iSCSI and SAN: Two Decades of Rigid Mindsets
Greg Ferro asked a very valid question in his blog: “Why does iSCSI use TCP as the underlying transport protocol”? It’s possible to design storage-focused protocol that uses connectionless lower layers (NFS comes to mind), but the storage industry has been too focused on their past to see past the artificial obstacles they’ve set up themselves.
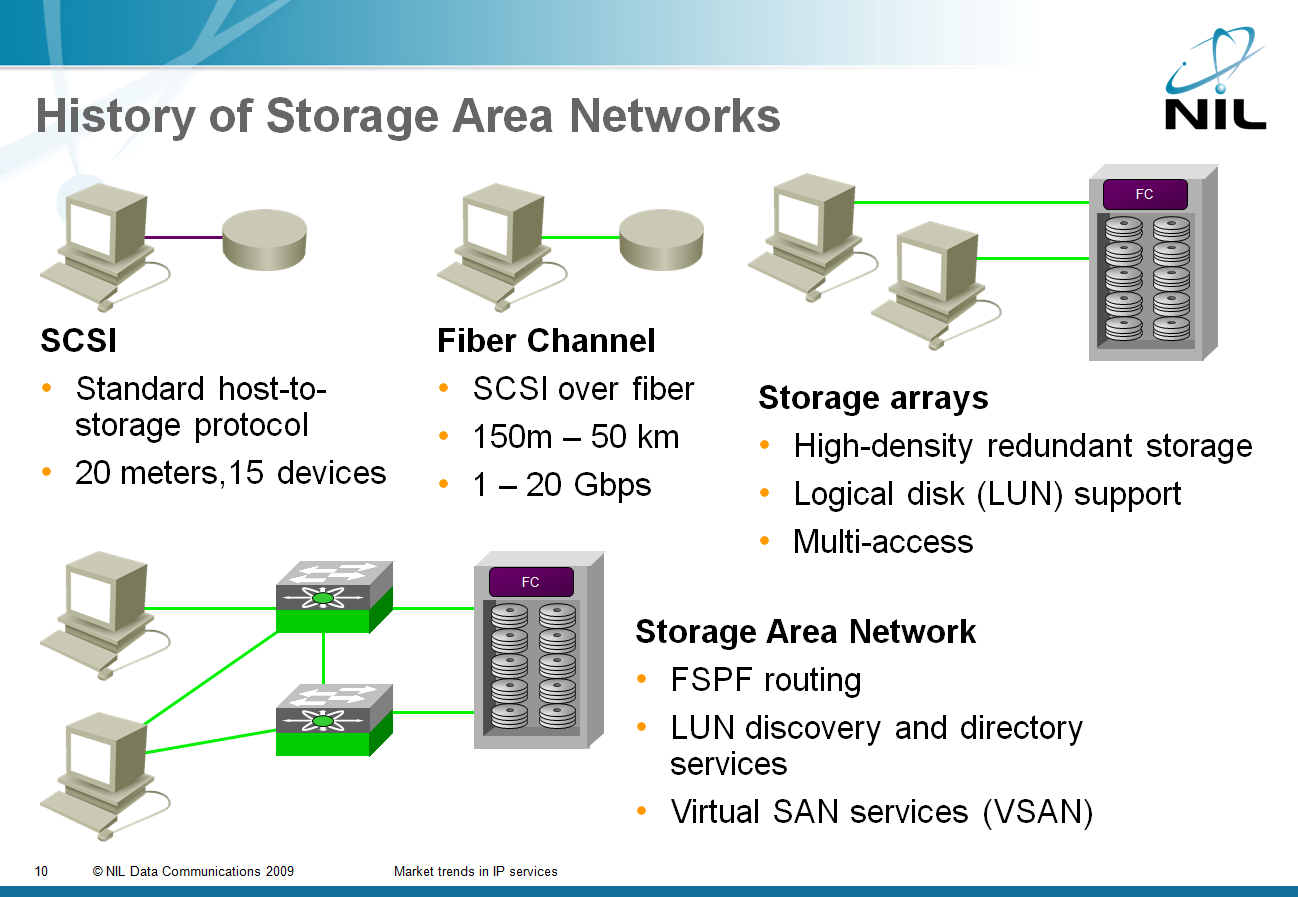
It all started in 1981 with SCSI: a standard way of connecting storage to hosts with ribbon cables. They’ve made the first mistake when they’ve decided to replace ribbon cables with fiber: instead of developing a network-oriented protocol, they replaced physical layer (cable) with another physical layer and retained whatever was running on top of the ribbon cable (SCSI command protocol). If they wanted this approach to work, the new transport infrastructure had to have similar characteristics to the old one: almost no errors, no lost frames and guaranteed bandwidth. And thus Fiber Channel was born.
The focus on low frame loss rate is a consequence of the design of the SCSI command protocol. SCSI was working well in an environment where errors occurred rarely enough that a long timeout and simple retransmission scheme did not hurt the performance. SCSI performance would suffer badly with an error- and loss rate of Ethernet- or IP-based networks, so the storage industry had three options:
- Change SCSI command protocol;
- Insert a reliable transport protocol between SCSI and unreliable lower layers;
- Invent a square wheel (design a lossless LAN).
Fiber Channel is option#3 and iSCSI and FCIP are following option#2. Now, keep in mind that both iSCSI and FCIP were designed by server/storage experts, not by internetworking experts. They didn’t want to go into the dirty details of reliable protocol design, so they chose whatever was readily available (TCP) and forgot to consider the performance implications (primarily the required processing power) of TCP overhead.
Those of you that are ancient enough to have encountered SNA (among other crazy things I was developing 3274-compatible cluster controllers in those days) might remember the various ways of transporting SNA-over-IP. The standard (DLSw) transported LLC2 over TCP and Cisco also offered FST which did not have the TCP-related overhead. However, there’s a major difference between SNA (LLC2) and SCSI: SNA was designed for lossy environments (it was first used over low-speed modem links) and had acceptable and decently fast error recovery procedures. FST’s only job was to ensure that the packets did not arrive out-of-order (an out-of-order packet caused immediate session reset).
You know my views on Storage networking, but you have explained the poor choices that the storage industry have chosen very well. Always the known and easy to understand which has led into the path of legacy lockup. Similarities with Microsoft Windows are striking.
greg
Incidentally, in certain applications (e.g. VMware), NFS over TCP is a requirement so I wouldn't point to NFS as a connectionless storage protocol. Perhaps I'm misreading the statement? Incidentally, there are people in the VMware world that wouldn't trade their NFS mounts for a FC LUN.
At a certain point, and actually it's quite low, aggregate network (FC included) transport throughput outstrips storage subsystem throughput. The typical SAN is many-to-one; initiators and targets respectively. The ultimate measure of storage subsystem performance isn't throughput in bits/sec at all. It's IOPs. What drives IOPs? Type, quantity and layout of the spindles, RAID levels and settings appropriate for the application. Bad storage subsystem design often has more to do with poor "SAN" performance than the networking protocol.
I think the FC/iSCSI airgap does have value in a meatspace context. The storage people have their sandbox and the FC people have theirs. With iSCSI and FCoE that gap is vacuumed out with the networking people telling the storage people how to do things and vice-versa.
Lastly, I'm constantly forwarding posts from this blog to peers. Great stuff!
regards
KIRAN
I only say this because I was just taking a course where they show how to replace legacy SS7 protocol running over TDM/T1 with SIGTRAN, which is SS7 running over IP, but instead of using UDP or TCP they use SCTP instead.
Looks like it could be applicable.
http://blog.ioshints.info/2009/08/what-went-wrong-sctp.html