Validating Data in GitOps-Based Automation
Anyone using text files as a poor man’s database eventually stumbles upon the challenge left as a comment in Automating Cisco ACI Environments blog post:
The biggest challenge we face is variable preparation and peer review process before committing variables to Git. I’d be particularly interested on how you overcome this challenge?
We spent hours describing potential solutions in Validation, Error Handling and Unit Tests part of Building Network Automation Solutions online course, but if you never built a network automation solution using Ansible YAML files as source-of-truth the above sentence might sound a lot like Latin, so let’s make it today’s task to define the problem.
Beyond Simple Scripts
Most network engineers start their automation journey with easy wins: simple scripts that collect information from a large set of network devices, or make sure that all routers use the same set of NTP- or syslog servers.
Once the initial excitement of having your first automation solution in production fades, the next logical step becomes network- and services deployment, and after a few failed attempts it becomes painfully obvious that you need a data model describing the whole network (or a service) instead of individual boxes. At that point you could usually describe your automation system with this simple diagram1:
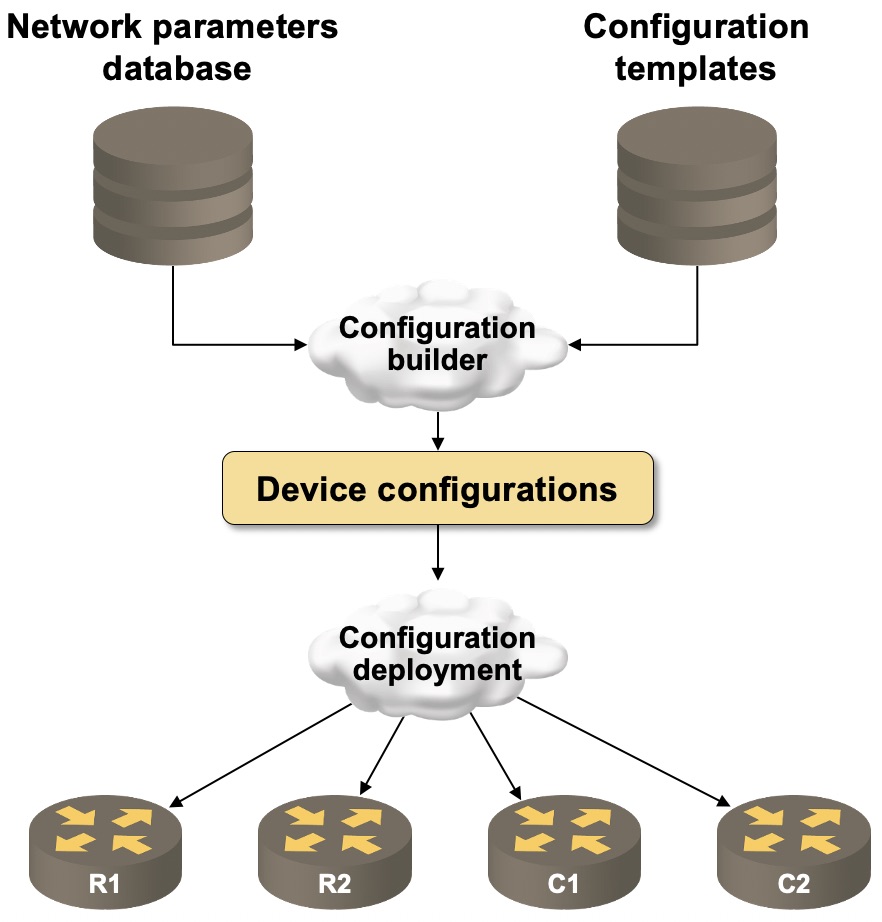
Typical Network Deployment Automation System
Using templates to generate device configurations (or Terraform recipes or API calls) is well-understood; the next interesting challenge you have to overcome is where do I store my data model (or more formally, what data store do I use) and if you happen to use Ansible as the go-to tool, text files become the obvious choice.
Sprinkle version control on top of that, add some branching and merging magic and you seem to be in the green meadows of Infrastructure-as-Code (because you’re describing your network as a set of YAML files) and GitOps until you realize every data model suffers from GIGO problems.
A typical GitOps workflow (although focused on managing device configurations not data model changes) is displayed on the following diagram:
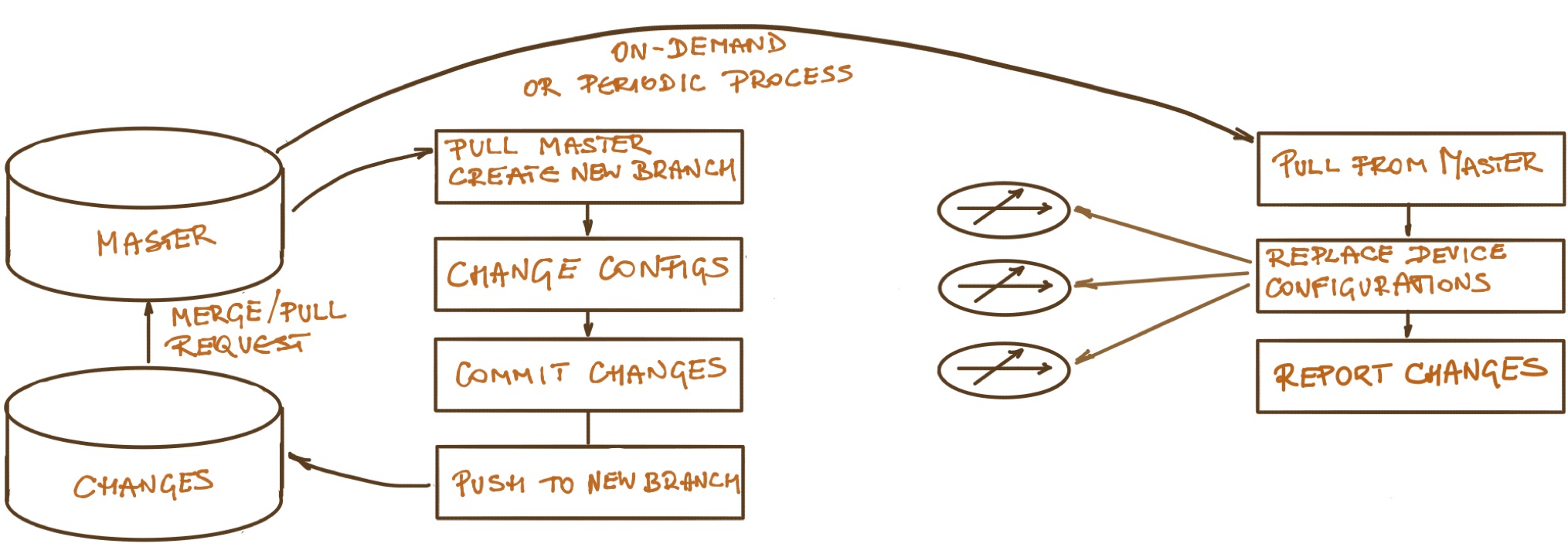
Managing Device Configurations with GitOps
The above workflow is missing a crucial step: are the changes made to the source code any good and should they be accepted? That challenge has been solved a gazillion times in software development using approaches like code review, automated testing, and continuous integration… but how do you implement them in a network automation solution?
In fact, you have more on your hands than simple software development project: you have to test your code (templates, playbooks…) and your data; in this series of blog posts we’ll focus on the latter.
There are tons of things you can do to validate changes to your data model before they get accepted into the production source-of-truth. Here are just a few examples (more in an upcoming blog post):
- Pre-commit hooks2 that do basic sanity checks like checking the syntax of YAML files with yamllint
- Pre-commit hooks or continuous integration (CI) pipelines3 that validate the basic sanity of your data model (for example: are IP addresses in the right format)
- CI pipeline that validates data model against a snapshot of an actual network (for example, checking device- and interface names);
- CI pipeline that builds a simulated version of the whole network, deploys the changes, and runs unit tests on the simulated network;
- Pre-deployment pipeline that collects and reports changes about to be made to device configurations for operator approval.
As I already mentioned, we covered most of these ideas in Validation, Error Handling and Unit Tests part of Building Network Automation Solutions online course; I plan to cover at least a few of them in upcoming blog posts, but you know that it typically takes a while before I find time to do that, so if you’re serious about implementing guardrails for your automation solution you might be better off enrolling into the course.
-
The diagram was created in 2015 before it became popular to talk about single source-of-truth. Today I would use that hip term instead of network parameters database. ↩︎
-
Programs executed before you’re allowed to commit your changes to local copy of Git repository ↩︎
-
Programs executed every time someone pushes a branch to the central Git repository ↩︎
My mind is reeling upon debating between GitOps (yaml files) and CMDB (NetBox) as "the source truth". I'd like the flexibility of having the state of network defined in yaml files in a Git repository but I was told it could become little bit unruly as the network grow and a database maybe a better choice.
What would be the decision factors ? How difficult would it be to move from one to the other if needed?
Any insight, pointers or good readings on the subject?
@Philippe: Text files or relational databases
It's not an easy decision, and most people would usually start with text files to understand the requirements, and then migrate to a more formal environment (or not).