Category: switching
Video: 400GbE Optics
When 400GbE was still an emerging technology, Mark Nowell explained its basics in an update session of the Data Center Fabric Architectures webinar, starting with 400GbE optics.
180 Gbps Software-Only Linux Router
Pim van Pelt built an x86/Linux-based using Vector Packet Processor that can forwarding IP traffic at 150 Mpps/180 Gbps forwarding rates on a 2-CPU Dell server with E5-2660 (8 core) CPU.
He described the whole thing in a 8-part series of blog posts and a conference talk. Enjoy!
… updated on Sunday, April 16, 2023 15:50 UTC
ChatGPT Explaining the Need for iSCSI CRC
People keep telling me how well large language models like ChatGPT work for them, so now and then, I give it another try, most often resulting in another disappointment1. It might be that I suck at writing prompts2, or it could be that I have a knack for looking in the wrong places3.
This time4 I tried to “figure out5” why we need iSCSI checksums if we have iSCSI running over Ethernet which already has checksums. Enjoy the (ChatGPT) circular arguments and hallucinations with plenty of platitudes and no clear answer.
Turning WiFi into a Thick Yellow Cable
The “beauty” (from an attacker perspective) of the original shared-media Ethernet was the ability to see all traffic sent to other hosts. While it’s trivial to steal someone else’s IPv4 address, the ability to see their traffic allowed you to hijack their TCP sessions without the victim being any wiser (apart from the obvious session timeout). Really smart attackers could go a step further, insert themselves into the forwarding path, and inject extra payload into unencrypted sessions.
A recently-discovered WiFi vulnerability brought us back to that wonderful world.
Video: Chassis Switch Architectures
Did you know most chassis switches look like leaf-and-spine fabrics1 from the inside? If you didn’t, you might want to watch the short Chassis Architectures video by Pete Lumbis (author of ASICs for Networking Engineers part of the Data Center Fabric Architectures webinar).
Dynamic MAC Learning: Hardware or CPU Activity?
An ipSpace.net subscriber sent me a question along the lines of “does it matter that EVPN uses BGP to implement dynamic MAC learning whereas in traditional switching that’s done in hardware?” Before going into those details, I wanted to establish the baseline: is dynamic MAC learning really implemented in hardware?
Hardware-based switching solutions usually use a hash table to implement MAC address lookups. The above question should thus be rephrased as is it possible to update the MAC hash table in hardware without punting the packet to the CPU? One would expect high-end (expensive) hardware to be able do it, while low-cost hardware would depend on the CPU. It turns out the reality is way more complex than that.
Video: Packet Buffers in Data Center ASICs
A few years ago, we were fortunate enough to have Pete Lumbis talking about ASICs for Networking Engineers as part of the Data Center Fabric Architectures webinar.
One of the topics he couldn’t possibly skip was the question of how many packet buffers one needs in a data center switch.
Will DPUs Change the Network?
It’s easy to get excited about what seems to be a new technology and conclude that it will forever change the way we do things. For example, I’ve seen claims that SmartNICs (also known as Data Processing Units – DPU) will forever change the network.
TL&DR: Of course they won’t.
Before we start discussing the details, it’s worth remembering what a DPU is: it’s another server with its own CPU, memory, and network interface card (NIC) that happens to have PCI hardware that emulates the host interface cards. It might also have dedicated FPGA or ASICs.
A Quick Look at AWS Scalable Reliable Datagram Protocol
One of the most exciting announcements from the last AWS re:Invent was the Elastic Network Adapter (ENA) Express functionality that uses the Scalable Reliable Datagram (SRD) protocol as the transport protocol for the overlay virtual networks. AWS claims ENA Express can push 25 Gbps over a single TCP flow and that SRD improves the tail latency (99.9 percentile) for high-throughput workloads by 85%.
Ignoring the “DPUs could change the network forever” blogosphere reactions (hint: they won’t), let’s see what could be happening behind the scenes and why SRD improves TCP throughput and tail latency.
DPU Hype Considered Harmful
The hype generated by the “VMware supports DPU offload” announcement already resulted in fascinating misunderstandings. Here’s what I got from a System Architect:
We are dealing with an interesting scenario where a customer had limited data center space, but applications demand more resources. We are evaluating whether we could offload ESXi processing to DPUs (Pensando) to use existing servers as bare-metal servers. Would it be a use case for DPU?
First of all, congratulations to whichever vendor marketer managed to put that guy in that state of mind. Well done, sir, well done. Now for a dose of reality.
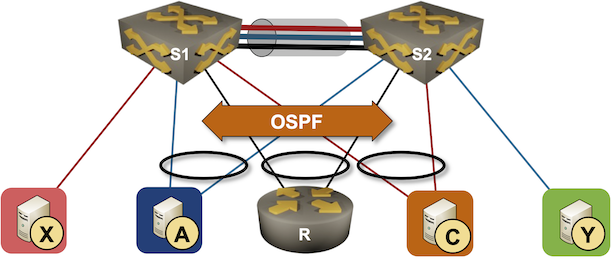
Running Routing Protocols over MLAG Links
It took vendors like Cisco years to start supporting routing protocols between MLAG-attached routers and a pair of switches in the MLAG cluster. That seems like a no-brainer scenario, so there must be some hidden complexities. Let’s figure out what they are.
We’ll use the familiar MLAG diagram, replacing one of the attached hosts with a router running a routing protocol with both members of the MLAG cluster (for example, R, S1, and S2 are OSPF neighbors).
Are DPUs Any Good?
After VMware launched DPU-based acceleration for VMware NSX, marketing-focused websites frantically started discussing the benefits of DPUs. Although I’ve been writing about SmartNICs and DPUs for years, it’s time for another closer look at the emperor’s clothes.
What Is a DPU
DPU (Data Processing Unit) is a fancier name for a network adapter formerly known as SmartNIC – a server repackaged into an interface card form factor. We had them for decades (anyone remembers iSCSI offload adapters?)
… updated on Wednesday, September 28, 2022 17:22 UTC
Combining MLAG Clusters with VXLAN Fabric
In the previous MLAG Deep Dive blog posts, we discussed the innards of a standalone MLAG cluster. Now let’s see what happens when we connect such a cluster to a VXLAN fabric – we’ll use our standard MLAG topology and add a VXLAN transport underlay to it with another switch connected to the other end of the underlay network.
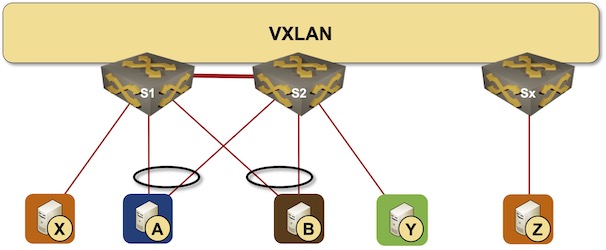
MLAG cluster connected to a VXLAN fabric
… updated on Tuesday, March 11, 2025 13:48 +0100
VLAN Interfaces and Subinterfaces
Early bridges implemented a single bridging domain across all ports. Within a few years, we got multiple bridging domains within a single device (including bridging implementation in Cisco IOS). The capability to have multiple bridging domains stretched across several devices was still missing… until the modern-day Pandora opened the VLAN box and forever swamped us in the complexities of large-scale bridging.
How Routers Became Bridges
Network terminology was easy in the 1980s: bridges forwarded frames between Ethernet segments based on MAC addresses, and routers forwarded network layer packets between network segments. That nirvana couldn’t last long; eventually, a big enough customer told Cisco: “I don’t want to buy another box if I already have your too-expensive router. I want your router to be a bridge.”
Turning a router into a bridge is easier than going the other way round1: add MAC table and dynamic MAC learning, and spend an evening implementing STP.