vSphere Does Not Need LAG Bandaids – the Network Might
Chris Wahl claimed in one of his recent blog posts that vSphere doesn't need LAG band-aids. He's absolutely right – vSphere’s loop prevention logic alleviates the need for STP-blocked links, allowing you to use full server uplink bandwidth without the complexity of link aggregation. Now let’s consider the networking perspective.
The conclusions Chris reached are perfectly valid in a classic data center or VDI environment with majority of the VM-generated traffic leaving the data center; the situation is drastically different in data centers with predominantly east-west traffic (be it inter-server or IP-based storage traffic).
Let’s start with a simple scenario:
- Data center is small enough to have only two switches.
- Two vSphere servers are connected to the two data center switches in a fully redundant setup (each server has one uplink to each ToR switch).
- Load-Based Teaming (LBT) is used within vSphere instead of IP-based hash (vSphere terminology for a Link Aggregation Group).
The two ToR switches are not aware of the exact VM placement, resulting in traffic flowing across inter-switch link even when it could be exchanged locally.
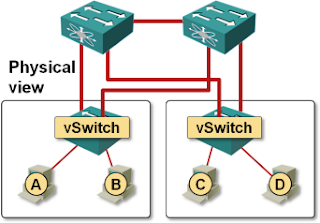
Physical connectivity
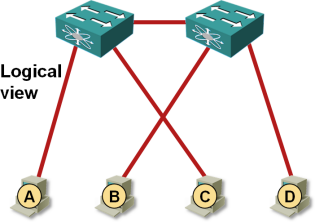
VM MAC reachability as seen by the switches
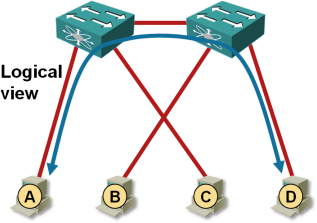
Traffic flow between VMs on adjacent hypervisor hosts
Can We Fix It?
You can fix this problem by making most endpoints equidistant. You could introduce a second layer of switches (resulting in a full-blown leaf-and-spine fabric) or you could connect the servers to a layer of fabric extenders1, which would also ensure the traffic between any two endpoints gets equal treatment.
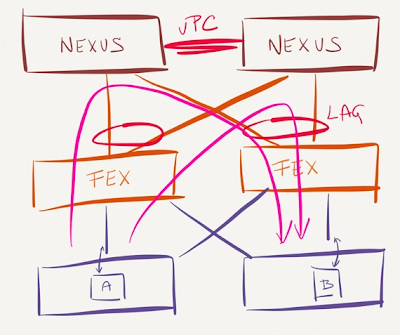
Traffic between VMs appearing near to each other in a leaf-and-spine fabric gets better treatment than any other traffic (no leaf-to-spine oversubscription); in the FEX scenario all traffic gets identical treatment as FEX still doesn’t support local switching.
The leaf-and-spine (or FEX) solution obviously costs way more than a simple two-switch solution, so might consider:
- Using link aggregation and LACP with vSphere or
- Changing your mind and not using all uplinks for VM traffic.
But LBT Works So Much Better
Sure it does (and Chris provided some very good arguments for that claim in his blog post), but there’s nothing in the 802.1ax standard dictating the traffic distribution mechanism on a LAG. VMware could have decided to use LBT with a LAG, but they didn’t (because deep inside the virtual switch they tie the concept of a link aggregation group to the IP hash load balancing mechanism). Don’t blame standards and concepts for suboptimal implementations ;)
But Aren’t Static Port Channels Unreliable?
Of course they are; I wouldn’t touch them with a 10-foot pole. You should always use LACP to form a LAG, but VMware supports LACP only in the distributed switch which requires Enterprise Plus or NSX license2. Yet again, don’t blame the standards or network design requirements, blame a vendor that wants to charge extra for baseline layer-2 functionality.
Is There Another Way Out?
Buying extra switches (or fabric extenders) is too expensive. Buying Enterprise Plus license for every vSphere host just to get LACP support is clearly out of question. Is there something else we could do? Of course:
- Don’t spread VM traffic across all server uplinks. Dedicate uplinks connected to one switch primarily to VM traffic and use other uplinks primarily for vMotion or storage traffic. Use active/standby failover on uplinks to make sure you don’t lose connectivity after a link failure.
- Make sure the inter-switch link gets enough bandwidth.
Typical high-end ToR switches (from almost any vendor) have 48 10GE/25GE/100GE ports3 and four ports that are four times faster (40GE/100GE/400GE). Using the faster ports for inter-switch links results in worst-case 3:1 oversubscription (48 lower-speed ports on the left-hand switch communicate exclusively with the 48 10GE ports on the right-hand switch over an equivalent of 16 10GE ports). Problem solved.
-
I wouldn’t, fabric extenders are a nightmare. Also, try to get better pricing for leaf switches by mentioning other vendors ;) ↩︎
-
Like all other vendors, VMware loves to change its licensing. Check VMware documentation for up-to-date details. ↩︎
-
Depending on switch model and when you’re reading this blog post. ↩︎
What's the max reasonable oversubscription you recommend? Would Chassis Trunking from Brocade be interesting as Aggregation L3 Switch Solution ?
Thanks
Personally I would much happier if the Nexus 1000v implemented Fabricpath alleviating the need for any kind of LAG on the vhost uplinks. But this is a logical and efficient way to connect vhosts to a network so I'm not expecting Cisco to go that way!
Vswitch dual connected to N4k's that have multiple up links to vpc N5k pair.
When we reload a N4k, the VM fail over is perfect, but when the N4k comes back we lose half the VM's for 30th.
My understanding is that Vswitch starts using new up link immediately as physical port comes up but spanning tree on unlink ports is still learning topology.
To understand the issue, you may want to read this blog post: http://frankdenneman.nl/2010/10/22/vswitch-failover-and-high-availability/
Isn't MPIO to be preferred over LACP since MPIO can use all the links simultaneously?
I'm currently working on an environment where VMware ESXi servers are dual-homed (and statically LAGged) to a pair of FEX 2232. These extenders are currently single-homed to a pair of Nexus 5548 on vPC. I want to move away from the LAGs at the server level but by doing this I'll start running into the problems you describe above (potential over-subscription of the vPC peer-link, etc.). So, dual-homing the FEXes seems like the logical thing to do.
I've been doing some research into the reasons why I would like to avoid dual-homing the FEXes and so far I've come up with three:
a) Config of the FEX's interfaces need to be defined in both Nexus... for instance port 100/1/25 exists in both parent Nexus, so the config needs to be consistent across both --> not a big deal in my book... plus using config-sync and switch profiles should help simplify or avoid this problem
b) The total limit of FEXes supported by the vPC is cut in half, since every Nexus parent switch will be connected to all the FEXes --> not a big deal either for the environment I'm working on
c) On a single-homed deployment every FEX is dependant upon a single parent Nexus. If the parent Nexus "A" fails or crashes, only the "A" FEXes will be affected. On a dual-homed deployment all the FEXes are dependant upon both parent Nexus... under certain circumstances this could be defined as a SPOF. Of course an argument could be had regarding the vPC concept as being a SPOF itself... at some point you have to trust the vendor and its code, right?
What's your take on these problems, particularly on the third one. Do you think there are any other limitations worth considering before migrating from a single-homed to a dual-homed config?
Thanks!
Never went into the details of how dual-homed FEXes handle upstream switch failure, but AFAIK it's not a SPOF.