Fast Failover: The Challenge
Sometimes you’re asked to design a network that will reroute around a failure in milliseconds. Is that feasible? Maybe. Is it simple? Absolutely not.
In this series of blog posts we’ll start with the basics, explore the technologies that you can use to reach that goal, and discover one or two unexpected rabbit holes.
… updated on Friday, November 20, 2020 15:10 UTC
How Fast Can We Detect a Network Failure?
In the introductory fast failover blog post I mentioned the challenge of fast link- and node failure detection, and how it makes little sense to waste your efforts on fast failover tricks if the routing protocol convergence time has the same order of magnitude as failure detection time.
Now let’s focus on realistic failure detection mechanisms and detection times. Imagine a system connecting a hardware switching platform (example: data center switch or a high-end router) with a software switching platform (midrange router):
Fast Failover: Topologies
In the blog post introducing fast failover challenge I mentioned several typical topologies used in fast failover designs. It’s time to explore them.
The Basics
Fast failover is (by definition) adjustment to a change in network topology that happens before a routing protocol wakes up and deals with the change. It can therefore use only locally available information, and cannot involve changes in upstream devices. The node adjacent to the failed link has to deal with the failure on its own without involving anyone else.
Fast Failover: Hardware and Software Implementations
In previous blog posts in this series we discussed whether it makes sense to invest into fast failover network designs, the topologies you can use in such designs, and the fault detection techniques. I also hinted at different fast failover implementations; this blog post focuses on some of them.
Hardware-based failover changes the hardware forwarding tables after a hardware-detectable link failure, most likely loss-of-light or transceiver-reported link fault. Forwarding hardware cannot do extensive calculations; the alternate paths are thus usually pre-programmed (more details below).
Fast Failover: Techniques and Technologies
Continuing our Fast Failover saga, let’s focus on techniques and technologies available to implement it (assuming you still think it’s worth the effort).
There are numerous technologies you can use to implement fast reroute, from the most complex to the easiest one:
What Exactly Happens after a Link Failure?
Imagine the following network running OSPF as the routing protocol. PE1–P1–PE2 is the primary path and PE1–P2–PE2 is the backup path. What happens on PE1 when the PE1–P1 link fails? What happens on PE2?
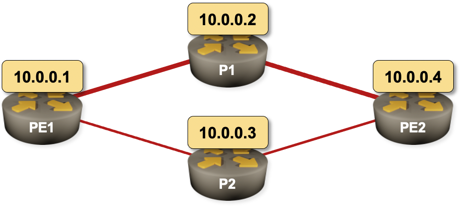
Sample 4-router network with a primary and a backup path
The second question is much easier to answer, and the answer is totally unambiguous as it only involves OSPF: