Category: EIGRP
Scaling EIGRP Networks with Stub Routers
Enhanced Interior Gateway Routing Protocol (EIGRP), Cisco’s proprietary yet hugely successful and widely deployed routing protocol, is known to behave disappointingly in inadequately designed networks. Cisco has improved EIGRP’s behavior dramatically with the introduction of stub routers in Cisco IOS release 12.0(7)T (integrated in IOS release 12.1, thus being available for a number of years). However, this feature has remained a well-hidden mystery, appearing in a short whitepaper, a Networkers presentation and getting a few slides in Building Scalable Cisco Internetworks (BSCI) course.
In this article, we’ll explore the typical problems that the EIGRP stub routers help to solve, see how the introduction of stub routers improves network stability, and implement a fully redundant remote location (stub site); yet another very common design requirement that is not documented anywhere.
Introduction to EIGRP Stub Routers
Let’s start with an easy example: a central site router linked to a large number of remote offices over slow speed or unreliable links. The WAN network could be implemented with Frame Relay, Carrier Ethernet or DMVPN; the scaling challenges of EIGRP remain the same regardless of the underlying WAN technology.
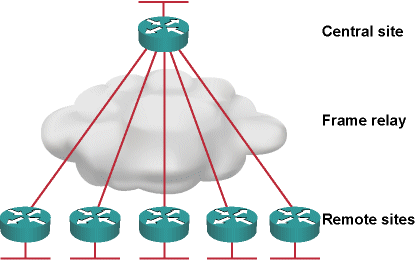
Simple hub-and-spoke WAN network
Each time a single remote office becomes unreachable, the central site router starts the Diffusing Update Algorithm (DUAL) process, querying all other remote office routers to determine whether they might have a better path to the lost destination:
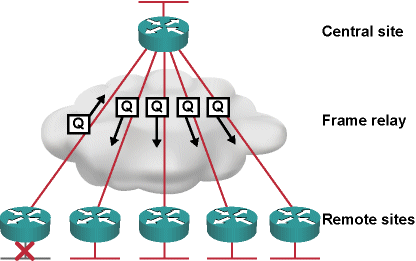
DUAL query process in the hub-and-spoke network
As the remote offices have no connectivity apart from their upstream link, these queries are obviously a waste of bandwidth and processing power. Even worse, in larger networks they might cause a Stuck-in-Active (SIA) event, potentially bringing down an EIGRP adjacency between core routers, thus resulting in a massive network blackout (SIA events are a major cause of network outages in poorly designed EIGRP networks).
The EIGRP stub router functionality, introduced in IOS release 12.0(7)T, gives you exactly what its name implies – the ability to declare a remote office router as a stub router (a router with no further connectivity):
- A stub router is a non-transit router: will not advertise routes received from an EIGRP neighbor to another EIGRP neighbor.
- Other EIGRP routers will not query stub routers during the DUAL process
You configure a stub router with the eigrp stub [ connected | static | redistributed | summary | receive-only ] router configuration command. Apart from the receive-only option, which prevents the stub router from announcing any routes (not really useful), the other keywords define which routes inserted into the EIGRP routing process from other sources the router should announce to its neighbors.
In our example, the remote office routers have no external connectivity, so they just need to announce connected routes. Here are the relevant configuration commands needed to transform a remote office router into an EIGRP stub router:
router eigrp 1
eigrp stub connected
The EIGRP stub routers announce their status in a new TLV (type-length-value triple) in the EIGRP hello messages. If their neighbors understand the new TLV, they stop sending queries to the stub router; instead the queries are responded to with the inaccessible message (infinite reply), while the stub routers get notified about the change with an infinite update message. This results in improved convergence time as the core routers don’t have to wait for query responses from the remote offices.
Routers running an IOS release older than 12.0(7)T simply ignore the new TLV. They would thus still query the stub routers, but the stub routers would reply immediately without propagating the query (still resulting in marginally improved performance in meshed networks).
You can check whether an EIGRP neighbor is a stub router with the show ip eigrp neighbor detail command. The printout generated on our core router is displayed in the following listing.
a1#show ip eigrp neighbors detail
IP-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 172.16.1.33 Se0/0/0.401 11 00:01:03 1031 5000 0 9
Version 12.4/1.2, Retrans: 0, Retries: 0, Prefixes: 1
Stub Peer Advertising ( CONNECTED ) Routes
Suppressing queries
1 172.16.1.2 Se0/0/0.100 10 00:03:32 753 4518 0 4
Version 12.4/1.2, Retrans: 0, Retries: 0, Prefixes: 2
Stub Peer Advertising ( CONNECTED ) Routes
Suppressing queries