Blog Posts in January 2012
FIB Update Challenges in OpenFlow Networks
Last week I described the problems high-end service provider routers (or layer-3 switches if you prefer that terminology) face when they have to update large number of entries in the forwarding tables (FIBs). Will these problems go away when we introduce OpenFlow into our networks? Absolutely not, OpenFlow is just another mechanism to download forwarding entries (this time from an external controller) not a laws-of-physics-changing miracle.
Prefix-Independent Convergence (PIC): Fixing the FIB Bottleneck
Did you rush to try OSPF Loop-Free Alternate on a Cisco 7200 after reading my LFA blog post… and disappointedly discovered that it only works on Cisco 7600? The reason is simple: while LFA does add feasible-successor-like behavior to OSPF, its primary mission is to improve RIB-to-FIB convergence time.
Loop-Free Alternate: OSPF Meets EIGRP
Assume we have a simple triangular network:
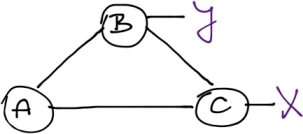
Now imagine the A-to-C link fails. How will OSPF react to the link failure as compared to EIGRP? Which one will converge faster? Try to answer the questions before pressing the Read more link ;)
VXLAN runs over UDP – does it matter?
Scott Lowe asked a very good question in his Technology Short Take #20:
VXLAN uses UDP for its encapsulation. What about dropped packets, lack of sequencing, etc., that is possible with UDP? What impact is that going to have on the “inner protocol” that’s wrapped inside the VXLAN UDP packets? Or is this not an issue in modern networks any longer?
Short answer: No problem.
Redundant DMVPN Designs, Part 2 (Multiple Uplinks)
In the Redundant DMVPN Design, Part 1 I described the options you have when you want to connect non-redundant spokes to more than one hub. In this article, we’ll go a step further and design hub and spoke sites with multiple uplinks.
Public IP Addressing
Fact: DMVPN tunnel endpoints have to use public IP addresses or the hub/spoke routers wouldn’t be able to send GRE/IPsec packets across the public backbone.
DHCPv6 Prefix Delegation with Radius Works in IOS Release 15.1
A while ago I described the pre-standard way Cisco IOS used to get delegated IPv6 prefixes from a RADIUS server. Cisco’s documentation always claimed that Cisco IOS implements RFC 4818, but you simply couldn’t get it to work in IOS releases 12.4T or 15.0M. In December I wrote about the progress Cisco is making on the DHCPv6 front and [email protected] commented that IOS 15.1S does support RFC 4818. You know I absolutely had to test that claim ... and it’s true!
… updated on Tuesday, November 17, 2020 16:49 UTC
IP Renumbering in Disaster Avoidance Data Center Designs
It’s hard for me to admit, but there just might be a corner use case for split subnets and inter-DC bridging: even if you move a cold VM between data centers in a controlled disaster avoidance process (moving live VMs rarely makes sense), you might not be able to change its IP address due to hard-coded IP addresses, be it in application code or configuration files.
Disaster recovery is a different beast: if you’ve lost the primary DC, it doesn’t hurt if you instantiate the same subnet in the backup DC.
IPv6 ND Managed-Config-Flag Is Just a Hint
IPv6 hosts can use stateless or stateful autoconfiguration. Stateless address autoconfiguration (SLAAC) uses IPv6 prefixes from Router Advertisement (RA) messages; stateful autoconfiguration uses DHCPv6. The routers can use two flags in RA messages to tell the attached end hosts which method to use:
- Managed-Config-Flag tells the end-host to use DHCPv6 exclusively;
- Other-Config-Flag tells the end-host to use SLAAC to get IPv6 address and DHCPv6 to get other parameters (DNS server address, for example).
- Absence of both flags tells the end-host to use only SLAAC.
One might assume that setting managed-config-flag in RA messages forces IPv6 hosts to use DHCPv6. Wrong, the two flags are just a polite suggestion.
Redundant DMVPN designs, Part 1 (The Basics)
Most of the DMVPN-related questions I get are a variant of the “how many tunnels/hubs/interfaces/areas do I need for a redundant DMVPN design?” As always, the right answer is “it depends”, but here’s what I’ve learned so far.
Single Router/Single Uplink on Spoke Site
This blog post focuses on the simplest possible design – each spoke site has a single router and a single uplink. There’s no redundancy at the spokes, which might be an acceptable tradeoff (or you could use 3G connection as a backup for DMVPN).
You’d probably want to have two hub routers (preferably with independent uplinks), which brings us to the fundamental question: “do we need one or two DMVPN clouds?”
… updated on Wednesday, November 18, 2020 06:44 UTC
Filter Inbound BGP Prefixes: Summary
I got plenty of responses to the How could we filter extraneous BGP prefixes post, some of them referring to emerging technologies and clean-slate ideas, others describing down-to-earth approaches. Thank you all, you’re fantastic!
Almost everyone in the “down-to-earth” category suggested a more or less aggressive inbound filter combined with default routing toward upstream ISPs. Ideally the upstream ISPs would send you responsibly generated default route, or you could use static default routes toward well-known critical infrastructure destinations (like root name servers).
How could we filter extraneous BGP prefixes?
Did you know that approximately 40% of BGP prefixes polluting your RIB and FIB are not needed, as they could be either aggregated or suppressed (because an aggregate is already announced)? We definitely need “driver’s license for the Internet”, but that’s not likely to happen, and in the meantime everyone has to keep buying larger boxes to cope with people who cannot configure their BGP routing correctly.
… updated on Thursday, May 13, 2021 15:42 UTC
BGP-Free Service Provider Core in Pictures
I got a follow-up question to the Should I use 6PE or native IPv6 post:
Am I remembering correctly that if you run IPv6 native throughout the network you need to enable BGP on all routers, even P routers? Why is that?
I wrote about BGP-free core before, but evidently wasn’t clear enough, so I’ll try to fix that error.
Imagine a small ISP with a customer-facing PE-router (A), two PE-routers providing upstream connectivity (B and D), a core router (C), and a route reflector (R). The ISP is running IPv4 and IPv6 natively (no MPLS).
Can We Really Ignore Spaghetti and Horseshoes?
Brad Hedlund wrote a thought-provoking article a few weeks ago, claiming that the horseshoes (or trombones) and spaghetti created by virtual workloads and appliances deployed anywhere in the network don’t matter much with new data center designs that behave like distributed switches. In theory, he’s right. In practice, less so.
Should I Use 6PE or Native IPv6 Transport?
One of my students was watching the Building IPv6 Service Provider Core webinar and wondered whether he should use 6PE or native IPv6 transport:
Could you explain further why it is better to choose 6PE over running IPv6 in the core? I have to implement IPv6 where I work (a small ISP) and need to fully understand why I should choose a certain implementation.
Here’s a short decision tree that should help you make that decision:
Prevent bridging loops without BPDUs?
Anton sent me an interesting question:
Most IP phones have a network facing port and a port for user to connect the PC. Today a user plugged in both of these ports into the switch. It looks like phone filters out BPDUs, so the switch did not catch this loop. Do you know of a feature or design that would be able to catch/prevent this type of event?
My answer would be “no, there’s nothing you can do if you have a broken device that acts like a STP-less switch” but you know I’m not a switching or IP telephony guru. Any ideas?
Are Provider-Independent IPv6 Prefixes Really Global?
Aleksej sent me an intriguing question: “Can the /48 PI block that a global company is assigned be attached to any region, or it is region-specific?”, or, more specifically:
Imagine a company with major DC with public services in EMEA. Centralized internet break-out in Europe fails and this DC must be reachable from Asia or America - but with the same IPv6 address? That would require Asia or America's ISPs to accept injection of this same subnet in their region. Do they do that?
In theory, the answer is yes. In practice, some global organizations are hedging their bets.