MPLS Load Sharing – Data Plane Considerations
In a previous blog post I explained how load sharing across LDP-controlled MPLS core works. Now let’s focus on another detail: how are the packets assigned to individual paths across the core?
2014-08-14: Additional information was added to the blog post based on comments from Nischal Sheth, Frederic Cuiller and Tiziano Tofoni. Thank you!
The answer is trivial if you’re doing headend-based load sharing (example: using multiple MPLS TE tunnels) – the headend router has full visibility into the original MAC frame or IP packet and can do any type of load sharing it wants (from per-destination to per-session load balancing).
Load sharing at the LSP split point (in the network core) is trickier and mostly vendor-dependent. Let’s use the same sample network we used in the previous blog post to illustrate the difficulties. How will Label Switch Router (LSR) B decide which labeled packets with incoming label 1015 should go toward LSR C and which ones should go toward LSR D, if all it ever sees are the labeled packets?
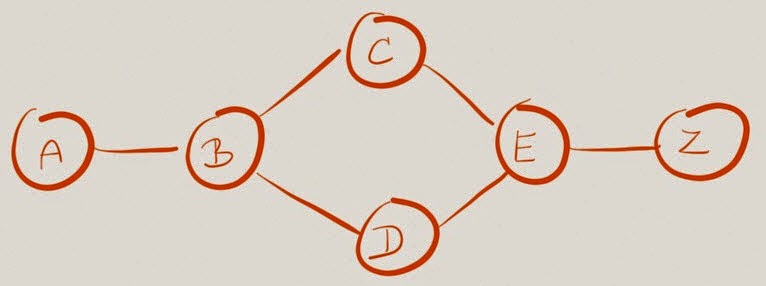
An LSR could perform the load balancing based on the next label in the stack, based on the last label in the stack, or based on the actual labeled payload. Unfortunately a transit LSR has no idea what the payload is – only the ingress and egress LSRs know what they agreed to use the LSP for.
Some implementations of transit LSRs look into the first nibble of the payload and treat the payload as IPv4 packet (using the load-sharing algorithm configured for unlabeled IPv4 packets) if the value in the first nibble is 0x04, and likewise treat the payload as IPv6 packet if the value in the first nibble is 0x06.
For in-depth discussion of MPLS load balancing on ASR 9000, read this document.
That approach works well for L3VPN traffic (where labeled IPv4 or IPv6 datagrams are transported across MPLS core), but fails miserably for non-IP traffic (example: L2VPN traffic, which has MAC header at the beginning of the payload).
The guesswork based on first nibble of the payload might incorrectly load balance EoMPLS traffic when the destination MAC address starts with 04 or 06. You can use the control word functionality of EoMPLS pseudowires to set the first nibble of the payload to zero.
Some L2VPN solutions (EoMPLS, VPLS, EVPN) use additional labels to enhance the load sharing behavior of the MPLS core. An ingress LSR using this approach collects the fields that it would use in its load sharing algorithm from the inbound packet, hashes them into a 20-bit value and adds that label to the bottom of the MPLS stack. A transit LSRs can then use the additional label to decide how to share the load across multiple outbound links going to the same destination.
The initial approach to enhanced load balancing of MPLS pseudowires uses a single Flow Label (defined in RFC 6391) and relies on LDP signaling between ingress and egress LSR to negotiate the use of flow label. A more generic approach uses a special entropy label indicator (ELI, label value 7, defined in RFC 6790) in the MPLS label stack to tell the egress LSR to discard the flow label (now called entropy label) following the ELI.
New to MPLS?
Check out my MPLS books and VPN webinars.
The L2 ECMP solution you've described is FAT PW, wherein an "entropy" label gets
pushed at the bottom of the label stack. Entropy Labels is a similar solution with broader scope i.e. it can be used for any payload. An ingress LER pushes an Entropy
Label and an Entropy Label Indicator (ELI) right before it pushes the Transport Label.
FAT PW: http://tools.ietf.org/html/rfc6391
Entropy Labels: http://tools.ietf.org/html/rfc6790
Broad adoption of the above RFCs should remove the need for arcane, platform dependent knobs to control MPLS transit load sharing behavior.
https://supportforums.cisco.com/document/111291/asr9000xr-loadbalancing-architecture-and-characteristics
There is also a draft for segment routing using a smilar label, although where that label is placed can be in a number of different places - http://tools.ietf.org/html/draft-kini-mpls-entropy-label-src-stacked-tunnels-01
The problem is, if it's a L2VPN between HQ and a branch, the src-dst-mac pair will always be the same, and no load sharing would happen!
Starting from IOS-XE 3.11 (As I remember), you can configure the L2VPN using the interface psudowire context, and you can configure ECMP based upon src-dst-ip address.
Regards
mk