Swimlanes, Read-Write Transactions and Session State
Another question from someone watching my Designing Active-Active and Disaster Recovery Data Centers webinar (you know, the one where I tell people how to avoid the world-spanning-layer-2 madness):
In the video about parallel application stacks (swimlanes) you mentioned that one of the options for using the R/W database in Datacenter A if the user traffic landed in Datacenter B in which the replica of the database is read-only was to redirect the user browser with the purpose that the follow up HTTP POST land in Datacenter A.
Here’s the diagram he’s referring to:
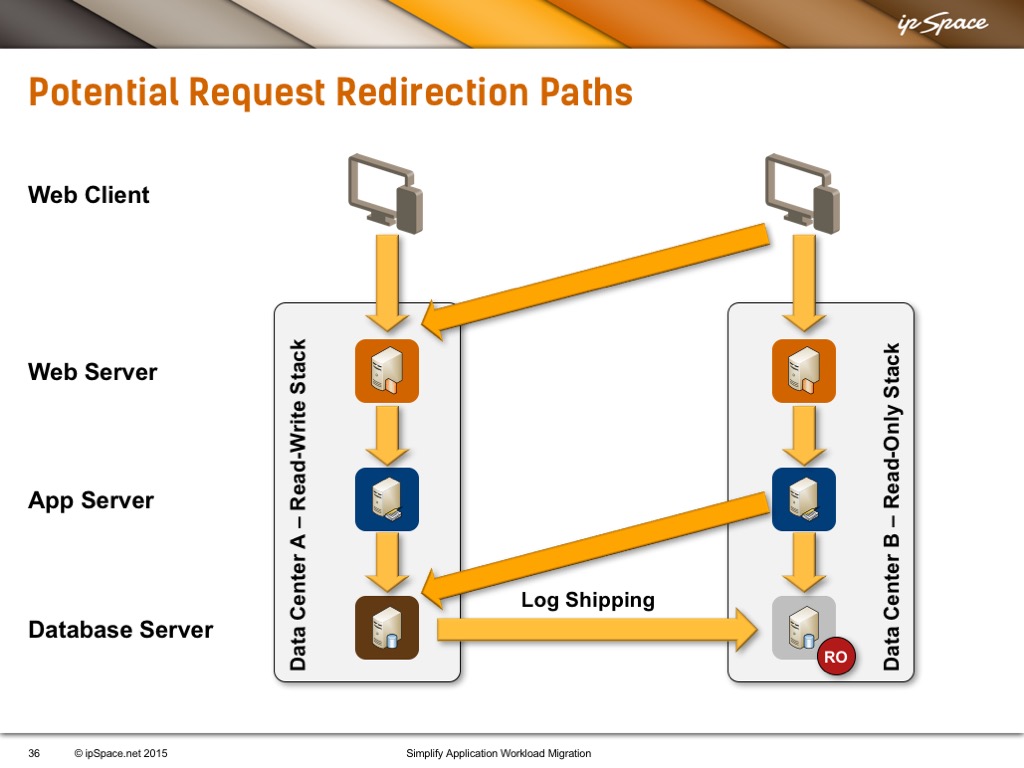
Just in case you’re wondering why someone would go for an architecture that seems complex: several people running e-commerce sites told me that they see more than 99% of read-only transactions. Also, expecting to get transactional consistency across multiple active-active data centers is a recipe for disaster (see also: CAP theorem).
Continuing with the question…
In that case wouldn't the Web/App servers in Datacenter A need to know the session already created for the user in Datacenter B Web/App servers?
Absolutely. They would need to:
- Recognize the session cookie (so the user doesn’t have to log in again) or use some other mechanism to authenticate user based just on user-supplied information (see Kerberos);
- Have access to the data needed for R/W transaction.
I would probably use an eventually consistent database (MongoDB, for example) to solve the second challenge, and assume that the user data (for example, shopping cart) arrives to DC-A before the user clicks the "Purchase" button. I would also put some simple checksum (or calculate a hash) of the data to verify it got there, or start the checkout process (review your shopping cart phase) in DC-A. Alternatively, you could process all “add to basket” transactions in DC-A so the data is already there (shipping a copy to DC-B in case DC-A fails).
Long story short:
- Try to make your solution as simple as possible, but not simpler;
- Solve the complexity on the application layer considering all potential failure scenarios (including user can see DC-A and DC-B, but they can’t see each other)
- Recognize that distributed systems always involve byzantine failures (see also this NASA document) and that sometimes the best thing you can do is to admit the failure to the user and ask her to recover instead of failing in obscure and undocumented ways.
Have you learned something new? Guess how much more you’d learn in Building Next-Generation Data Center online course ;)