center Interconnect webinar is: “what options do I have to build a layer-2 interconnect with transport technology X”, with X ∈ {dark-fiber, DWDM, SONET, pseudowire, VPLS, MPLS/VPN, IP}. VPLS is one of the tougher nuts to crack; it provides a switched LAN emulation, usually with no end-to-end spanning tree (which you wouldn’t want to have anyway).
Imagine the following simple scenario where we want to establish redundant connectivity between two data centers and the only transport technology we can get is VPLS (or some other Carrier Ethernet LAN service):
VEPA or vCloud Network Isolation?
If I could design my dream data center with total disregard to today’s limitations (and technologies from an alternate universe), it would have optimal connectivity between any two endpoints (real or virtual), no limits on VM mobility and on-demand L4-7 services insertion (be it firewalling, load balancing or something else) ... all of that implemented on truly scalable trombone-free networking infrastructure (in a dream world I don’t care whether it’s called routing or bridging).
Why would FC/FCoE scale better than iSCSI?
During one of the iSCSI/FC/FCoE tweetstorms @stu made an interesting claim: FC scales to thousands of nodes; iSCSI can’t do that.
You know I’m no storage expert, but I fail to see how FC would be inherently (architecturally) better than iSCSI. I would understand someone claiming that existing host or storage iSCSI adapters behave worse than FC/FCoE adapters, but I can’t grasp why properly implemented iSCSI network could not scale.
Am I missing something? Please help me figure this one out. Thank you!
Layer-3 gurus: asleep at the wheel
I just read a great article by Kurt (the Network Janitor) Bales eloquently describing how a series of stupid decisions led to the current situation where everyone (but the people who actually work with the networking infrastructure) think stretched layer-2 domains are the mandatory stepping stone toward the cloudy nirvana.
It’s easy to shift the blame to everyone else, including storage vendors (for their love of FC and FCoE) and VMware (for the broken vSwitch design), but let’s face the reality: the rigid mindset of layer-3 gurus probably has as much to do with the whole mess as anything else.
Open FCoE – Software implementation of the camel jetpack
Intel announced its Open FCoE (software implementation of FCoE stack on top of Intel’s 10GB Ethernet adapters) using the cloudy bullshit bingo including simplifying the Data Center, Free New Technology, Cloud Vision and Green Computing (ok, they used Environmental impact) and lots of positive supporting quotes. The only thing missing was an enthusiastic Gartner quote (or maybe they were too expensive?).
Published on , commented on July 10, 2022
VMware Cluster: Up and Running in Three Hours
A few days ago I wanted to test some of the new networking features VMware introduced with the vShield product family. I almost started hacking together a few old servers (knowing I would have wasted countless hours with utmost stupidities like trying to get the DVDs to boot), but then realized that we already have the exact equipment I need: a UCS system with two Fabric Interconnects and a chassis with five blade servers – the lab for our Data Center training classes (the same lab has a few Nexus switches, but that’s another story).
I managed to book lab access for a few days, which was all I needed. Next step: get a VMware cluster installed on it. As I never touched the UCS system before, I asked Dejan Strmljan (one of our UCS gurus) to help me.
VMware vSwitch does not support LACP
This is very old news to any seasoned system or network administrator dealing with VMware/vSphere: the vSwitch and vNetwork Distributed Switch (vDS) do not support Link Aggregation Control Protocol (LACP). Multiple uplinks from the same physical server cannot be bundled into a Link Aggregation Group (LAG, also known as port channel) unless you configure static port channel on the adjacent switch’s ports.
When you use the default (per-VM) load balancing mechanism offered by vSwitch, the drawbacks caused by lack of LACP support are usually negligible, so most engineers are not even aware of what’s (not) going on behind the scenes.