Queuing Mechanisms in Modern Switches
A long while ago there was an interesting discussion started by Brad Hedlund (then at Dell Force10) comparing leaf-and-spine (Clos) fabrics built from fixed-configuration pizza box switches with high-end chassis switches. The comments made by other readers were all over the place (addressing pricing, wiring, power consumption) but surprisingly nobody addressed the queuing issues.
This blog post focuses on queuing mechanisms available within a switch; the next one will address end-to-end queuing issues in leaf-and-spine fabrics.
FIFO Queuing the Simple Way
Lower-cost devices usually use simple internal queuing mechanisms. Assuming there’s no QoS configured on the output port, the forwarding and queuing hardware works along these lines:
- Receive packet on input port;
- Perform destination lookup (or anything else dictated by TCAM) to get an output port;
- Put the packet at the tail of the output port queue.
Not surprisingly, a very large traffic stream going toward an output port saturates the output port queue, resulting in significant latency (or packet drops) for all other traffic streams.
Real-life equivalent: a busy grocery store with a single cash register.

Simple FIFO queuing
Class-Based Queueing
Class-of-Service (CoS) based queuing is a simple variation of the FIFO queuing. Instead of a simple output queue the switching hardware uses multiple (few – usually up to 8) queues, allowing you to separate traffic based on its class (example: storage traffic goes in one queue, vMotion traffic in another one, user-generated traffic in a third one, and VoIP traffic in a fourth queue).
Each queue works as a FIFO queue – once the hardware decides which queue to use for a certain packet, the packet is stuck in that queue.
Real-life analogy: grocery stores that have separate cash registers for buyers with less than five articles.
The order in which the output interface (port) hardware serves the queues determines the actual quality of service.
Packets from a priority queue might be sent first (hardware checks priority queue before trying to select a packet from any other queue), and the hardware might support multiple priority levels (802.1p standard defines eight strict priority levels).
Real-life analogy: Business-class airport security queues that nonetheless end at the same X-ray scanner.
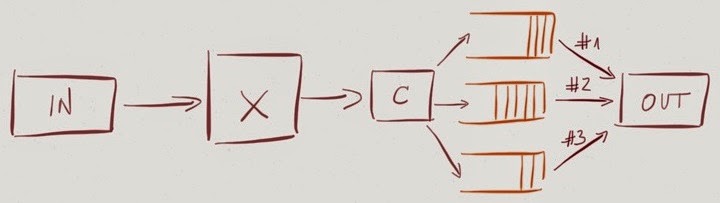
Strict priority queuing
Alternatively, the queues might be served in round-robin fashion while still giving some queues relatively more bandwidth than others (Weighted Round Robin – WRR). For example, Enhanced Transmission Selection (802.1Qaz) defines eight queues that can be either priority- or WRR queues.
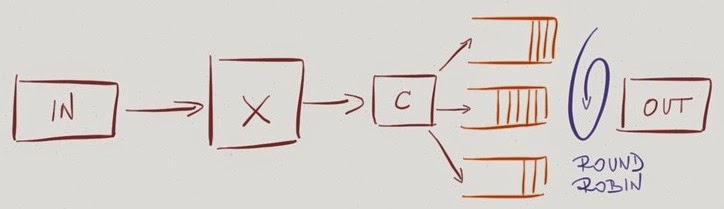
Weighted round-robin queuing
Simple round robin algorithms use per-queue byte count quotas. For example, the hardware sends at least 10.000 bytes worth of data from queue#1 every time queue#1 is served (this is how custom queuing used to work in Cisco IOS).
These algorithms are obviously not precise (unless you’re using fixed-size packets or cells), as they always send a bit more than the queue’s quota worth of data. This deficiency is fixed in the Weighted Deficit Round Robin (WDRR) algorithms that reduce the per-queue byte count of the next round robin cycle by the amount of excess traffic sent in the current cycle.
Head-of-Line Blocking
Imagine a scenario where a large file transfer (example: FTP) lands in the same path across the internal switching fabric as a request-response protocol (example: HTTP) handling short transactions (example: key-value store queries).
Once the file transfer gets going, it generates continuous stream of data that fills all the output queues in the path. Every time the transactional protocol sends some data, it encounters large queues at every hop, significantly increasing end-to-end latency and deteriorating the response time.
Real-life analogy: driving after a long column of heavy trucks on a single-lane section of the highway.
Update 2014-05-29: For a much more detailed description of HoL issues, read the comment by J Hand.
Cisco solved the queuing-on-output-interface part of this problem with Weighted Fair Queuing, an intriguing solution that uses a separate FIFO output queue for every flow. The hardware implementation of this solution is quite expensive (remember the cost of the ATM ports?) and is rarely available in switching silicon (Enterasys, now Extreme Networks, might have something along these lines).
Virtual Output Queuing
High-end switches solve at least some head-of-line blocking scenarios with virtual output queues. Instead of having a single per-class queue on an output port, the hardware implements per-class virtual output queue (VoQ) on input ports.
The packet forwarding and queuing mechanisms work as before, but the packets stay in the virtual output queue on the input linecard till the output port is ready to accept another packet, at which time the hardware takes a packet from one of the virtual output queues, usually in round-robin fashion.
Real-life analogy: take-a-number queuing systems
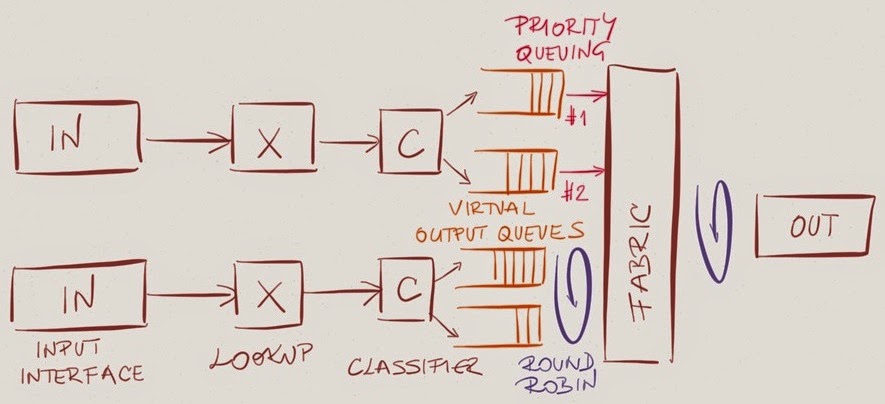
Virtual output queues solve the head-of-line (HoL) blocking between input ports (traffic received on one port cannot block traffic received on another port), but cannot solve HoL blocking problems between flows of the same traffic class entering the switch through the same input port.
Cell-based Fabrics
High-bandwidth chassis switches usually use multi-stage forwarding process:
- Input linecard performs address lookup, resulting in output linecard.
- Packets have to traverse the internal switching fabric (or backplane) to reach the output linecard. The packet forwarding process on input linecard usually results in packets being placed in linecard-to-fabric output queue (or virtual output queues, see above);
- Internal switching fabric transports packets from input to output linecards, either as soon as possible or triggered by output port requirements in VoQ environments;
- Output linecard queues the packet into one of the output queues, where it’s eventually picked up by interface hardware.
Transport across internal fabric might cause additional delays. After all, even though the switch uses virtual output queues, a jumbo frame transferred across the fabric delays short transaction requests traversing the same fabric lane (being sent between the same linecards).
Real-life analogy: being stuck behind a truck at highway roadworks.
Cell-based fabrics solve this problem by slicing the packets into smaller cells (reinventing ATM), and interleaving cells from multiple packets on a single path across the fabric.
Don't try to slice the truck in front of you into smaller cells. Analogies only go so far.
I have a question though. Is input queueing useful on the input port? some switches seem to support this.....??
For example, input ports 1 and 2 are both sending traffic to output port 8 of a switch. The sum of the traffic coming from 1&2 is greater than the capacity of port 8, so port 8 becomes oversubscribed. Ports 1&2 can’t send all the traffic that they want to port 8 across the fabric. So traffic backs up in the input queues of ports 1 & 2.
However, in addition to having traffic destined to output port 8, port 2 also receives traffic destined to output port 5. Output port 5 is unutilized, and is ready and waiting to accept traffic from port 2. But the traffic that port 2 has for output port 5 is sitting in port 2’s input queue. It can’t get to output port 5 until the traffic queued to output port 8 is cleared. So output port 5 continues to sit idle, even though the switch has traffic for it.
In this post, head-of-line blocking is used in the context of one application flow causing congestion that impacts another application flow. This is not necessarily head-of-line blocking, in the context of the description given just above, because it does not necessarily result in any un(der)utilized downstream resources. For all we know, the file transfer and the request response protocol could utilize the same downstream path, including the same destination server resources. In this case, you might get a better overall user experience using Weighted Fair Queuing, etc. to separate the file transfer from the request/response transaction. But it wouldn’t be head-of-line blocking, at least not by the definition of head-of-line blocking that I’m familiar with.
Along these lines, VoQ’s are typically created to be per-output port, so that traffic destined to different output ports go into different VoQ’s. In many cases queues may be both per-traffic class and per-output port, so that traffic can be differentiated in both dimensions. But with per-output port VoQ’s it would not generally be true that “Virtual output queues … cannot solve HoL blocking problems between flows of the same traffic”. It would only be true of flows of the same traffic class destined to the same output port.
If my understanding of head-of-line blocking is not what you believe matches common usage, by all means please correct me.
Is crossbar switching fabrics are used nowadays?