Category: Automation
Response: CLI Is an API
Andrew Yourtchenko and Dr. Tony Przygienda left wonderful comments to my Screen Scraping in 2025 blog post, but unfortunately they prefer commenting on a closed platform with ephemeral content; the only way to make their thoughts available to a wider audience is by reposting them. Andrew first:
I keep saying CLI is an API. However, it is much simpler and an easier way to adapt to the changes, if these three conditions are met:
Screen Scraping in 2025
Dr. Tony Przygienda left a very valid (off-topic) comment to my Breaking APIs or Data Models Is a Cardinal Sin blog post:
If, on the other hand, the customers would not camp for literally tens of years on regex scripts scraping screens, lots of stuff could progress much faster.
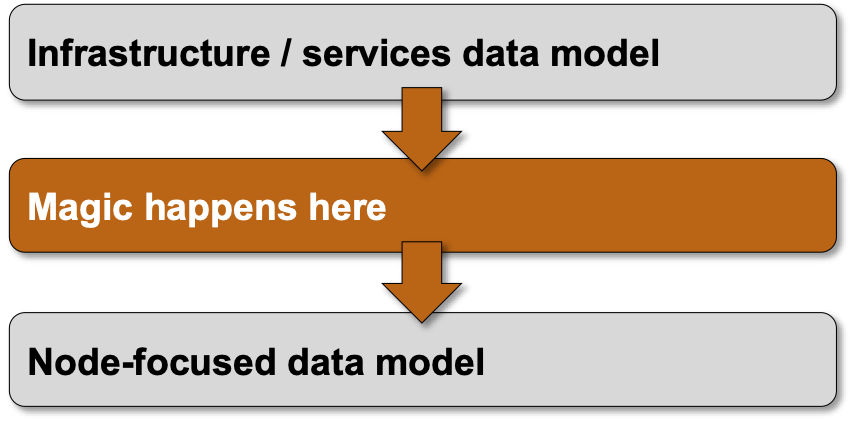
He’s right, particularly from Juniper’s perspective; they were the first vendor to use a data-driven approach to show commands. Unfortunately, we’re still not living in a perfect world:
Breaking APIs or Data Models Is a Cardinal Sin
Imagine you decide to believe the marketing story of your preferred networking vendor and start using the REST API to configure their devices. That probably involves some investment in automation or orchestration tools, as nobody in their right mind wants to use curl or Postman to configure network devices.
A few months later, after your toolchain has been thoroughly tested, you decide to upgrade the operating system on the network devices, and everything breaks. The root cause: the vendor changed their API or the data model between software releases.
Worth Exploring: Infrahub by Opsmill
A year or two after Damien Garros told me that “he moved to France and is working on something new” we can admire the results: Infrahub, a version-control-based system that includes a data store and a repository of all source code you use in your network automation environment. Or, straight from the GitHub repository,
A central hub to manage the data, templates and playbooks that powers your infrastructure by combining the version control and branch management capabilities of Git with the flexible data model and UI of a graph database.
Testing Device Configuration Templates
Many network automation solutions generate device configurations from a data model and deploy those configurations. Last week, we focused on “how do we know the device data model is correct?” This time, we’ll take a step further and ask ourselves, “how do we know the device configurations work as expected?”
There are four (increasingly complex) questions our tests should answer:
Testing Network Automation Data Transformation
Every complex enough network automation solution has to introduce a high-level (user-manageable) data model that is eventually transformed into a low-level (device) data model.
High-level overview of the process
The transformation code (business logic) is one of the most complex pieces of a network automation solution, and there’s only one way to ensure it works properly: you test the heck out of it ;) Let me show you how we solved that challenge in netlab.
Video: Intro to Real Life Network Automation
Urs Baumann invited me to have a guest lecture in his network automation course, and so I had the privilege of being in lovely Rapperswil last week, talking about the basics of real-life network automation.
Urs published the video recording of the presentation on YouTube; hope you’ll like it, and if you don’t get too annoyed by the overly pushy ads, watch the other videos from his infrastructure-as-code course.
Implementing 'Undo' Functionality in Network Automation
Kurt Wauters sent me an interesting challenge: how do we do rollbacks based on customer requests? Here’s a typical scenario:
You might have deployed a change that works perfectly fine from a network perspective but broke a customer application (for example, due to undocumented usage), so you must be able to return to the previous state even if everything works. Everybody says you need to “roll forward” (improve your change so it works), but you don’t always have that luxury and might need to take a step back. So, change tracking is essential.
He’s right: the undo functionality we take for granted in consumer software (for example, Microsoft Word) has totally spoiled us.
Response: Vendor Network Automation Tools
Drew Conry-Murray published a excellent summary of his takeaways from the AutoCon0 event, including this one:
Most companies want vendor-supported tools that will actually help them be more efficient, reduce human error, and increase the velocity at which the network team can support new apps and services.
Yeah, that’s nothing new. Most Service Providers wanted vendors to add tons of nerd knobs to their products to adapt them to existing network designs. Obviously, it must be done for free because a vast purchase order1 is dangling in the air. We’ve seen how well that worked, yet learned nothing from that experience.
Worth Reading: Network CI and Open Source
Did you find the Network Automation with GitHub Actions blog post interesting? Here are some more GitHub Self-Hosted Runner goodies from Julio Perez: Network CI and Open Source – Welcome to the World of Tomorrow. Enjoy!