FCoE and Nexus 1000v QoS
One of my readers wanted to deploy FCoE on UCS in combination with Nexus 1000v and wondered how the FCoE traffic impacts QoS on Nexus 1000v. He wrote:
Let's say I want 4Gb for FCoE. Should I add bandwidth shares up to 60% in the nexus 1000v CBWFQ config so that 40% are in the default-class as 1kv is not aware of FCoE traffic? Or add up to 100% with the assumption that the 1kv knows there is only 6Gb left for network? Also, will the Nexus 1000v be able to detect contention on the uplink even if it doesn't see the FCoE traffic?
As always, things aren’t as simple as they look.
Background: adapter FEX and FCoE
The UCS Ethernet adapters implement FCoE in hardware – the operating system doesn’t know it deals with a single physical adapter with a single set of 10GE uplinks. Each physical 10GE adapter appears as (at least) two PCI adapters: a 10GE Ethernet NIC and a Fiber Channel Host Bus Adapter (HBA).
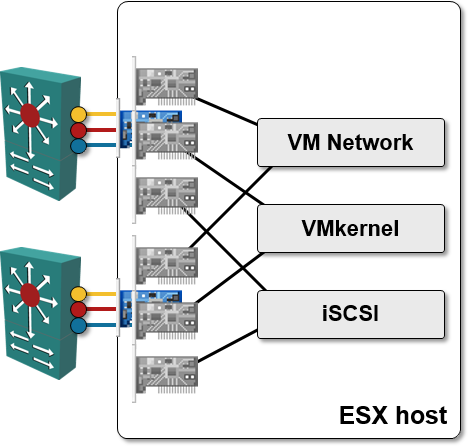
The bandwidth allocation and queuing on the physical 10GE uplink is hidden from the NICs presented to the operating system. The operating system thinks it deals with multiple full-blown 10GE/FC interfaces, and it just happens that the interfaces transmit packets from the hardware TX-ring slower than one would expect… but then you could get the same results using PAUSE frames (or PFC) on a dedicated 10GE interface.
Output queuing on Nexus 1000v
Output queuing on Nexus 1000v works the same way as any other output queuing implementation: the interface driver enqueues the output packets into the hardware TX-ring until the TX-ring reaches a preset length, at which point the software queuing (CBWFQ) starts.
The interface driver doesn’t need to know the exact interface bandwidth, all it needs to know is when the TX ring is below the low watermark (at which point packets are dequeued from the CBWFQ queues and moved to the TX ring). The bandwidth percentages specified in the CBWFQ affect the relative amount of data transferred from each individual class queue; they work equally well regardless of the physical interface speed or its actual throughput.