Data Center Bridging (DCB) Congestion Notification (802.1Qau)
The last (and the least popular) Data Center Bridging (DCB) standard tries to solve the problem of congestion in large bridged domains (PFC enables lossless transport and ETS standardizes DWRR queuing). To illustrate the need for congestion control, consider a simple example shown in the following diagram:
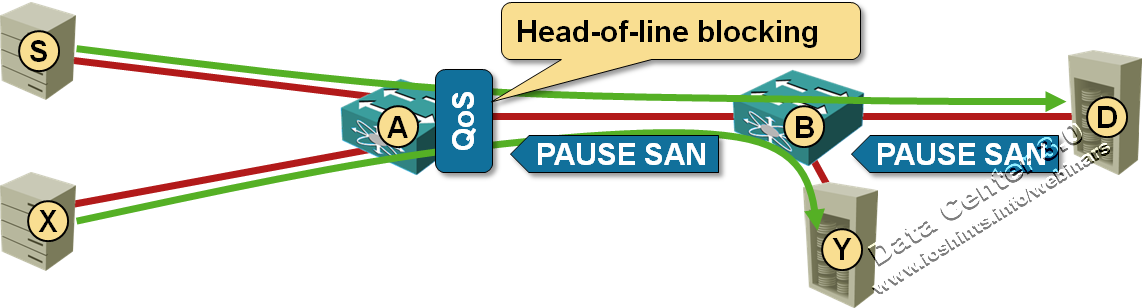
It came to my attention that a vendor might be using this blog post to justify the need for QCN in FCoE environments. Should that be the case, please make sure you also read about the difference between dense and sparse FCoE, the (lack of) need for QCN in FCoE and whether it makes sense to run FCoE over TRILL. Finally, consider how you’ll troubleshoot FCoE environments.
Server S writes large amounts of data to a slow storage array D, which has to use PFC PAUSE frame to tell the upstream switch B to stop sending SAN (for example, FCoE) traffic. Eventually switch B runs out of buffer space and has to tell switch A to stop sending SAN traffic.
At that time, the A-to-B link is blocked for SAN traffic, so server X cannot write data to disk Y, even though the path X-A-B-Y is not congested. Obviously we need a mechanism that would allow switch B to tell S to stop without affecting other traffic.
The example is very simplistic, worse problems arise when a local congestion of an oversubscribed inter-switch link spills over into upstream switches without a single end-to-end session getting slowed down by the end hosts.
The 802.1Qau standard tries to solve the large-scale congestion problem with the Quantized Congestion Notification (QCN) protocol, which the bridges can use to send the Congestion Notification Messages (CNM) to the senders (end hosts).
The bridges (congestion points) constantly monitor output queues sizes. When the output queue size grows beyond an (implementation-dependent) optimum point and is still increasing, CNM is sent back to the sender of a frame entering the output queue with probability (between 1% and 10%) that depends on the severity of the congestion. Lightly-congested output queues will cause a CNM to be sent on every 100th packet (on average, it’s a random process); highly congested queues will send a CNM on every 10th packet.
Frames with different 802.1p priority values are usually sorted into different output queues. 802.1Qau is thus automatically priority-aware and will not send CNMs to senders in other priority classes (assuming those priority classes don’t have overloaded output queues).
The CNM contains several fields that help the sender identify the cause of the congestion: 802.1p priority value, destination MAC address and first few bytes of the offending message. It also contains a 6-bit indication of the congestion severity that the sender must use to adjust the outgoing traffic rate.
After receiving CNM, the sender (reaction point) slows down the offending traffic based on the congestion severity value (maximum: 50%) and enters Fast Recovery phase, during which the sending rate is slowly increased until it gets close to the value it had before the CNM message was received (after 150 kilobytes worth of data is sent, the sending rate is increased by half the difference between the current and target sending rate). If no further CNM messages are received after five cycles (750 kilobytes), the sender switches to Active Increase mode, where the sending rate increases beyond the original value (unless, of course, another CNM is received).
Interesting details
- QCN makes most sense for lossless traffic. In most cases packet drops are good enough for loss-tolerant traffic.
- Simulations indicate QCN can also improve TCP and UDP performance and make UDP “fair” (assuming senders use a separate shaping queue for UDP and rate-limit that queue based on CNMs). See slides 21-27 of this presentation.
- QCN works across a single layer-2 domain. As soon as the traffic crosses a router (or FCoE switch), it enters a different QCN domain.
- QCN has to be implemented in hardware on bridges and all end-hosts (responding to CNM messages in software on 10 GE links is probably too slow).
- It’s extremely unlikely that the existing hardware will be able to support QCN. You’ll probably have to change all the server/storage NICs and all the linecards in your switches before deploying QCN (unless someone figures out a way to do fast-enough QCN in software).
- QCN requires multiple shaping queues on every QCN-enabled host, making host NICs more expensive.
- IEEE working group changed the congestion notification details a few times, the last time from simple Backward Congestion Notification (BCN) to Quantized Congestion Notification (QCN). A vendor or two that relied on BCN being ratified probably had to scrap their already-developed hardware.
Taking all these details in account, I don’t expect to see QCN deployed in production networks any time soon (if at all). According to Pat Thaler (see the comments), 802.1Qau has been ratified in March 2010 (obviously someone forgot to update the IEEE 802.1 web page, which at the time I’m writing this post still lists 802.1Qau as an active project) and I haven’t heard about production-ready chipsets yet.
Update 2010-11-17: The original version of this post contained two factual errors: FCoE does not have BB_credits and the 802.1Qau standard was ratified in March 2010. I would like to thank Pat Thaler for bringing them to my attention.
More information
If you’d like to hear more about emerging Data Center technologies, including Data Center Bridging, Shortest Path Bridging (TRILL, FabricPath and 802.1aq) and FCoE, watch my Data Center 3.0 for Networking Engineers webinar (buy a recording or yearly subscription).
Your first note about buffer credit is incorrect. Buffer-to-buffer credit in Fibre Channel is the credit mechanism used hop by hop to ensure that the next device has buffer available before a frame is sent. In FCoE, PFC is used instead and there is no buffer-to-buffer credit. End-to-end credit is used for some Fibre Channel classes but not by Class 3 which is the class that will generally be used with FCoE. (Class 2 is used by some protocols running over FC for establishing connections but generally not for bulk data transfer.) Therefore, the situation in your example is not prevented by FCoE.
While practical implementation of CN generally will require some hardware support, 802.1Qau is designed to minimize the amount of state needed so it shouldn't be expensive to implement. The biggest unknown is regarding the persistence of congestion in the data center. It takes time for CN messages to be generated and slow down the sources. If congestion is very brief, the congestion could be over before CNMs arrive to quench it. If congestion is persistent, then CN will be useful.
Ivan
Looking at various IEEE web pages (including 802.1 main web page, DCB page or 802.1Qau page) I couldn't find a way to figure out that 802.1Qau is an approved standard. Now that I know what state it's i, it was trivial to find it on GetIEEE site :'( . Lesson learned.