VXLAN and OTV: The Saga Continues
Randall Greer left a comment on my Revisited: Layer-2 DCI over VXLAN post saying:
Could you please elaborate on how VXLAN is a better option than OTV? As far as I can see, OTV doesn't suffer from the traffic tromboning you get from VXLAN. Sure you have to stretch your VLANs, but you're protected from bridging failures going over your DCI. OTV is also able to have multiple edge devices per site, so there's no single failure domain. It's even integrated with LISP to mitigate any sub-optimal traffic flows.
Before going through the individual points, let’s focus on the big picture: the failure domains.
The Big Picture
Fact: layer-2 network (VLAN) is a single failure domain. You might not believe it… until you experience your first STP-induced loop or a broadcast storm (but then, there are people who believe in bandwidth fairy and flat earth).
Now let’s compare the bridging domains in three scenarios:
- VXLAN VTEP on the hypervisor
- VXLAN VTEP on the first ToR switch
- VXLAN VTEP or OTV at the WAN edge router.
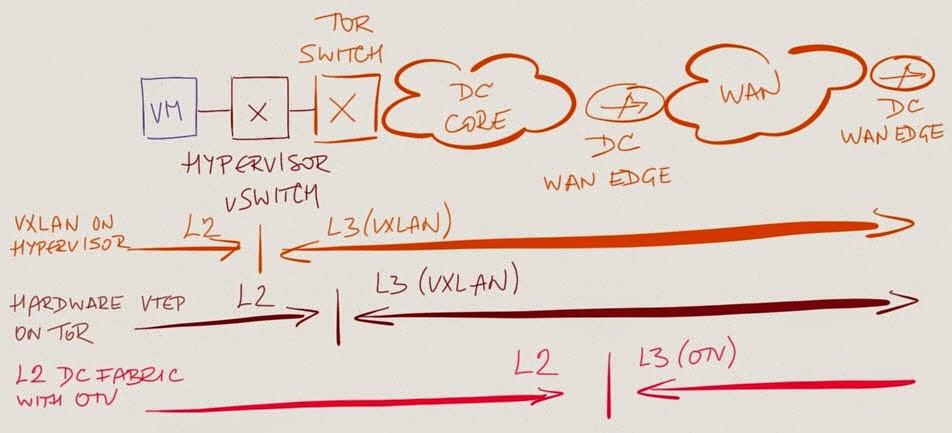
When you place the tunnel encapsulation endpoint on the WAN edge router, you turn at least one data center into a single failure domain. With the VXLAN on the hypervisor, the failure domain is limited to all hypervisors participating in the same VLAN, and if the hypervisor uses packet replication to emulate BUM flooding, a VM-triggered broadcast storm cannot do too much damage. The proof is left as an exercise for the reader.
The Details
Now let’s go through Randall’s points:
OTV doesn’t suffer from traffic tromboning. You might solve northbound (DC-to-WAN) traffic flow in OTV scenario with first-hop gateway localization (which is a kludge that shouldn’t have existed). You won’t even start solving southbound traffic flow problems until you introduce LISP, and the solution will be suboptimal until you deploy LISP at remote sites.
You cannot solve east-west tromboning (traffic between VMs in different data centers), and all your glorious ideas kick the dust the moment someone inserts a stateful appliance (firewall or load balancer) in the forwarding path… unless you plan to deploy stretched firewall cluster, in which case I’ll wish you luck and walk away in disgust.
TL&DR: Stop being a MacGyver and get a life. You might also want to watch this video.
You’re protected from bridging failures going over your DCI. This assumes that I’m OK with bridging failures bringing down one of my data centers. I don’t have a dozen data centers, so I don’t want to risk even one of them.
Also, if a VM goes broadcast-crazy and pumps 10Gbps of BUM traffic into your data center core, the OTV solution will either (A) saturate the WAN link or (B) saturate the server links in the other data center.
Before telling me that I don’t know what storm control is, please do read how it actually works. A single BUM-crazy VM will kill almost all BUM traffic on your OTV link, effectively breaking ARP (and a few other things) across stretched VLANs.
OTV is also able to have multiple edge devices per site, so there's no single failure domain. Single point of failure is not the same thing as single failure domain.
OTV is even integrated with LISP… and you get optimal southbound traffic flow only when you deploy LISP on all remote sites, which is still a stretch BHAG for the global Internet.
http://blog.ipspace.net/2012/03/stretched-layer-2-subnets-server.html
It is, however, more lucrative from vendors' or system integrators' perspective to sell more boxes (or more complex boxe) to the customer than telling them that they should fix their apps.
It will just take a while longer in some environments than others.
But of course just you can do it does not mean you should do it. DCI link failures might cause more issue than what ot would solve.
Also for the OTV edge devices ,what I would say to this commenter in addition to your excellent and meaningful response :) , although they are not single point of failure , they can not be used in load share scenario due to how it works to avoid forwarding loop. So the convergence time needs to be considered and maybe adjusted and also odd/even Vlan separation needs to be arranged carefully for multihoming ( Management complexity.! ).
You are only protected whilst nothing has failed. It doesn't matter what protocol/technology/features you are using, or what protection mechanisms you have in place. A faulty supervisor module can quite easily identify your single failure domain, I speak from experience ;)
http://www.h3c.com/portal/download.do?id=1798081
http://enterprise.huawei.com/ilink/cnenterprise/download/HW_341904
With OTV and FHRP localization, you can definitively reduce the tromboning effect for E-W traffic (inter-tier Apps workflows) without the need to deploy LISP IP mobility or other southbound optimization services. The Layer 3 gateway of interest is active on each site thus the traffic between application tiers is contained inside each DC without hair-pining workflows across sites. This is currently challenging with VXLAN alone.
With OTV, the UU are not flooded. And storm-control configuration is simplified, because of failure isolation functionality natively available with OTV (for broadcast and unknown unicast). Thus a VM with a 10GE throughput that becomes "broadcast-crazy" should not impact the secondary site if the right tools are implemented accordingly. This is not completely true with VXLAN unfortunately, and it might be very challenging to rate limit an IP Multicast group. As the result with the current implementation of VXLAN with no control plane, the failure domain is extended throughout the whole VXLAN domain with a huge risk to saturate the DCI links and impacting the remote sites.
Note that if VXLAN requires an IP multicast network intra-DC which may be accepted by the enterprise, it would also impose IP multicast enabled for inter-DC network, which might be more challenging for the enterprise and/or the SP managing the inter-site IP network.
OTV in conjunction with LISP IP mobility and FHRP localization offers a real optimization for long distances between DC’s. When LISP IP mobility is deployed with extended subnets, it is complementary to OTV but is not mandatory. It is a smart choice that the network mgr will take based on how the high latency induced by the long distances may impact the enterprise business. Anyhow, for most of enterprises deploying DCI, the WAN access network is an Intranet network where LISP is easy to deploy and rarely a global Internet core per se.
What is said today may be a bit different in the future. Solutions for distributed virtual DC are evolving in order to improve sturdiness, efficiency and optimization, including FW clustering stretched across multiple locations. It is important for enterprises to pay attention to this fast evolution.
Finally long story short, it is certainly worth reading the detailed posts I made that discuss about the current VXLAN release and DCI, including LISP mobility and other FW clustering articles.
26 – Is VxLAN a DCI solution for LAN extension ?
http://yves-louis.com/DCI/?p=648
23 – LISP Mobility in a virtualized environment
http://yves-louis.com/DCI/?p=428
27 – Stateful Firewall devices and DCI challenges
http://yves-louis.com/DCI/?p=785
Thanks for an extensive reply. We agree on quite a few topics, and will have to agree to disagree on a few others.
First a nit: most overlay virtual networking implementations no longer require multicast, the only exception being vShield suite (which is a zombie anyway).
More importantly, you haven't addressed my major concern: OTV requires a DC-wide bridging domain because it sits at the edge of a data center (and I will defer the LISP discussion for some other time ;).
Finally, while I understand your excitement regarding the long-distance ASA cluster, do tell me what happens when the DCI link fails?
Kind regards,
Ivan
Let me split the answers in 3 different replies, otherwise it seems that the whole response is too long
/
Thank you Ivan for the fast reply. Let me give you here my thoughts. Please note that I’m replying to the comments made previously only, but several other requirements to build a solid DCI are described in the post I mentioned above.
Ivan>> First a nit: most overlay virtual networking implementations no longer require multicast, the only exception being vShield suite (which is a zombie anyway).
yves >> yes and no :) - But this point is crucial.
From a software-based VXLAN point of view, there are indeed several vendors who already offer unicast-only mode.
From a ToR-based VXLAN point of view, as far as I’m aware, most of vendors are still enabling VXLAN in Multicast mode (TBC).
We will certainly comeback in the near future to this last statement, but as I said things are moving quickly however I’m talking about what is available today.
Back to the software-based VXLAN. Leaving aside discussions on scalability and performances, no one wants/can deploy a fully virtual environment, it's always an hybrid network with communication with traditional platforms, hence we need VTEP Gateway (L2) for the VLAN ID <=> VNI mapping. Unfortunately, currently only one single active L2 gateway per VXLAN domain is supported in software-based VTEP. Thus the reason I left aside the software-based solution although it offers unicast-only mode. If that assumption is correct, then the software-based VXLAN cannot be a DCI solution as I explained in these posts below.
In short, if we want to extend a set of VLAN across 2 or more locations using VXLAN as the DCI protocol transport with only one L2 gateway that exists for the whole VXLAN domain, how a remote VLAN to be extended can hit the active L2 gateway. The ToR-based VXLAN can support today distributed active L2 gateways but does not offer currently a CP for the distribution and learning process.
26 – Is VxLAN a DCI solution for LAN extension?
http://yves-louis.com/DCI/?p=648 and
26-bis – VxLAN VTEP GW: Software versus Hardware-based
http://yves-louis.com/DCI/?p=742
yves >> OTV is very flexible and actually it can sit at the aggregation PoD's if we wish, where the L2/L3 boundary exists (maintaining the DC core a pure L3 network). If we look at the evolution of the network fabric, VXLAN intra-DC is one solution. We can contain the failure domain inside the ToR, extend the VLAN intra-DC using a VXLAN overlay from the ToR leaf and terminate the VXLAN tunnel at the DCI layer, and finally map the original VLAN to the OTV overlay for example, hence the bridging domain keeps limits to the access PoD and not widely spread across the whole DC infrastructure.
VLAN ⇐ToR_VTEP⇒ VXLAN ⇐Core_VTEP⇒ VLAN ⇐DCI_OTV⇒
yves>> This is a fair comment. Actually there are two levels of LAN extension when deploying Act/Act FW clustering stretched across multiple locations, one level for the ASA clustering (extending the cluster control link) and one level for the Apps and user data (traditional DCI), obviously all redundant network connections for a resilient solution must exist, but let’s assume the DCI dies.
The key components are that 1st of all, all FW appliances are active and secondly there is a way to control dynamically the direction In & Out to the right DC supporting the Apps of interest.
Hence the best is a combination of ASA clustering stretched across two sites (using a single cluster control plane) with the LAN extension (such OTV offering stateful “hot” live migration), in conjunction with LISP IP mobility (ingress redirection) and FHRP localization (egress redirection).
If the DCI breaks, we will get a split brain like for any other clusters. But the main difference is that with the ASA clustering, all FW appliances (phy or virtual) are active, and thanks to LISP IP mobility and FHRP isolation, the traffic will follow the location of the apps per site and will stay stuck to the site where the apps resides as it will not be possible to address hot live migration anymore. However Disaster Recovery with cold migration should be supported. Both DC becomes two active independent DC’s while the same security rules will remain intact on both sites, but now with two FW control planes.
More to read in this article
27 – Bis – Path Optimisation with ASA cluster stretched across long distances – Part 2
http://yves-louis.com/DCI/?p=856