Category: IP routing
Unequal-Cost Multipath with BGP DMZ Link Bandwidth
In the previous blog post in this series, I described why it’s (almost) impossible to implement unequal-cost multipathing for anycast services (multiple servers advertising the same IP address or range) with OSPF. Now let’s see how easy it is to solve the same challenge with BGP DMZ Link Bandwidth attribute.
I didn’t want to listen to the fan noise generated by my measly Intel NUC when simulating a full leaf-and-spine fabric, so I decided to implement a slightly smaller network:
Routing Protocols: Use the Best Tool for the Job
When I wrote about my sample OSPF+BGP hands-on lab on LinkedIn, someone couldn’t resist asking:
I’m still wondering why people use two routing protocols and do not have clean redistribution points or tunnels.
Ignoring for the moment the fact that he missed the point of the blog post (completely), the idea of “using tunnels or redistribution points instead of two routing protocols” hints at the potential applicability of RFC 1925 rule 4.
Unnumbered Ethernet Interfaces
Imagine an Internet Service Provider offering Ethernet-based Internet access (aka everyone using fiber access, excluding people believing in Russian dolls). If they know how to spell security, they might be nervous about connecting numerous customers to the same multi-access network, but it seems they have only two ways to solve this challenge:
- Use private VLANs with proxy ARP on the head-end router, forcing the customer-to-customer traffic to pass through layer-3 forwarding on the head-end router.
- Use a separate routed interface with each customer, wasting three-quarters of their available IPv4 address space.
Is there a third option? Can’t we pretend Ethernet works in almost the same way as dialup and use unnumbered IPv4 interfaces?
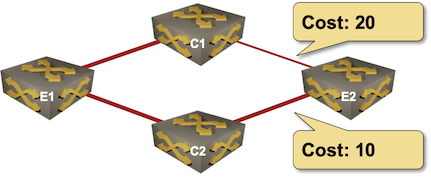
Single-Metric Unequal-Cost Multipathing Is Hard
A while ago, we discussed whether unequal-cost multipathing (UCMP) makes sense (TL&DR: rarely), and whether we could implement it in link-state routing protocols (TL&DR: yes). Even though we could modify OSPF or IS-IS to support UCMP, and Cisco IOS XR even implemented those changes (they are not exactly widely used), the results are… suboptimal.
Imagine a simple network with four nodes, three equal-bandwidth links, and a link that has half the bandwidth of the other three:
Packet Forwarding and Routing over Unnumbered Interfaces
In the previous blog posts in this series, we explored whether we need addresses on point-to-point links (TL&DR: no), whether it’s better to have interface or node addresses (TL&DR: it depends), and why we got unnumbered IPv4 interfaces. Now let’s see how IP routing works over unnumbered interfaces.
The Challenge
A cursory look at an IP routing table (or at CCNA-level materials) tells you that the IP routing table contains prefixes and next hops, and that the next hops are IP addresses. How should that work over unnumbered interfaces, and what should we use for the next-hop IP address in that case?
Worth Exploring: Working with Linux VRFs
I remember having an interesting discussion about Linux VRFs (as opposed to namespaces) with Dinesh Dutt years ago, but it looks like I never turned it into a blog post.
Now I won’t have to 😉 – Jon Langemak published an excellent Working with Linux VRFs deep dive.
Back to Basics: Unnumbered IPv4 Interfaces
In the previous blog post in this series, we explored some of the reasons IP uses per-interface (and not per-node) IP addresses. That model worked well when routers had few interfaces and mostly routed between a few LAN segments (often large subnets of a Class A network assigned to an academic institution) and a few WAN uplinks. In those days, the WAN networks were often implemented with non-IP technologies like Frame Relay or ATM (with an occasional pinch of X.25).
The first sign of troubles in paradise probably occurred when someone wanted to use a dial-up modem to connect to a LAN segment. What subnet (and IP address) do you assign to the dial-up connection, and how do you tell the other end what to use? Also, what do you do when you want to have a bank of modems and dozens of people dialing in?
Back to Basics: The History of IP Interface Addresses
In the previous blog post in this series, we figured out that you might not need link-layer addresses on point-to-point links. We also started exploring whether you need network-layer addresses on individual interfaces but didn’t get very far. We’ll fix that today and discover the secrets behind IP address-per-interface design.
In the early days of computer networking, there were three common addressing paradigms:
Video: IP Routing Fundamentals
A few weeks ago we covered transparent bridging fundamentals, now it’s time to recap IP routing fundamentals… and then we’ll be ready to compare the two.
Back to Basics: Do We Need Interface Addresses?
In the world of ubiquitous Ethernet and IP, it’s common to think that one needs addresses in packet headers in every layer of the protocol stack. We have MAC addresses, IP addresses, and TCP/UDP port numbers… and low-level addresses are assigned to individual interfaces, not nodes.
Turns out that’s just one option… and not exactly the best one in many scenarios. You could have interfaces with no addresses, and you could have addresses associated with nodes, not interfaces.
… updated on Tuesday, February 15, 2022 15:00 UTC
Building Unnumbered Ethernet Lab with netlab
Last week I described the new features added to netsim-tools release 0.4, including support for unnumbered interfaces and OSPF routing. Now let’s see how I used them to build a multi-vendor lab to test which platforms could be made to interoperate when running OSPF over unnumbered Ethernet interfaces.
- This blog post has been updated to use the new netlab CLI introduced in netsim-tools release 0.8 and new IPAM features introduced in release 1.0
- netsim-tools project has been renamed to netlab.
Unequal-Cost Multipath in Link State Protocols
TL&DR: You get unequal-cost multipath for free with distance-vector routing protocols. Implementing it in link state routing protocols is an order of magnitude more CPU-consuming.
Continuing our exploration of the Unequal-Cost Multipath world, why was it implemented in EIGRP decades ago, but not in OSPF or IS-IS?
Ignoring for the moment the “does it make sense” dilemma: finding downstream paths (paths strictly shorter than the current best path) is a side effect of running distance vector algorithms.
Video: Path Discovery in Transparent Bridging and Routing
In the previous video in this series, I described how path discovery works in source routing and virtual circuit environments. I couldn’t squeeze the discussion of hop-by-hop forwarding into the same video (it would make the video way too long); you’ll find it in the next video in the same section.
… updated on Friday, March 5, 2021 16:22 UTC
Chasing Anycast IP Addresses
One of my readers sent me this question:
My job required me to determine if one IP address is unicast or anycast. Is it possible to get this information from the bgp dump?
TL&DR: Not with anything close to 100% reliability. An academic research paper (HT: Andrea di Donato) documents a false-positive rate of around 10%.
If you’re not familiar with IP anycast: it’s a brilliant idea of advertising the same prefix from multiple independent locations, or the same IP address from multiple servers. Works like a charm for UDP (that’s how all root DNS servers are built) and supposedly pretty well across distant-enough locations for TCP (with a long list of caveats when used within a data center).
Does Unequal-Cost Multipathing Make Sense?
Every now and then I’m getting questions along the lines “why doesn’t X support unequal-cost multipathing (UCMP)?” for X in [ OSPF, BGP, IS-IS ].
To set the record straight: BGP does support some rudimentary form of unequal-cost multipathing with the DMZ Bandwidth community, but it only works across multiple egress points from a single autonomous system. Follow-up nerd knobs described how to use the same community over EBGP sessions; not sure whether anyone implemented that part (comments welcome).