vCider: A Hammer Looking For a Nail?
Last week Juergen Brendel published an interesting blog post describing how you can use vCider to implement high-availability clusters with multi cloud strategy, triggering the following response from one of my readers: “I hadn't heard of vCider before but seeing stuff like this always makes me doubt my sanity – is there really a situation where the only solution is multi-site L2?”
A short diversion
Before someone starts accusing me of being a grumpy L3 grunt, let me point out that I was probably the first one blogging about the technical details of vCider (triggering an interesting response from a very experienced server admin). The vCider solution is also described in more details in my Cloud Computing Networking webinar.
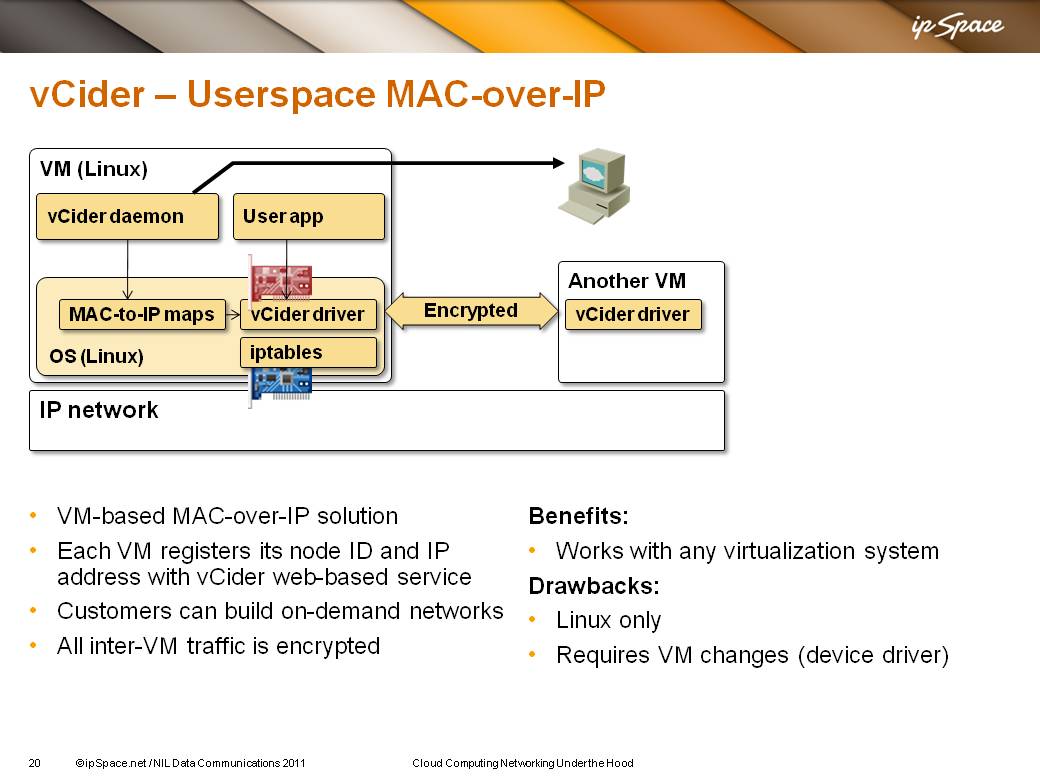
The vCider solution is definitely worth considering if you need private connectivity between VMs running in different clouds – it’s much easier to use something like vCider than to build a full mesh of VPN tunnels. However, just because you have a hammer doesn’t mean that every problem is a nail.
Back to Multi-cloud high-availability scenario
Juergen described the following scenario (please do read his blog post for details):
- You’re running a high-availability enterprise service in the IaaS cloud;
- Service VMs are deployed in two different cloud environments to provide resiliency against cloud provider failure;
- The service is accessed from your enterprise network through a gateway server that has a physical (or virtual) NIC in your network and a vCider virtual interface;
- Linux heartbeat (IP address sharing based on L2 tricks like Gratuitous ARP) is used to implement the HA cluster.
What’s wrong with the HA idea?
Cloud provider failure is the least probable failure. Amazon failures always provide sensationalist headlines to IT yellow press, but it’s more likely something else will fail first ... like the network connectivity, which will immediately lead to split-brain cluster. Stretched cluster were never a good idea and wrapping them in a cozy cloud blanket doesn’t make them any better.
What about storage? The networking nerds tend to ignore the storage issues (because storage is not funny), but high availability clusters work well only if the servers have access to the same data. How will you implement data replication between two cloud providers? You could use an application-layer solution that makes sense (like database replication, mirroring or log shipping), but then you probably don’t need HA cluster functionality (because the application can take care of itself).
Ever heard of load balancers? Layer-2 HA clusters are needed in environments where the clients have to access the servers directly (thus requiring IP address migration between servers). In most cases, load balancers are a better choice, and they allow you to implement active/active designs (should your application happen to support them).
In the particular scenario described by Juergen it would be much simpler to achieve the goals he stated with a load balancer (because his scenario already has a gateway server between clients and vCider subnet), and there are plenty of open-source solutions available if you can’t afford to buy a commercial product to support your high-availability application ... but then you wouldn't need vCider.
Not everyone is a layer-2 fan
Fortunately, not everyone is a layer-2 fan. Quick Google search returned wealth of Linux high availability solutions, none of the requiring L2 connectivity between servers. Here are just a few of them:
- Linux Virtual Server uses a front-end load balancer. Back-end can be implemented with any clustering technology (including Linux-HA).
- Linux-HA uses heartbeat to implement the cluster messaging layer and heartbeat runs on UDP/IPv4 (you might need layer-2 if you want to use broadcast UDP, but there are always other options).
Summary
I still haven’t seen a viable (let alone robust) scenario that would require stretched layer-2 subnets. Linux clusters definitely don’t need them (neither does the Microsoft’s Windows Server Failover Cluster). Long-distance layer-2 subnets make sense as a transport solution (VPLS and DMVPN come to mind), but not as an infrastructure for a HA cluster.
You don't need vCider? you don't need an Overlay Network? you mean Load-Balancing between public IP?
You are raising some good points there about the challenges of setting
up high availability clusters across network boundaries. Before I
comment on them, please note that lately we have started to blog about
some of our customers' applications and use cases. We are always
interested - sometimes even surprised - about the many different ways in
which people use vCider. Occasionally we just want to share a few of
those things on our blog.
Of course, that doesn't mean that vCider is limited to just those
particular applications. For example, for many of our customers it is
not even so much about L2 connectivity, but about the ability to manage
IP address space, replicate entire network topologies and of course
about security, which for many of them is one of our main features.
So, if you are asking about the 'nail', which the 'vCider hammer' is
looking for: You may be able to find other tools for all the different
nails you encounter, but our users find that vCider is a pretty good
hammer for many of the nails they need to deal with. Not just a single
nail.
When I wrote this particular blog about the IP address failover, I
thought I'd combine it with the example of the gateway to connect a
virtual network to the enterprise. Big mistake! Many people were thrown
off by that, since it ends up just distracting from the main point. And
you are right: In that particular example I described, a load balancer
would probably be the easier solution.
In hindsight now, to demonstrate the utility of IP address failover, I
think a much better example would have been the case where a larger
portion of the customer's network is in the cloud, some servers and also
some clients. If all of them are connected on a vCider network, then you
don't need to force traffic (from all clients to all servers) through a
load balancer somewhere (bottleneck, single point of failure, funny
shaped "traffic trombones", etc.). Instead, all clients instantly now
are informed about a server failover. That's exactly what Linux-HA can
do so well with a gratuitous ARP. With vCider you can now use this well
established solution even in your cloud networks.