Load Balancing Elephant Storage Flows
Olivier Hault sent me an interesting challenge:
I cannot find any simple network-layer solution that would allow me to use total available bandwidth between a Hypervisor with multiple uplinks and a Network Attached Storage (NAS) box.
TL&DR summary: you cannot find it because there’s none.
The Problem
Network attached storage uses TCP-based protocols (iSCSI, NFS, CIFS/SMB) to communicate with the attached hosts. Trying to solve the problem at the network or TCP layer thus transforms the problem into: how can I load-balance packets from a single TCP session across multiple links?
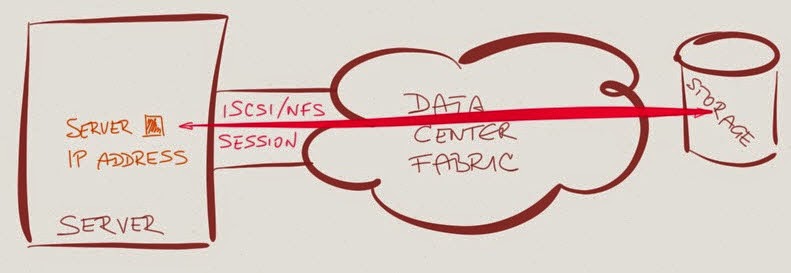
The simple answer is: you cannot, unless you’re willing to tolerate packet reordering, which will interfere with receive-side TCP offload (Receive Segment Coalescing – RSC) and thus impact TCP performance (see also the comments in that blog post).
Link aggregation group (LAG, aka EtherChannel or Port Channel) is not a solution. Most LAG implementations will not send packets from the same TCP session across multiple links to avoid packet reordering.
Brocade solved the problem by keeping track of packet arrival times (and delaying packets that would arrive out-of-order), but it only works if all links are connected to the same ASIC – you cannot use the same trick across multiple ASICs, let alone across multiple switches (for hosts connected to two ToR switches for redundancy).
Conclusion: The problem MUST be solved above the network layer.
The Solutions
There are several solutions one can use to solve this challenge:
- Multipath TCP: insert a shim inside the TCP layer that allows a single application-facing TCP session to be spread across multiple network-facing TCP sessions. All sessions could use the same IP endpoints, and rely on 5-tuple ECMP load balancing between the network and the server (MP-TCP could open new sessions if it figures out the existing sessions hash to the same link)
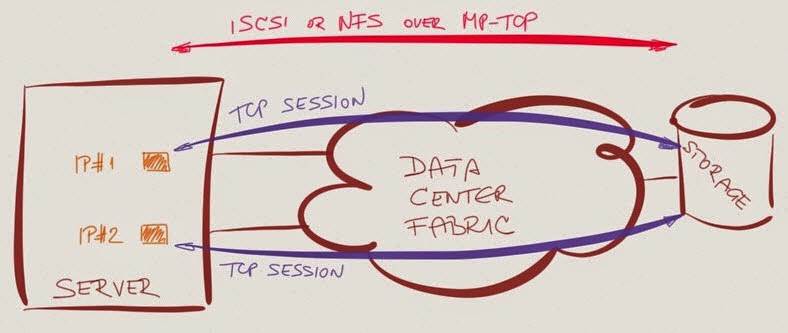
- Multipath I/O: use multiple application-level TCP sessions, each one of them running across one of the uplinks. In most implementations the server-to-network links cannot be in a LAG or ECMP group, and the server uses a dedicated IP address (tied to a specific uplink) for each storage session in the MPIO group. MPIO is available in many iSCSI implementations; SMB3 has a similar feature called SMB Multichannel (HT: JP. Papillon).
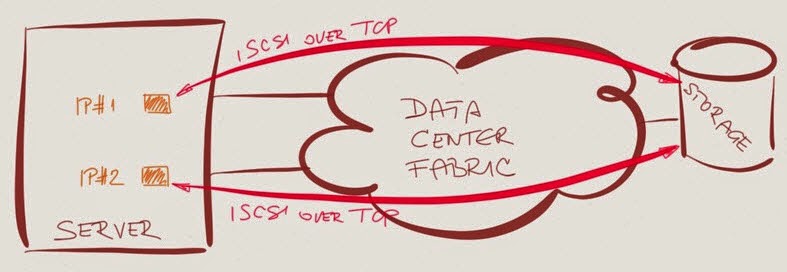
- Slice the elephant into smaller chunks. I got the impression that at least in some OpenStack Cinder implementations each VM uses a separate session with the iSCSI/NFS target, which nicely slices the fat one-session-per-hypervisor-host elephant into dozens of smaller bits. In the ideal case, the number of smaller sessions is large enough to make load balancing work well without tweaking the TCP port number selection or load balancing algorithms.
There’s more to come
I’ll describe the storage challenges in a dedicated storage networking webinar sometime later this year.
http://blogs.technet.com/b/josebda/archive/2012/05/13/the-basics-of-smb-multichannel-a-feature-of-windows-server-2012-and-smb-3-0.aspx
NB : Samba implementation of SMB3 is a "Work In Progress"
http://blog.obnox.de/demo-of-smb3-multi-channel-with-samba/
and it will take ages before finding it in off-the-shelves NAS boxes as long as everybody just check for CIFS/SMB compatibility although CIFS a the pre-2000 version of the MS protocol.
Blog post on that topic is already in the scheduling queue ;) - will add a link to Juniper's implementation.
Thank you!
Juniper VCF actually uses an algorithm to detect TCP window transmissions and load balance each subflow/flowlet. So if you have a single elephant flow, it would be load balanced across all available uplinks.
Doug
I'm pretty familiar with the whole concept of flowlets, and have a hunch what can be done with in on Trident-2 chipset, but you still cannot send a single burst over two (or more) uplinks, which means that you're still limited by the bandwidth of a single uplink.
Also, you cannot send two bursts in parallel, because that would cause packet reordering on the receiver end and kill TCP performance.
Ivan
VCF looks at a single TCP flow and is able to create a table to keep track of the TX packets. If no data is transmitted, the counter is incremented. Basically if the counter is >= the RTT time, we know that we're between TCP windows and the next transmission of packets is a new TCP window, so we can send it down a new uplink.
In our case we see a burst as simply a transmission of traffic for a given TCP window. We'll transmit the entire TCP window down a single uplink, wait, then send the next TCP window down a different uplink. What you effectively have is a single ingress TCP flow that is hashed across a set of egress uplinks.
We avoid packet reordering because VCF knows the network topology and RTT. We only hash flowlets when we know the topology is symmetrical and we can detect we're between TCP windows based on the RTT.
It's a really cool technology. Hope that helps.
I think you're making a point that from the perspective of the NAS or host, itself would be limited to a single uplink without the use of some sort of method such as multipath I/O or multiple TCP sessions.
Agreed!
VCF would only help in the case of hashing a single TCP flow into multiple flowlets when it egresses the TOR.
We just need a method of creating flowlets from the Linux kernel, which should only be about 20 lines of code.
I would say your "must" is stronger than I would like :)
-Carlos
BTW, the captcha is stronger than I would like, or I'm missing my human touch :)
BTW, we all should be "grateful" to the infinite morons who think they can improve their rankings by posting irrelevant comments on anyone's blogs. No spammers - no captcha.
Did you mean NFS instead of NFV?
Slice the elephant into smaller chunks is good enough to take it, but is not really a solution to the problem. If you have still one VM with way more vDisk accesses than another, and fills a physical link, then your still stuck in the base problem.
I think slicing into smaller chunks is just a way (it should really be standard) to avoid murphy, i.e. when DRS moves all "iops-eating" VMs on the same host (DRS does no really base itself on iops/disk speed right?) and you got a big fat TCP stream in a result.
Every solution to a problem or even theory (including Newton mechanics, relativity or quantum mechanics) _usually_ works best under a reasonable set of assumptions (in our case, many small flows) and breaks down at border conditions (black holes etc.). It's thus important to know (A) when you're violating the assumptions and (B) how often those assumptions are violated.
What I meant was more in a case of "per-vm-NFS/iSCSI-flow" implementation of VMware in a SMB cloud for example, you wont get a real profit with this technique.
But... at the end you're right, I think that would be a scenario for multipath I/O... :-)
Also, keep in mind that Arista switches have pretty low number of flows, so you wouldn't be able to connect more than a few hundred servers to that solution (assuming only 2 sessions per server, not session-per-VM approach).
Although I haven't seen to many VM host that saturate a 40G link - which Coho does not support yet - but you might have come across some.