Is EBGP Really Better than OSPF in Leaf-and-Spine Fabrics?
Using EBGP instead of an IGP (OSPF or IS-IS) in leaf-and-spine data center fabrics is becoming a best practice (read: thing to do when you have no clue what you’re doing).
The usual argument defending this design choice is “BGP scales better than OSPF or IS-IS”. That’s usually true (see also: Internet), and so far, EBGP is the only reasonable choice in very large leaf-and-spine fabrics… but does it really scale better than a link-state IGP in smaller fabrics?
There are operators running single-level IS-IS networks with thousands of devices, and yet most everyone claims you cannot use OSPF or IS-IS in a leaf-and-spine fabric with more than a few hundred nodes due to inordinate amount of flooding traffic caused by the fabric topology.
This is the moment when a skeptic should say “are you sure BGP works any better?” and the answer is (not surprisingly) “not exactly”, at least if you get your design wrong.
EBGP or IBGP?
Most everyone understanding how BGP really works agrees that it makes more sense to use EBGP between leaf and spine switches than trying to get IBGP to work without underlying IGP, so we’ll ignore IBGP as a viable design option for the rest of this blog post.
Let’s Make It Simple…
Not knowing any better, let’s assume a simplistic design where every switch has a different AS number:
Now imagine a leaf switch advertising a prefix:
- It advertises the prefix to all spine switches;
- Spine switches advertise the prefix to all other leaf switches;
- Properly-configured leaf switches use all equal-cost BGP prefixes for traffic forwarding, but still select one of the as the best BGP path (that’s how BGP works when you don’t configure add-path functionality);
- Leaf switches advertise their best BGP path to all spine switches apart from the one that advertised the best path to them. Some BGP implementations might actually advertise the best path to the router they got the best path from.
- Every single spine switch installs all the alternate BGP paths received from all leaf switches in BGP table… just in case it might be needed.
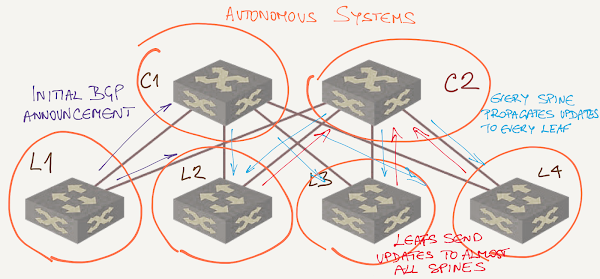
Data center fabric with different AS numbers on spine switches
To recap: on most spine switches you’ll see N entries for every single prefix in the BGP table (where N is the number of leaf switches) – one from the leaf switch with the prefix, and one from every other leaf switch that didn’t select the path through the current spine switch as the best BGP path.
Compare that to how OSPF flooding works and you’ll see that there’s not much difference between the two. In fact, BGP probably uses even more resources in this setup than OSPF because it has to run BGP path selection algorithm whenever BGP table changes, whereas OSPF separates flooding and path computation processes.
Fixing the Mess We Made…
Obviously, we need to do something to reduce the unnecessary flooding. There’s not much one could do in OSPF or IS-IS (don’t get me started on IS-IS mesh groups), which is the real reason why you can’t use them in larger fabrics, and why smart engineers work on RIFT and OpenFabric.
What about BGP? There are two simple ways to filter the unnecessary announcements:
- Configure outbound update filtering on leaf switches (or inbound update filtering on spine switches) to discard paths that traverse more than one leaf switch;
- Use the same AS number on all spine switches and let BGP’s default AS-path-based filtering do its job.
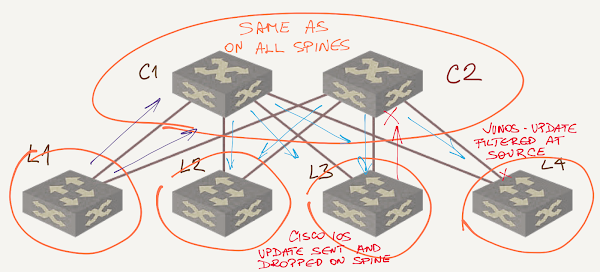
Data center fabric with spine switches as a single AS
Now you know why smart network architects use the same AS number on all spine switches and why RFC 7938 recommends it.
The Dirty Details…
The effectiveness of default AS-path-based filtering depends on the BGP implementation:
- Some implementations (example: Cisco IOS) send BGP updates to all EBGP neighbors regardless of whether the neighbor AS is already in the AS path. The neighbor has to process the update and drop it;
- Other implementations (example: Junos) filter BGP updates on the sender side and don’t send BGP updates that would be dropped by the receiver (as always, there’s a nerd knob to twiddle if you want those updates sent).
Finally, it’s interesting to note that using IBGP without IGP, with spine switches being BGP route reflectors tweaking BGP next hops in outbound updates, results in exactly the same behavior – another exercise for the reader if you happen to be so inclined.
Want to know more?
- Start with Using BGP in Data Center Leaf-and-Spine Fabrics document;
- Watch Leaf-and-Spine Fabric Architectures webinar;
- Building Next-Generation Data Center online course.
It is policy based and it can scale well for more than 100k routes.
Convergence can be improved with BFD with some non-aggressive timers.
Reliability and flow control is taken care by TCP .
"Its all unicast based update policy mechanism" << Which is relevant how exactly?
"and its withdrawn routes can be softly send to neighbors for unnecessary control plane B.W. wastages." << Please explain in more details. Thinking about how OSPF or BGP would revoke a route, I can't figure out what you're trying to tell me.
"It is policy based" << hopefully not relevant in data center fabric underlay.
"and it can scale well for more than 100k routes" << if that's relevant in underlay fabric you shouldn't be reading my blog posts but hire an architect who knows what he's doing ;))
"Convergence can be improved with BFD with some non-aggressive timers." << Ever heard of BFD for OSPF?
"Reliability and flow control is taken care by TCP" << Now that's the only relevant one. However, as Hannes wrote, it's all the question of whether you get the I/O module right. You can't miss much if you're forced to use TCP, but there's an LSA acknowledgement mechanism in OSPF that you could use for pacing (not saying anyone does that).
Regarding the dirty details, by default Cisco IOS-XR will also prevent sending BGP updates containing the AS configured on the remote peer. The feature is called as-path-loopcheck and is enabled by default. One important detail is if several BGP neighbors belong to the same BGP update-group, this will be disabled.
Here is the command reference:
https://www.cisco.com/c/en/us/td/docs/routers/crs/software/crs_r4-2/routing/command/reference/b_routing_cr42crs/b_routing_cr42crs_chapter_01.html#wp3145726977
If for some reasons customers want to disable this optimization (I know some McGyvers), they can use "as-path-loopcheck out disable" command.
Best
Fred
this has the added perk of not relying on specific topological behaviors as some of the aforementioned approaches do.
At this point in my career, I'm done with IGPs. Too many nerd nobs, too many contingencies, too many "too many"s. EBGP Leaf/Spine works great in my Data Center and in my Campus Networks. IGPs can go to hell. BGP ALL THE THINGS!!
I don't know how many Network Engineers have to build a Network like this in real life outside Webscales and Cloud providers. But let's keep that discussion for later. It's always interesting to hear all kind of reasons from people to deploy CLOS fabrics in DC in Enterprise segment typically that I deal with while they mostly don't have clue about why they should be doing it in first place. Forget about their understanding of CLOS Fabrics, Overlays etc. Usually a good justification is DC to support high amount of East-West Traffic....but really ? If you ask them if they even have any benchmarks or tools to measure that in first place :)
Now coming back to Original question of BGP vs OSPF in DC
Interestingly I had a conversation with Arxxxa guys few months back during any interview and I was bashed for proposing OSPF for all wrong reasons. Just because they use BGP in their fabric doesn't mean everyone has to follow. They even didn't seem to have any clue about RIFT, Open Fabric, Fibbing etc.
As you mentioned ' BGP Path Hunting " is an important problem to be solved to reduce the Churn. But of course it comes at it's own price and downsides.
I also saw a comment rejecting EIGRP in favor of multi vendor networking. Well from overlay Networking perspective does EVPN work just fine today ?
- How about Fabric Automation and Orchestration in that case ?
On a closing note I would like to summarize couple of misconceptions around CLOS Fabric :) ... Please feel free to correct me and add as needed
- CLOS AKA Leaf And Spine is Non-Blocking fabric ( Really ? It's Non Contending but not non blocking)
- BGP is the best choice for CLOS (Just because Petr thought ? , but wait Petr was doing this for a WebScale which is far different from Enterprise DC)
- BGP is a good choice as it allows granular policy control
- BGP has less Churn
- BGP Scales far better (In History at least many large ISPs were running OSPF Area 0 for entire network) ... Scale is also a function of HW too and subjective to optimization techniques and so forth
- Layer 2 Fabrics can't be extended beyond 2 Spine switches ( A long argument I had with Arxxxa guys on this. They don't even count SPB as Layer 2 fabric and so forth)
Maybe you would like to cover these mis-conceptions in Spine and Leaf Webinar as updates.
TC !!!
Hello,
What if L1 wants to send to a prefix on L2 and L1-C1 and L2-C2 are down?
Possible paths are L1 -> C2 -> L3/L4 -> C1 -> L2.
But C1 would see its own AS and reject the traffic... right?
That's one of the design tradeoffs you have to make -- either your system won't survive just the right combination of N failures (for N spines), or it will go through path hunting every time a prefix disappears.
I don't think I ever wrote a blog post on path hunting, but Daniel Dib did a great job not so long ago: https://lostintransit.se/2023/10/09/path-hunting-in-bgp/